




Transformer的结构
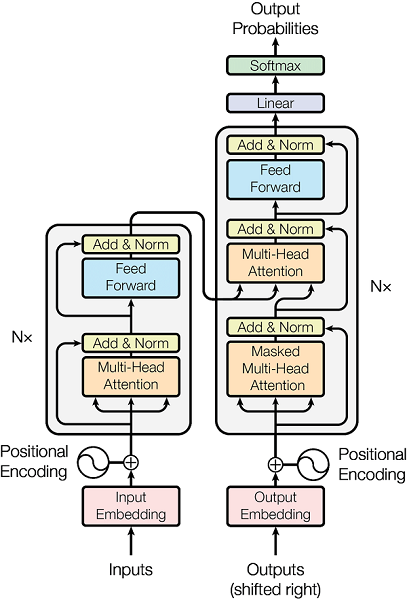
Transformer
的结构如上图所示,我们将其拆解为若干小部分,逐个部分用代码实现,然后再将各个部分联结起来,形成最终的Transformer
。
关于Transformer
的原理,网上已经有很多优质的文章了,这里我们关心其代码实现。对于其每一个子模块(以类的形式定义),我们都会实例化一个对象,用具体的数值代入其中,把中间过程中产生的变量维度及相关信息打印出来,这些都体现在代码注释中,请留意。
Muti-Head Attention
Muti-Head Attention
接收输入q,k,v
,维度在这里都是,输出维度也是。
q
和k
的维度是一致的,而v
可以和它们不一致,这里只是为了方便才将三者维度保持一致。
SelfAttention
实现代码如下 (注意注释)
#自注意力模块
#输入:q,k,v,mask.
#输出:out
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size#编码后长度
self.heads = heads#注意力头数
self.head_dim = embed_size // heads#每个注意力头的维数
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
# q,v,k
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)#heads * self.head_dim=embed_size,只是为了表述清晰
def forward(self, values, keys, query, mask):
print('query:',query.shape)# torch.Size([4, 3, 512])
# 训练样本总数
N = query.shape[0]
#print('N:',N)# 4
#print('values before:',values.shape)# torch.Size([4, 3, 512])
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
#print('value_len, key_len, query_len:',value_len, key_len, query_len)# 3 3 3
# 将embedding 切分为 self.heads 个不同的部分(在后两个维度做了reshape)
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
query = query.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values) # (N, value_len, heads, head_dim)
#print("values after rshape:",values.shape)# torch.Size([4, 3, 2, 256])
keys = self.keys(keys) # (N, key_len, heads, head_dim)
queries = self.queries(query) # (N, query_len, heads, heads_dim)
#爱因斯坦求和法,事实上就是在做矩阵乘法
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
# queries shape: (N, query_len, heads, heads_dim),
# keys shape: (N, key_len, heads, heads_dim)
# energy: (N, heads, query_len, key_len)
#print('energy:',energy.shape)# torch.Size([4, 2, 3, 3])
# Mask padded indices so their weights become 0
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
# Normalize energy values similarly to seq2seq + attention
# so that they sum to 1. Also divide by scaling factor for
# better stability
attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
# attention shape: (N, heads, query_len, key_len)
#print("attention:",attention.shape)# torch.Size([4, 2, 3, 3])
#print('attention *values',torch.einsum("nhql,nlhd->nqhd", [attention, values]).shape)# torch.Size([4, 3, 2, 256])
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
#print('out before:',out.shape)# torch.Size([4, 3, 512])
# attention shape: (N, heads, query_len, key_len)
# values shape: (N, value_len, heads, heads_dim)
# out after matrix multiply: (N, query_len, heads, head_dim), then
# we reshape and flatten the last two dimensions.
out = self.fc_out(out)# torch.Size([4, 3, 512])
# Linear layer doesn't modify the shape, final shape will be
# (N, query_len, embed_size)
return out
实例化:
embed_size
:编码后维度
heads
:注意力头数
注意在Pytorch中,nn.Linear
层的输入可以是多维的,举个例子:
TransformerBlock
也可以称为EncoderBlock
。
TransformerBlock
实现如下:
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout, forward_expansion):
super(TransformerBlock, self).__init__()
self.attention = SelfAttention(embed_size, heads)
#print('embed_size, heads:',embed_size, heads)# 512 2
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size),
)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query, mask):
#计算注意力分布
attention = self.attention(value, key, query, mask)#[4, 3, 512]
#print('attention:',attention.shape)# torch.Size([4, 3, 512])
# Add skip connection, run through normalization and finally dropout
x = self.dropout(self.norm1(attention + query))#[4, 3, 512]
forward = self.feed_forward(x)#[4, 3, 512]
out = self.dropout(self.norm2(forward + x))#[4, 3, 512]
return out
若干个TransformerBlock
连接在一起组成Encoder
。
实例化:
Encoder
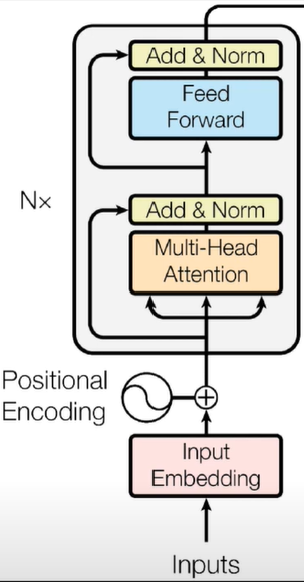
将位置信息和输入分别编码,再相加,得到的结果送入堆叠的TransformerBlock
,就得到了Encoder
,具体实现如下:
class Encoder(nn.Module):
def __init__(
self,
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length,
):
super(Encoder, self).__init__()
self.embed_size = embed_size
self.device = device
self.word_embedding = nn.Embedding(src_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList(
[
TransformerBlock(
embed_size,
heads,
dropout=dropout,
forward_expansion=forward_expansion,
)
for _ in range(num_layers)
]
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
#print('x:',x.shape)# torch.Size([3, 100])
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
#print('positions:',positions.shape)# torch.Size([3, 100])
out = self.dropout(
(self.word_embedding(x) + self.position_embedding(positions))
)
#print('out:',out.shape)# torch.Size([3, 100, 512])
# In the Encoder the query, key, value are all the same, it's in the
# decoder this will change. This might look a bit odd in this case.
for layer in self.layers:
out = layer(out, out, out, mask)
#print('out after :',out.shape)# torch.Size([3, 100, 512])
return out
实例化:
Decoder

与Encoder
类似,Decoder
主要组成是多个DecoderBlock
的堆叠,DecoderBlock
结构如下: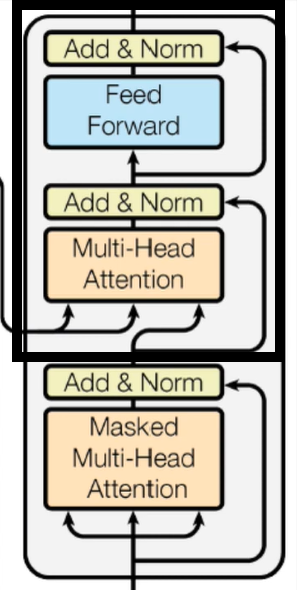
其中被框起来的可以看作是一个TransformerBlock
,这个在前面已经实现了,所以只需实现下面的那一部分就可以了。
注意从下面右方连接到上面的箭头,它借鉴了残差的思想,做了一个Skip Connection
。
DecodrBlock
完整实现如下:
class DecoderBlock(nn.Module):
def __init__(self, embed_size, heads, forward_expansion, dropout, device):
super(DecoderBlock, self).__init__()
self.norm = nn.LayerNorm(embed_size)
self.attention = SelfAttention(embed_size, heads=heads)
self.transformer_block = TransformerBlock(
embed_size, heads, dropout, forward_expansion
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, value, key, src_mask, trg_mask):
attention = self.attention(x, x, x, trg_mask)
#print('DecoderBlock attention:',attention.shape)#torch.Size([2, 7, 512])
query = self.dropout(self.norm(attention + x))
#print('DecoderBlock query:',query.shape)#torch.Size([2, 7, 512])
out = self.transformer_block(value, key, query, src_mask)
#print('DecoderBlock out:',out.shape)#torch.Size([2, 7, 512])
return out
有了DecoderBlock
,就可以实现Decoder
了,它和Encoder
的实现代码类似,注意着对比学习:
class Decoder(nn.Module):
def __init__(
self,
trg_vocab_size,
embed_size,
num_layers,
heads,
forward_expansion,
dropout,
device,
max_length,
):
super(Decoder, self).__init__()
self.device = device
self.word_embedding = nn.Embedding(trg_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
#堆叠DecoderBlock
self.layers = nn.ModuleList(
[
DecoderBlock(embed_size, heads, forward_expansion, dropout, device)
for _ in range(num_layers)
]
)
self.fc_out = nn.Linear(embed_size, trg_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_out, src_mask, trg_mask):
#print('x:',x.shape)# torch.Size([2, 7])
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
#print('positions',positions.shape)#torch.Size([2, 7])
x = self.dropout((self.word_embedding(x) + self.position_embedding(positions)))
#print('x after mappping',x.shape)#torch.Size([2, 7, 512])
for layer in self.layers:
#v和k都用enc_out
x = layer(x, enc_out, enc_out, src_mask, trg_mask)
#print('x after DecoderBlock:',x.shape)# torch.Size([2, 7, 512])
out = self.fc_out(x)
#print('out:',out.shape)# torch.Size([2, 7, 8])
return out
实例化:
输入维度是,这是未编码的。经过Encoder
编码得到的enc_src
维度为,再经Decoder
解码得到的输出维度为。
Transformer
有了以上的组件,就可以将它们组合起来得到Transformer
了
class Transformer(nn.Module):
def __init__(
self,
src_vocab_size,
trg_vocab_size,
src_pad_idx,
trg_pad_idx,
embed_size=512,
num_layers=6,
forward_expansion=4,
heads=8,
dropout=0,
device="cpu",
max_length=100,
):
super(Transformer, self).__init__()
#编码器
self.encoder = Encoder(
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length,
)
#解码器
self.decoder = Decoder(
trg_vocab_size,
embed_size,
num_layers,
heads,
forward_expansion,
dropout,
device,
max_length,
)
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.device = device
#原数据的mask
def make_src_mask(self, src):
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
# (N, 1, 1, src_len)
#print('src_mask:',src_mask.shape)#torch.Size([2, 1, 1, 9])
#print('src_mask:',src_mask)
"""
src_mask: tensor([[[[ True, True, True, True, True, True, True, True, False]]],
[[[ True, True, True, True, True, True, True, True, True]]]],
device='cuda:0')
"""
return src_mask.to(self.device)
#目标数据的mask
def make_trg_mask(self, trg):
N, trg_len = trg.shape
#torch.tril返回一个张量,包含输入2D张量的下三角部分,其余部分设为0
trg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(
N, 1, trg_len, trg_len
)
#print('trg_mask:',trg_mask.shape)#torch.Size([2, 1, 7, 7])
#print('trg_mask:',trg_mask)
"""
trg_mask: tensor([[[[1., 0., 0., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0.],
[1., 1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 1., 0., 0.],
[1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1.]]],
[[[1., 0., 0., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0.],
[1., 1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 1., 0., 0.],
[1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1.]]]])
"""
return trg_mask.to(self.device)
def forward(self, src, trg):
src_mask = self.make_src_mask(src)
trg_mask = self.make_trg_mask(trg)
enc_src = self.encoder(src, src_mask)
#print('enc_src:',enc_src.shape)# torch.Size([2, 9, 512])
out = self.decoder(trg, enc_src, src_mask, trg_mask)
#out = self.decoder(trg, enc_src, None,None)
return out
实例化:
在Decoder
的例子中,decoder
传入的第一个参数是x
,而这里实例化的model
对应的Decoder
部分传入的第一个参数实际上是trg[:, :-1]
,它的维度是,因此最后的输出维度为。
代码链接:
https://github.com/aladdinpersson/Machine-Learning-Collection/tree/master/ML/Pytorch/more_advanced/transformer_from_scratch
南极Python交流群已经成立,扫码备注"加群"即可,快来!



求个在看
