




开篇
AdaBoost是一种提升(boosting)方法。
你可能听过“众人拾柴火焰高”这句话,提升方法的思想与这句话的思想颇有相似之处。
一个人拾到的柴火,只能维持小的火苗;但一群人一起拾柴,供给同一火堆,那么这个火堆终将燃起熊熊大火。
对于给定的训练集,单个分类器的分类能力可能并不算好;但如果同时训练一堆分类器,让分类器们一起做判断,那么分类结果将会比任何一个单独的分类器做分类都要好。
上面的单个分类器被称为“弱分类器”,若干个“弱分类器”联合起来,就得到了“强分类器”。
AdaBoost作为最具代表性的提升方法,自然也蕴含着这种集体智慧的思想。至于其具体细节,且往下看。
AdaBoost 算法
AdaBoost为训练集中每个样本设置一个可调整的权值,并且在每一轮训练结束后将被误分类的样本的权值加大,将被正确分类的样本的权值减小。这样被误分类的样本在下一轮分类时会更加受到关注。
假设经过了轮训练,则会得到个弱分类器(前提:不考虑弱分类器的误差率,这个后面会详细说)。将这个弱分类器通过加权求和(弱分类器分类能力相对越强,权值就越大)的方式联结起来,便得到了一个强分类器。
以上是AdBoost核心思想的文字描述,现在用数学语言定义AdaBoost算法的完整步骤:
对于训练集: ,其中,为训练集所含样本总数。
首先初始化训练集样本的权值分布为:
即一开始各个样本的权值是一样的。
接下来进入学习阶段:
设定训练轮数为,对于第轮,算法将做以下事情:
(1)使用具有权值分布的训练集进行学习,得到弱分类器,该弱分类器的预测值为1或者-1;
(2)计算在训练集上的误差率:
其中代表第轮训练时,第个样本的权值
是指示函数,当与不相等时返回1,否则返回0。由此看来,第个弱分类器的误差率其实就等于当前所有被误分类的样本的权值之和。
(3)计算第个分类器的系数:
该系数衡量了在最终的强分类器中所占比重。对数底数为。我们可以画图看一下(横轴)与(纵轴)的关系:
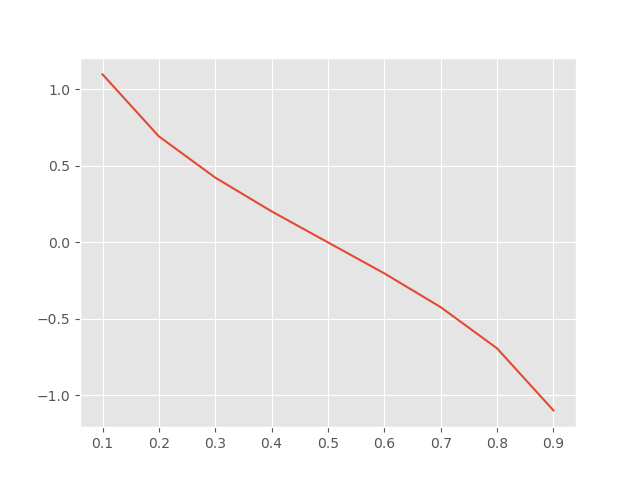
可以发现,当时,,且随着的减小而增大,这表明误差率越小的弱分类器在终极分类器中发挥的作用就越大。实际应用中,如果出现的情况,可以认为这个弱分类器实在太"弱"了,我随机猜测一个结果的正确率还是0.5呢!那还留着它干嘛,过年啊,果断丢弃!
(4)更新训练集权值分布:
其中分母起到了归一化的作用,保证了是一个概率分布。
分母对于每一个样本都是一样的。
对于一个比随机猜测好的弱分类器来说, 分子中的指数为,由于和的取值都是1或-1,因此当对于样本分类正确时,,此时 ,所以的权值在下一轮训练时将会减小。同理可得,对于分类出错的样本,在下一轮训练中该样本的权值会增大。
当训练完轮后,将每轮中弱分类器及其系数取出来,加权求和得到:
终极分类器就是:
其中, 是符号函数,传入值大于0返回1,小于0返回-1。1和-1正是类别标签的所有可能取值。
以上便是AdaBoost算法的全部步骤。
用 Python 实现 AdaBoost
这次使用的训练数据集如下:

是数据集唯一的特征,类别标签,拟使用AdaBoost算法训练一个分类器。
用pandas读入以上数据(后台回复'adaboost'可获取数据):
import pandas as pd
data=pd.read_csv('adaboost.csv')
print(data)
输出:
x y
0 0 1
1 1 1
2 2 1
3 3 -1
4 4 -1
5 5 -1
6 6 1
7 7 1
8 8 1
9 9 -1
通过之前的理论介绍可知,AdaBoost算法需要若干个分类能力一般的“弱分类器”。这里,我们选择“单层决策树”作为弱分类器,当然你可以选用其他诸如KNN等。
若干“单层决策树”,联结在一起组合出一个能力较强的强分类器,这便是AdaBoost要做的事情。所以,接下来先实现AdaBoost的组件:“单层决策树”。
单层决策树,也称为决策树桩。决策树是使用“按照一定规则选择的特征”对数据集(子集)做划分,最终得到一棵树(决策树讲解传送门戳我)。这里的单层决策树,其实是决策树的简化版本。单层决策树仅仅依靠一个特征来做决策,因此只会做一次分叉。下面就是一个单层决策树结构的栗子:
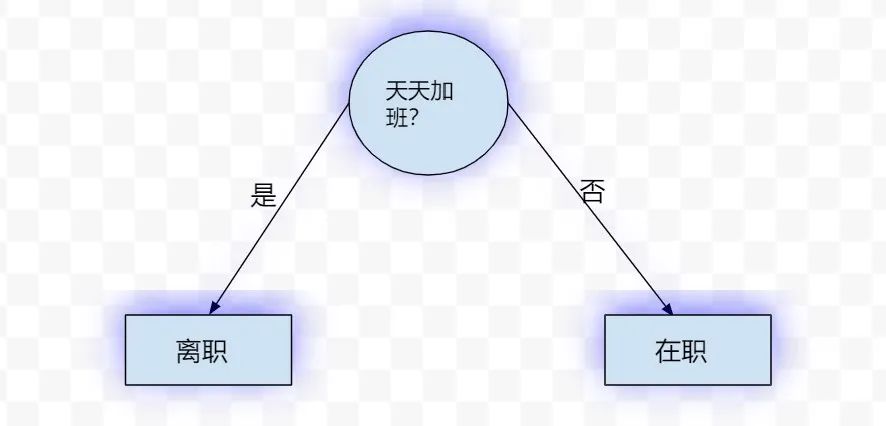
我们现在的目标就是训练若干个这样的单层决策树,下面看一下如何实现吧。
先举个训练单层决策树的例子感受一下,比如在我们本次的数据集中,只有一个特征,那么就选择这个特征对数据集做划分;接下来尝试不同的阈值,比如0.5,1.0等等,假设现在正在尝试阈值2.5,此时对于不等号有两种选择: 或 。先尝试,那么所有的样本会被预测为类,所有的样本会被预测为类(请结合下图进行理解)。
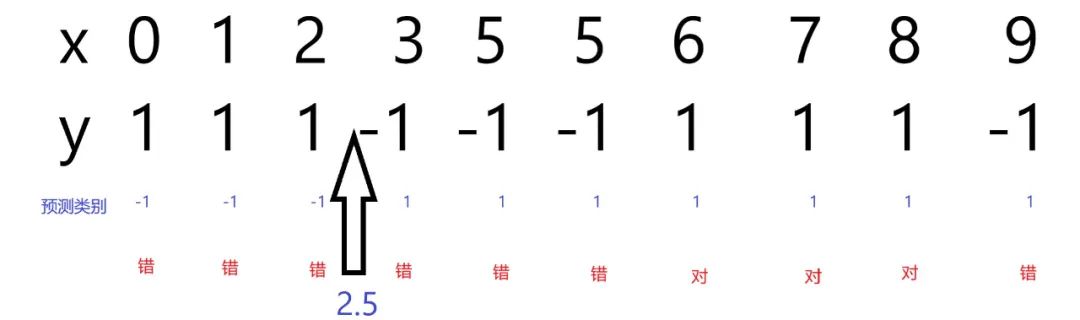
此时得到的单层决策树如下:
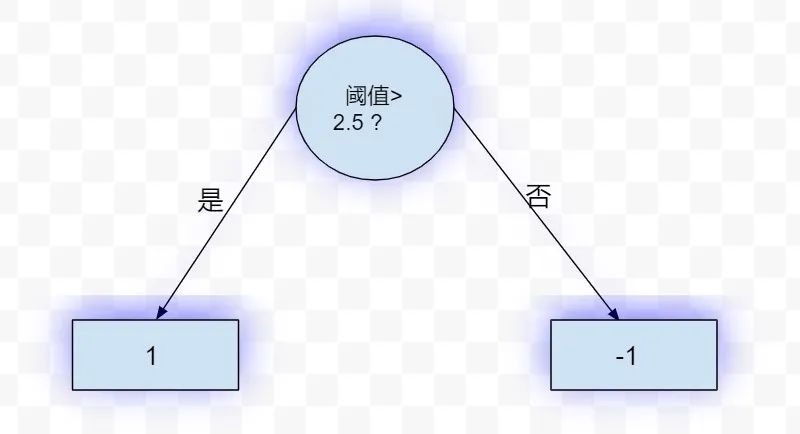
接下来会尝试,过程类似。
ps:如果你有过调参的经历,会觉得上述过程有点像网格搜索。
看完栗子,单层决策树的训练过程也就十分清楚了:
当遍历完所有特征,尝试过每个特征下选取的所有阈值,以及每个阈值下是采用号还是号之后,选择分类效果最好的那一组{特征,阈值,不等号}构建当前轮次下的单层决策树即可。
但是,你有没有思考一个问题,那就是在每次训练弱分类器时,训练数据是不变的,那岂不是说每个训练好的单层决策树都是一样的?
事实的确如此!
这就是AdaBoost发挥作用的地方啦!
前面说过,AdaBoost算法会给每一个样本赋一个权值,并且第个弱分类器的误差率等于当前所有被误分类的样本的权值之和,并且这些权值会根据样本被预测的类别做动态调整。这样一来,我们只需将普通的误差度量的方式(比如“分类错误样本数/总样本数”)改为带权值的误差率即可。
根据以上说明,来实现单层决策树分类器:
class SimpleDT():
def dt_train(self,dataset,D):
#D:样本的权值分布
n_features=len(dataset.iloc[0,:])-1#特征数
y=dataset.iloc[:,-1]#类别标签
min_error=np.inf#初始化最小误差率
best_weak_calssifier={}#弱分类器
best_result=None#最好分类器的分类结果,没啥实际用处,方便debug
best_error_inds=None#最好分类器的出错样本下标,没啥实际用处,方便debug
#尝试每一个特征current_fea
for fea_index in range(n_features):
#首先获取备选阈值
current_fea=dataset.iloc[:,fea_index]#当前特征
min_value,max_value=min(current_fea),max(current_fea)
n_threshs=10
step=(max_value-min_value)/n_threshs
threshs=[min_value]#存储备选阈值
temp=min_value
for i in range(n_threshs):
threshs.append(temp+step)
temp+=step
#print(threshs)#此时全部备选阈值存储在threshs中
#尝试每一个备选阈值thresh
for thresh in threshs:
#尝试>或<
for sign in ['>','<']:
#获取当前弱分类器的分类结果
result=self.cal_result(dataset,fea_index,thresh,sign)
print('使用特征{},阈值:{},符号:{},预测类别:{}'.format(fea_index,thresh,sign,result))
#接下来计算当前误差率e_m
error_inds=[]#预测错误的样本的下标
for ind,pred in enumerate(result):
if pred!=y[ind]:
error_inds.append(ind)
e_m=0
for index in error_inds:
e_m+=D[index]
#更新最小误差率
if e_m<min_error:
min_error=e_m
best_weak_calssifier['fea_index']=fea_index
best_weak_calssifier['thresh']=thresh
best_weak_calssifier['sign']=sign
best_result=result
best_error_inds=error_inds
print('当前弱分类器训练完成!\n 划分特征为第{}个特征,阈值为{},不等号选择{}\n当前最好的分类误差率为{},出错的样本下标为{}\n预测结果为:{}'\
.format(best_weak_calssifier['fea_index'],best_weak_calssifier['thresh'],\
best_weak_calssifier['sign'],min_error,best_error_inds,best_result))
#返回 最小误差率,最好的弱分类器(含:划分特征下标,阈值,不等号),最好的预测结果
return min_error[0],best_weak_calssifier,best_result
#计算分类结果
def cal_result(self,data_X,fea_index,thresh,sign):
fea=data_X.iloc[:,fea_index]#使用的特征
result=[]#预测结果
#对于每一个样本
for i in range(len(data_X.iloc[:,0])):
fea_value=data_X.iloc[i,fea_index]#第i个样本的第fea_index个特征取值
if sign =='>':
if fea_value>=thresh:
result.append(1)
else:
result.append(-1)
else:
if fea_value<=thresh:
result.append(1)
else:
result.append(-1)
return result
上述代码定义了一个单层决策树的类SimpleDT
,并在SimpleDT
中定义了两个方法:dt_train
和cal_result
代码的具体解释已经写在注释中,这里只说一下这两个方法的功能:
cal_result用于计算每一个参数组合({特征,阈值,>或<})下对data_X的分类结果。
dt_train
完成我们之前叙述的单层决策树的训练过程(尝试{不同特征,不同阈值,>或<}的全部组合,这一步会调用cal_result方法;然后选误差率最小单层决策树的作为训练好的模型),它会返回最小误差率,最佳弱分类器(含:{划分特征下标,阈值,不等号})以及最好的预测结果。
来试着使用我们的数据集训练一个弱分类器:
dataset=pd.read_csv('adaboost.csv')
n_samples=len(dataset.iloc[:,0])
sdt=SimpleDT()
D=np.ones((n_samples,1))/n_samples#初始化训练样本的权值分布sdt.dt_train(dataset,D)#训练一个弱分类器
在训练过程中,会输出每一个{特征,阈值,不等号}组合对应的预测结果:
使用特征0,阈值:0,符号:>,预测类别:[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
使用特征0,阈值:0,符号:<,预测类别:[1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
使用特征0,阈值:0.9,符号:>,预测类别:[-1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
使用特征0,阈值:0.9,符号:<,预测类别:[1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
使用特征0,阈值:1.8,符号:>,预测类别:[-1, -1, 1, 1, 1, 1, 1, 1, 1, 1]
使用特征0,阈值:1.8,符号:<,预测类别:[1, 1, -1, -1, -1, -1, -1, -1, -1, -1]
...
在训练结束后,打印出如下信息:
当前弱分类器训练完成!
划分特征为第0个特征,阈值为2.7,不等号选择<
当前最好的分类误差率为[0.3],出错的样本下标为[6, 7, 8]
预测结果为:[1, 1, 1, -1, -1, -1, -1, -1, -1, -1]
由打印信息可知,{特征=第0个特征,阈值=2.7,不等号选择<}是当前弱分类器的最佳组合,由该组合得到的最小误差率为0.3。
以上完成了单层决策树的创建。
现在已经有了单层决策树这个弱分类器,剩下要做的就是训练多个这样的弱分类器,并把它们按照AdaBoost算法的思想联结在一起,得到一个强分类器。
我们定义一个类AdaBoost
,它继承自之前实现的SimpleDT
类,以便能够调用SimpleDT
的训练方法dt_train
和分类方法cal_result
。
class AdaBoost(SimpleDT):
def adab_train(self,dataset,n_iterations):
n_samples=len(dataset.iloc[:,0])#样本量
y=dataset.iloc[:,-1]#真实类别标签
weak_classifiers=[]#存储弱分类器
total_cusum=np.zeros((n_samples,1))#存储各弱分类器加权预测值的累计结果
D=np.ones((n_samples,1))/n_samples#初始化训练样本的权值分布
for it in range(n_iterations):
#获取当前弱分类器及其对应的误差率,预测结果,对应(1)(2)
error,weak_classifier,pred=self.dt_train(dataset,D)
#丢弃误差率大于0.5的弱分类器
if error<=0.5:
#计算系数,对应(3)
alpha=0.5*np.log((1-error)/error)
weak_classifier['alpha']=alpha
#将当前弱分类器添加到弱分类器序列
weak_classifiers.append(weak_classifier)
#更新权值分布,对应(4)
z=0#(4)中公式的分母部分
temp=[]
for i in range(n_samples):
temp.append(D[i]*np.exp(-alpha*y[i]*pred[i]))
z+=D[i]*np.exp(-alpha*y[i]*pred[i])
for i,item in enumerate(temp):
temp[i]=item/z
D=temp#更新后的权值分布D
#联结现有的所有弱分类器==>终极分类器,并计算累计的预测值total_cusum
pred=np.array(pred).reshape(-1,1)
total_cusum+=alpha*pred
#print(total_cusum)#shape:(n_samples,1)
#应用符号函数求终极分类器的预测结果
final_pred=[]
for i in total_cusum:
if i >=0:
final_pred.append(1)
else:
final_pred.append(-1)
#计算当前终极分类器的误差
err=0
for i,pred in enumerate(final_pred):
if pred!=y[i]:
err+=1
error_rate=err/n_samples#误差
print('当前分类器由{}个弱分类器联结而成,当前分类错误率:{}\n'.format(len(weak_classifiers),error_rate))
#弱误差已经为0,则提前终止
if error_rate ==0 :
print('已全部分类正确,退出...')
break
#返回全部弱分类器的序列
return weak_classifiers
#对新的样本x进行分类
def make_classification(self,test_data,weak_classifiers):
n_samples=len(test_data.iloc[:,0])
total_cusum=np.zeros((n_samples,1))#存储各弱分类器加权预测值的累计结果
n_classifiers=len(weak_classifiers)#弱分类器的个数
for i in range(n_classifiers):
pred=self.cal_result(test_data,weak_classifiers[i]['fea_index'],weak_classifiers[i]['thresh'],weak_classifiers[i]['sign'])
pred=np.array(pred).reshape(-1,1)
total_cusum+=weak_classifiers[i]['alpha']*pred
#应用符号函数求终极分类器的预测结果
final_pred=[]
for i in total_cusum:
if i >=0:
final_pred.append(1)
else:
final_pred.append(-1)
return final_pred
AdaBoost
类中定义了两个方法:adab_train
和make_classification
。
adab_train
完成了AdaBoost算法步骤中的(1)到(4),这些已在注释中进行标记,请看注释。该方法最终返回的是所有弱分类器的序列。
make_classification
用于对传入的待分类数据test_data
进行分类,这其实就是我们最终需要的强分类器。该方法用adab_train
返回的弱分类器序列中的每一个弱分类器对test_data
进行分类,并对其分类结果(1 or -1)进行加权,最后将这些加权后的预测值累加起来,通过符号函数的映射,就得到了强分类器的预测结果。
还是对之前的例子,先使用AdaBoost算法进行训练,这次我们只关注强分类器的训练结果,所以将之前SimpleDT类中的一些输出信息注释掉。
dataset=pd.read_csv('adaboost.csv')
adaboost=AdaBoost()
weak_classifiers=adaboost.adab_train(dataset,10)
输出:
当前分类器由1个弱分类器联结而成,当前分类错误率:0.3
当前分类器由2个弱分类器联结而成,当前分类错误率:0.3
当前分类器由3个弱分类器联结而成,当前分类错误率:0.0
已全部分类正确,退出...
可见,我们虽然预先设置训练10个轮次(在所有弱分类器的误差率都不大于0.5的前提下,相应的会得到10个弱分类器),但是程序训练了3个轮次就是停止了。通过输出的信息可以直到,在训练完第三个弱分类器之后,这三个弱分类器联结后形成的强分类器已经有足够能力将全部样本都分类正确,因而触发了break
语句,于是训练结束。
训练结束以后,就得到了最终的强分类器啦,它由若干(在本例中是“3”)个弱分类器(在本例中是“单层决策树”)联结在一起。
最后,让我们构造一些测试数据,来走一遍强分类器的分类过程:
test_data=pd.DataFrame([1,2,3,4])
print('测试数据的分类结果为:',adaboost.make_classification(test_data,weak_classifiers))
输出:
测试数据的分类结果为: [1, 1, -1, -1]
最后附上完整代码(供复制):
import pandas as pd
import numpy as np
class SimpleDT():
def dt_train(self,dataset,D):
#D:样本的权值分布
n_features=len(dataset.iloc[0,:])-1#特征数
y=dataset.iloc[:,-1]#类别标签
min_error=np.inf#初始化最小误差率
best_weak_calssifier={}#弱分类器
best_result=None#最好分类器的分类结果,没啥实际用处,方便debug
best_error_inds=None#最好分类器的出错样本下标,没啥实际用处,方便debug
#尝试每一个特征current_fea
for fea_index in range(n_features):
#首先获取备选阈值
current_fea=dataset.iloc[:,fea_index]#当前特征
min_value,max_value=min(current_fea),max(current_fea)
n_threshs=10
step=(max_value-min_value)/n_threshs
threshs=[min_value]#存储备选阈值
temp=min_value
for i in range(n_threshs):
threshs.append(temp+step)
temp+=step
#print(threshs)#此时全部备选阈值存储在threshs中
#尝试每一个备选阈值thresh
for thresh in threshs:
#尝试>或<
for sign in ['>','<']:
#获取当前弱分类器的分类结果
result=self.cal_result(dataset,fea_index,thresh,sign)
#print('使用特征{},阈值:{},符号:{},预测类别:{}'.format(fea_index,thresh,sign,result))
#接下来计算当前误差率e_m
error_inds=[]#预测错误的样本的下标
for ind,pred in enumerate(result):
if pred!=y[ind]:
error_inds.append(ind)
e_m=0
for index in error_inds:
e_m+=D[index]
#更新最小误差率
if e_m<min_error:
min_error=e_m
best_weak_calssifier['fea_index']=fea_index
best_weak_calssifier['thresh']=thresh
best_weak_calssifier['sign']=sign
best_result=result
best_error_inds=error_inds
"""
print('当前弱分类器训练完成!\n 划分特征为第{}个特征,阈值为{},不等号选择{}\n当前最好的分类误差率为{},出错的样本下标为{}\n预测结果为:{}'\
.format(best_weak_calssifier['fea_index'],best_weak_calssifier['thresh'],\
best_weak_calssifier['sign'],min_error,best_error_inds,best_result))
"""
#返回 最小误差率,最好的弱分类器(含:划分特征下标,阈值,不等号),最好的预测结果
return min_error[0],best_weak_calssifier,best_result
#计算分类结果
def cal_result(self,data_X,fea_index,thresh,sign):
fea=data_X.iloc[:,fea_index]#使用的特征
result=[]#预测结果
#对于每一个样本
for i in range(len(data_X.iloc[:,0])):
fea_value=data_X.iloc[i,fea_index]#第i个样本的第fea_index个特征取值
if sign =='>':
if fea_value>=thresh:
result.append(1)
else:
result.append(-1)
else:
if fea_value<=thresh:
result.append(1)
else:
result.append(-1)
return result
class AdaBoost(SimpleDT):
def adab_train(self,dataset,n_iterations):
n_samples=len(dataset.iloc[:,0])#样本量
y=dataset.iloc[:,-1]#真实类别标签
weak_classifiers=[]#存储弱分类器
total_cusum=np.zeros((n_samples,1))#存储各弱分类器加权预测值的累计结果
D=np.ones((n_samples,1))/n_samples#初始化训练样本的权值分布
for it in range(n_iterations):
#获取当前弱分类器及其对应的误差率,预测结果,对应(1)(2)
error,weak_classifier,pred=self.dt_train(dataset,D)
#丢弃误差率大于0.5的弱分类器
if error<=0.5:
#计算系数,对应(3)
alpha=0.5*np.log((1-error)/error)
weak_classifier['alpha']=alpha
#将当前弱分类器添加到弱分类器序列
weak_classifiers.append(weak_classifier)
#更新权值分布,对应(4)
z=0#(4)中公式的分母部分
temp=[]
for i in range(n_samples):
temp.append(D[i]*np.exp(-alpha*y[i]*pred[i]))
z+=D[i]*np.exp(-alpha*y[i]*pred[i])
for i,item in enumerate(temp):
temp[i]=item/z
D=temp#更新后的权值分布D
#联结现有的所有弱分类器==>终极分类器,并计算累计的预测值total_cusum
pred=np.array(pred).reshape(-1,1)
total_cusum+=alpha*pred
#print(total_cusum)#shape:(n_samples,1)
#应用符号函数求终极分类器的预测结果
final_pred=[]
for i in total_cusum:
if i >=0:
final_pred.append(1)
else:
final_pred.append(-1)
#计算当前终极分类器的误差
err=0
for i,pred in enumerate(final_pred):
if pred!=y[i]:
err+=1
error_rate=err/n_samples#误差
print('当前分类器由{}个弱分类器联结而成,当前分类错误率:{}\n'.format(len(weak_classifiers),error_rate))
#弱误差已经为0,则提前终止
if error_rate ==0 :
print('已全部分类正确,退出...')
break
#返回全部弱分类器的序列
return weak_classifiers
#对新的样本x进行分类
def make_classification(self,test_data,weak_classifiers):
n_samples=len(test_data.iloc[:,0])
total_cusum=np.zeros((n_samples,1))#存储各弱分类器加权预测值的累计结果
n_classifiers=len(weak_classifiers)#弱分类器的个数
for i in range(n_classifiers):
pred=self.cal_result(test_data,weak_classifiers[i]['fea_index'],weak_classifiers[i]['thresh'],weak_classifiers[i]['sign'])
pred=np.array(pred).reshape(-1,1)
total_cusum+=weak_classifiers[i]['alpha']*pred
#应用符号函数求终极分类器的预测结果
final_pred=[]
for i in total_cusum:
if i >=0:
final_pred.append(1)
else:
final_pred.append(-1)
return final_pred
if __name__ =='__main__':
dataset=pd.read_csv('adaboost.csv')
#print(dataset)
#n_samples=len(dataset.iloc[:,0])
#sdt=SimpleDT()
#D=np.ones((n_samples,1))/n_samples#初始化训练样本的权值分布
#print(sdt.dt_train(dataset,D))
adaboost=AdaBoost()
weak_classifiers=adaboost.adab_train(dataset,10)
test_data=pd.DataFrame([1,2,3,4])
print('测试数据的分类结果为:',adaboost.make_classification(test_data,weak_classifiers))
总结一下
本文第一部分使用类比的方式介绍了提升方法的思想,然后引出了提升方法中最具代表性的一种:AdaBoost算法。第二部分叙述了AdaBoost算法的步骤,并对其中的细节通过数形结合的方式加以解释。第三部分围绕给定的数据集,使用Python实现了AdaBoost算法指导下的强分类器,具体来说,先实现了强分类器的组件:弱分类器,然后将这些弱分类器的预测结果进行加权求和,再经过符号函数的映射,就得到了强分类器的预测结果。
参考资料:
[1][李航-统计学习方法] [2][Peter Harrington-机器学习实战]
最后,求在看,求点赞,求分享!
对了,南极Python交流群已经成立,欢迎进群交流学习(划水)


●从零开始生成一棵决策树
●k-近邻算法讲解+Python实现
●kd树理论讲解+Python实现
●徒手打造一个朴素贝叶斯分类器
