




开篇
在本系列的前面几期中,我们介绍了包含决策树及其相关算法在内的一系列有监督学习算法。本期不妨换换口味,学习一种比较简单的无监督学习算法:k-means
.
k-means 算法理论讲解
你可能已经听说过这个算法,没有也不要紧,它的原理并不复杂,让我们来看看~
给你一批样本的数据,就像这样:
其中不同的id
代表不同样本,共10
个样本。x
和y
是两个特征,每一个样本都有且只有这两个特征。
现在希望你能够对这些样本进行分类。
我们知道,在属于有监督学习的分类问题中,训练数据往往会包含类别标签。而上面这份数据本身是不含标签的,所以这并不是一个分类问题。
既然不知道类别标签,你又让我对这些样本进行分类,那如何聚类?又要聚成几类呢?
其实,在k-means
中,最终聚成几类是由我们自己决定的;这里的类别标签通常用数字表示,如0,1,2等;当我们指定好类别总数后,每一个样本被归到哪一类,就需要聚类算法自己去学习了。
k-means
算法学习将相似的样本聚在一起,称为一个类别(也称为一个"簇"),而将不相似的样本划分到不同的类别("簇")中。
这里的相似程度,通常是用样本之间的距离来度量的,比如最常用的欧氏距离。
啰嗦了这么多,k-means
算法的执行步骤可以总结如下:
(1) 对于给定的一批样本,初始化聚类中心(这里需要手动指定聚成几类),初始化每个样本所属簇;
(2) 对于每一个样本,分别计算该样本与所有聚类中心之间的距离,选择距离该样本最近的聚类中心作为该样本所属簇;
(3) 经过(2)之后,每个样本所属簇就被更新了,现在来更新聚类中心:计算每一个簇内所有样本在所有特征维度上的平均值,将其作为该簇新的聚类中心。
(4) 重复(2)、(3)若干次,便完成了聚类。
接下来,我们将根据以上四步,用Python实现k-means
算法。
k-means 算法的Python实现
我们需要手动指定要聚成几类,这里用参数k
来表示,比如k=3
就代表我们希望聚成3类。
data
是训练数据,毫无疑问也是需要手动传入的。
另外,我们还设置了一个是否随机打乱样本顺序的开关:do_shuffle
,默认保持样本原序。
class MyKmeans:
def __init__(self,k,data,do_shuffle=False):
self.k=k#自己指定聚成几类
self.data=data#训练数据
self.do_shuffle=do_shuffle#是否随机打乱样本顺序
现在实现(1),即:初始化聚类中心,初始化每个样本所属簇。
这里,我直接以前k
个样本的坐标分别作为k
个初始聚类中心,并将每个样本的类别标签(所属簇)初始化为0。
def initialize(self):
if self.do_shuffle:
np.random.shuffle(self.data)
#初始化聚类中心
self.centers=self.data[:self.k]
#初始化每个样本所属簇
self.targets=np.zeros(self.data.shape[0])
再看(2),其中涉及到了求距离,所以先来实现两个样本点之间的距离计算方法,这里采用欧氏距离:
def cal_dist(self,p1,p2):
return np.sqrt(np.sum((p1-p2)**2))
然后来实现(2),即:更新样本所属簇
for i,item in enumerate(self.data):#对于每一个样本点
c=[]#分别计算该样本点到k个聚类中心的距离,并存入c
for j in range(len(self.centers)):
c.append(self.cal_dist(item,self.centers[j]))
#print(c)
self.targets[i]=np.argmin(c)#更新targets
现在来实现(3),即:更新聚类中心
#更新聚类中心
new_centers=[]
for i in range(self.k):#对于每一个类中的全部样本点
#此时target的取值集合是0到k-1
#挑选出属于簇i的全部样本
i_data=[]
for index,item in enumerate(self.data):
if self.targets[index]==i:
i_data.append(item)
if len(i_data)!=0:
cent=[]#存储新的聚类中心的每一个维度
for p in range(len(self.data[0])):#对于点的每一个维度
sums=0
#计算第i个簇中,每个维度的新值
for x in i_data:
sums+=x[p]
res=sums/len(i_data)
cent.append(res)
new_centers.append(cent)
else:
new_centers.append(self.centers[i])#若某一个簇中所含样本数为0,则不更新该簇的中心点
self.centers=new_centers
注意这里需要判断某个簇中所含样本个数是否为0,因为当样本数为0时,上述代码中求解均值所做的除法会报错。
为了避免这个错误,当出现这种情况时,我们选择本次不更新该簇的聚类中心。
以上便完成了(2)和(3),注意到(4)中需要重复(2)和(3)这两个步骤,因此,我们可以将(2)和(3)封装到一个方法里面,就像这样:
def one_step(self):
for i,item in enumerate(self.data):#对于每一个样本点
c=[]#分别计算该样本点到k个聚类中心的距离,并存入c
for j in range(len(self.centers)):
c.append(self.cal_dist(item,self.centers[j]))
#print(c)
self.targets[i]=np.argmin(c)#更新targets
#更新聚类中心
new_centers=[]
for i in range(self.k):#对于每一个类中的全部样本点
#此时target的取值集合是0到k-1
#挑选出属于簇i的全部样本
i_data=[]
for index,item in enumerate(self.data):
if self.targets[index]==i:
i_data.append(item)
if len(i_data)!=0:
cent=[]#存储新的聚类中心的每一个维度
for p in range(len(self.data[0])):#对于点的每一个维度
sums=0
#计算第i个簇中,每个维度的新值
for x in i_data:
sums+=x[p]
res=sums/len(i_data)
cent.append(res)
new_centers.append(cent)
else:
new_centers.append(self.centers[i])#若某一个簇中所含样本数为0,则不更新该簇的中心点
self.centers=new_centers
有了上面实现的这些方法,第(4)步的实现就很简单啦,直接来个for
循环即可
def run(self,iterations):
self.initialize()#初始化聚类中心和各样本所属类别
#经过iterations次迭代,基本就完成了聚类
for it in range(iterations):
#print('iterations',it)
self.one_step()
return self.centers,self.targets
到这里,我们就完成了整个k-means
算法,是时候测试一下效果了。
我们的训练数据是随机生成的,共100个样本,每个样本含2个特征。
import matplotlib.pyplot as plt
import numpy as np
if __name__ == '__main__':
datasets=np.random.randint(0,100,size=(100,2))
k=4#聚类数
iterations=100#总迭代次数
mykmeans=MyKmeans(k,datasets,True)#实例化
centers,targets=mykmeans.run(iterations)#迭代求解
#可视化聚类结果
plt.scatter(datasets[:,0],datasets[:,1],c=targets)
for center in centers:
plt.scatter(center[0],center[1],marker='*',s=300)
plt.text(center[0], center[1], (round(center[0],2),round(center[1],2)), fontsize=10, color = "r")
plt.show()
聚类结果如下图所示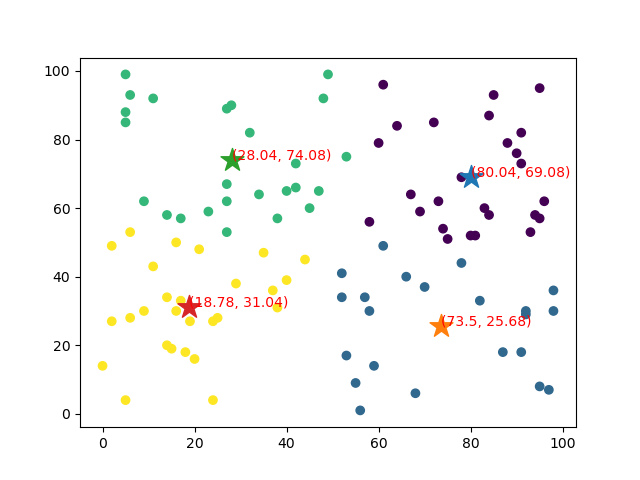
现将完整的k-means
实现代码汇总如下:
import numpy as np
class MyKmeans:
def __init__(self,k,data,do_shuffle=False):
self.k=k
self.data=data
self.do_shuffle=do_shuffle
#计算欧氏距离
def cal_dist(self,p1,p2):
return np.sqrt(np.sum((p1-p2)**2))
#初始化聚类中心和每个样本所属类别
def initialize(self):
if self.do_shuffle:
np.random.shuffle(self.data)
#初始化聚类中心
self.centers=self.data[:self.k]
#初始化每个样本所属簇
self.targets=np.zeros(self.data.shape[0])
def one_step(self):
for i,item in enumerate(self.data):#对于每一个样本点
c=[]#分别计算该样本点到k个聚类中心的距离,并存入c
for j in range(len(self.centers)):
c.append(self.cal_dist(item,self.centers[j]))
#print(c)
self.targets[i]=np.argmin(c)#更新targets
#更新聚类中心
new_centers=[]
for i in range(self.k):#对于每一个类中的全部样本点
#此时target的取值集合是0到k-1
#挑选出属于簇i的全部样本
i_data=[]
for index,item in enumerate(self.data):
if self.targets[index]==i:
i_data.append(item)
if len(i_data)!=0:
cent=[]#存储新的聚类中心的每一个维度
for p in range(len(self.data[0])):#对于点的每一个维度
sums=0
#计算第i个簇中,每个维度的新值
for x in i_data:
sums+=x[p]
res=sums/len(i_data)
cent.append(res)
new_centers.append(cent)
else:
new_centers.append(self.centers[i])#若某一个簇中所含样本数为0,则不更新该簇的中心点
self.centers=new_centers
def run(self,iterations):
self.initialize()#初始化聚类中心和各样本所属类别
#经过iterations次迭代,基本就完成了聚类
for it in range(iterations):
#print('iterations',it)
self.one_step()
return self.centers,self.targets
长按即可关注我们

原创不易,感谢你的每一次点赞与分享!
