




我回来啦,这次打算开一个新坑:
图解机器学习算法+Python实现系列
今天带来开场第一弹:k-近邻算法
搬好小板凳,我们开始吧~
开篇
k-近邻算法
是比较简单的一种机器学习算法,其核心思想可以用一句话来概括:近朱者赤,近墨者黑。
在具体介绍该算法之前,先通过一个栗子对该算法做一个感性上的认识。
Python爱好者 or C爱好者?
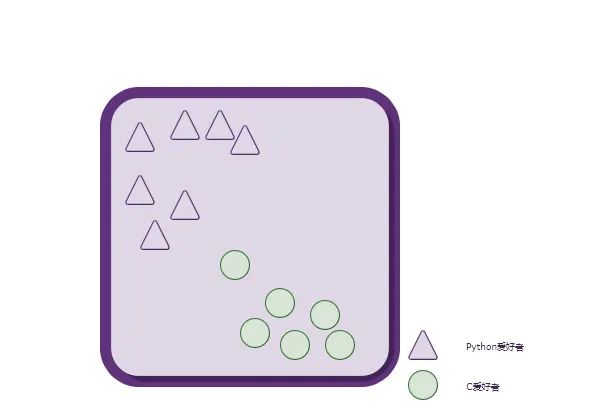
上图中,每一个形状(三角形,圆形)都代表了一个人。总共有两种形状,说明这些人总共可以分为两类:Python爱好者、C爱好者。
三角形一共有7个,代表喜欢写Python的总共有7人;
圆形一共有6个,代表喜欢写C的总共有6人。
现在,突然来了一个不知道是喜欢写Python还是C(并且只可能属于其中之一)的人-----五角星,要求你来判定这个人所属的类别。
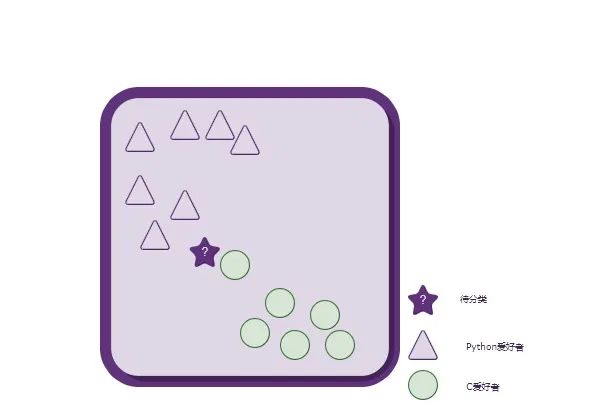
一个可能的想法是:看看图上距离这个人(五角星)最近的几个人所属类别,比如就看距离这个人最近的3
个人:其中有两个人喜欢写Python,而只有一个人喜欢写C(如下图所示)
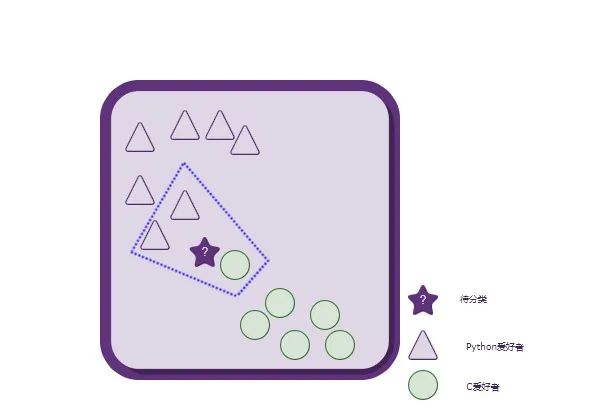
按照少数服从多数的原则,将这个新来的人(五角星)归类到三角形(Python爱好者)类别就搞定啦!
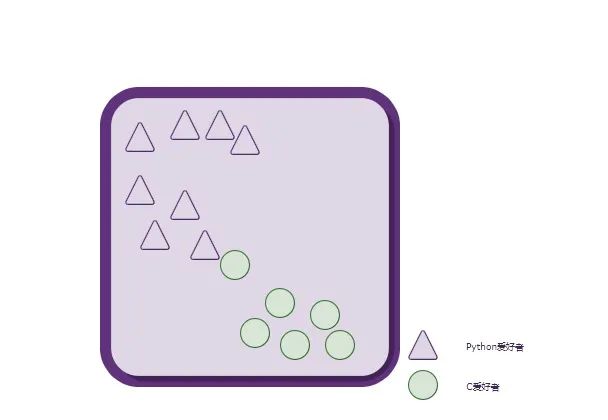
最终分类结果
上面的栗子其实就蕴含着k-近邻算法的思想。现在,让我们对该算法做一个完整的阐述。
什么是k-近邻算法 ?
k-近邻算法是一种有监督的机器学习算法,对于有监督的机器学习算法来说,其训练数据集的一般格式如下(0:类别1;1:类别2):
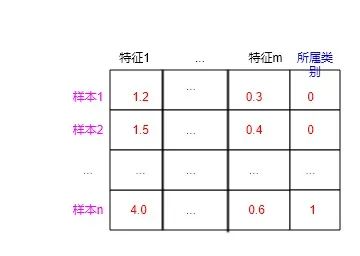
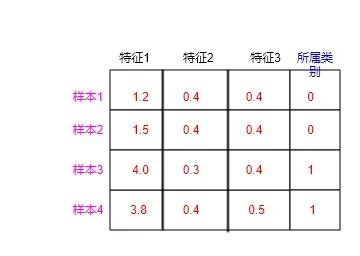
当n取4,m取3时,就是一个含有4个样本,每个样本有3个特征的数据集了,如下图
k-近邻算法的核心思想为:对于一个给定的训练集,当新的样本到来时,找到训练集中与新样本距离最近的k
个样本,然后查看这k个样本所属类别,并将新样本归类到这k个样本中大多数样本所属类别中。
没错,k-近邻算法的思想就是这么简洁。接下来,我们将用Python来实现该算法。
用Python实现k-近邻算法
在实现k-近邻算法之前,先自行定义训练集:
class DataSet():
feature=np.array([[2.3,2.4],
[0.1,0.2],
[2.4,2.3],
[0.2,0.1],
[0.2,0.2],
[2.4,2.4]
])
target=np.array([1,0,1,0,0,1])
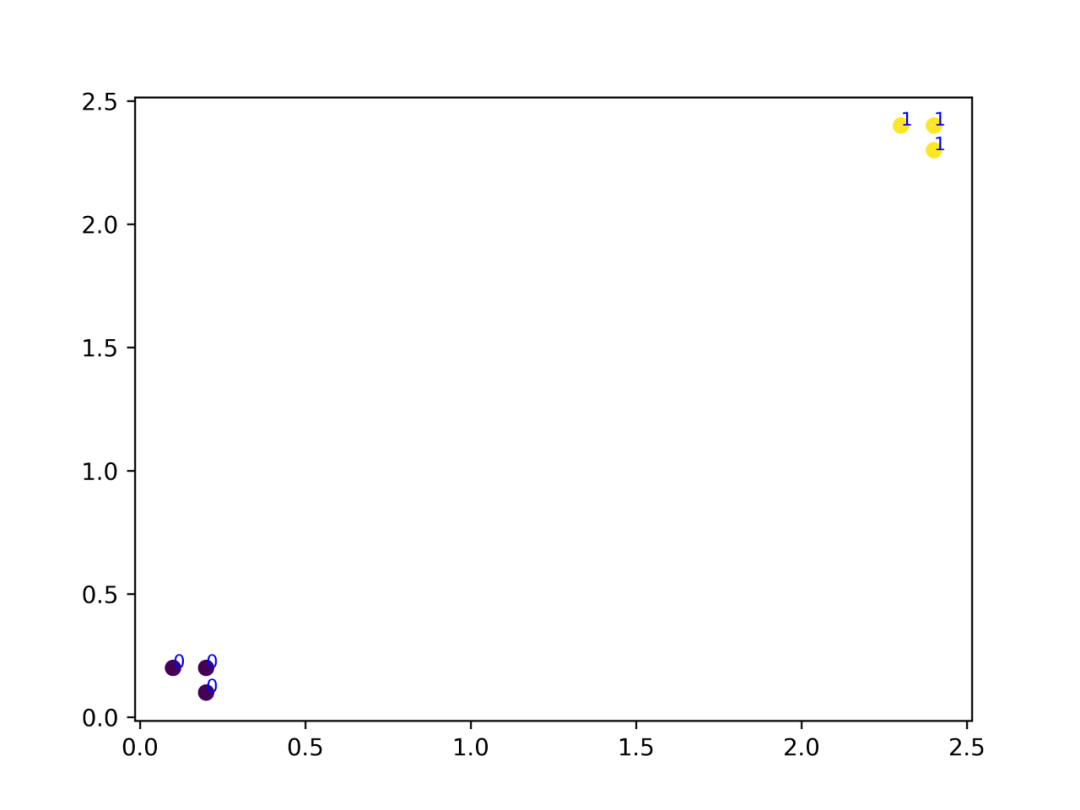
然后查看下训练数据集的分布(0和1代表样本所属的类别)
data=DataSet()
plt.scatter(data.feature[:,0],data.feature[:,1],c=data.target)
for i in range(len(data.feature)):
plt.text(data.feature[i,0], data.feature[i,1],data.target[i], fontsize=8, color = "b")
plt.show()
现在开始实现k-近邻算法:
首先明确,k-近邻算法中的k
是我们自己指定的(当然k的选取是有技巧的,这个稍后会说,这里我们仅仅关心如何用Python实现该算法),训练数据集也是自己的(废话,训练集肯定要自行准备的啊),所以有两个参数需要我们自行传入,其一为k
,其二为训练集data
。
class MyKNN():
def __init__(self,data,k):
self.samples_feature=data.feature#样本特征
self.samples_target=data.target#样本所属类别
self.k=k
由于k-近邻算法涉及到了距离,因此需要写一个计算距离的方法。距离的度量方式有很多,这里我们采用大家最为熟悉的L2距离,也就是欧氏距离:
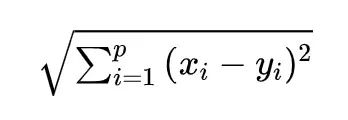
def cal_dist(self,sample1,sample2):
return np.sqrt(np.sum((sample1-sample2)**2))
接下来是k-近邻算法的核心实现步骤:
1.分别计算新的样本与训练集中所有样本之间的距离; 2.按照距离从小到大排序; 3.选取距离新样本最近的k个距离及其对应样本所属类别; 4.将新样本归类到与其距离最近的k个样本中大多数样本所属类别。
def run(self,new_sample_feature):
#对于每一个样本的特征
all_dists=[]
for i, sample_feature in enumerate(self.samples_feature):
#1.分别计算新的样本与训练集中所有样本之间的距离
dist=self.cal_dist(sample_feature,new_sample_feature)
all_dists.append((dist,self.samples_target[i]))
#2.按照距离从小到大排序
sorted_dist_with_target=sorted(all_dists,key=lambda x:x[0])
#3.选取距离新样本最近的k个
top_k=sorted_dist_with_target[0:self.k]
#4.统计这k个样本中大多数样本所属类别
dic={}
for item in top_k:
if item[1] in dic:
dic[item[1]]+=1
else:
dic[item[1]]=1
result=sorted(dic.items(),key=lambda x:x[1])[-1][0]
return result
这样,我们就实现了k-近邻算法,完整代码如下:
import numpy as np
class MyKNN():
def __init__(self,data,k):
self.samples_feature=data.feature#样本特征
self.samples_target=data.target#样本所属类别
self.k=k
#计算两个样本之间的欧氏距离(L2距离)
def cal_dist(self,sample1_feature,sample2_feature):
return np.sqrt(np.sum((sample1_feature-sample2_feature)**2))
def run(self,new_sample_feature):
#对于每一个样本的特征
all_dists=[]
for i, sample_feature in enumerate(self.samples_feature):
#分别计算新的样本与训练集中所有样本之间的距离
dist=self.cal_dist(sample_feature,new_sample_feature)
all_dists.append((dist,self.samples_target[i]))
#按照距离从小到大排序
sorted_dist_with_target=sorted(all_dists,key=lambda x:x[0])
#选取距离新样本最近的k个
top_k=sorted_dist_with_target[0:self.k]
#统计这k个样本中大多数样本所属类别
dic={}
for item in top_k:
if item[1] in dic:
dic[item[1]]+=1
else:
dic[item[1]]=1
result=sorted(dic.items(),key=lambda x:x[1])[-1][0]
return result
测试k-近邻算法
我们前面已经实现了k-近邻算法,那么它的分类能力究竟如何呢?
现在,自定义一个测试集,用刚刚实现的k-近邻算法对测试集样本进行分类(这里的k不妨取3):
test_samples_feature=np.array([[2.4,2.5],
[0.3,0.1],
[2.3,1.9],
[0.1,0.3]
])
for i,item in enumerate(test_samples_feature):
print('第{}个样本所属类别为{}'.format(i+1,knn.run(item)))
输出:
第1个样本所属类别为1
第2个样本所属类别为0
第3个样本所属类别为1
第4个样本所属类别为0
那这个结果可不可靠呢? 我们需要评估一下。千言万语不及一张图,所以这里我们还是用可视化的方式来演示。
在训练数据可视化结果图的基础上,将测试数据也绘制在这张图上,完整代码如下:
data=DataSet()
#训练数据
plt.scatter(data.feature[:,0],data.feature[:,1],c=data.target)
for i in range(len(data.feature)):
plt.text(data.feature[i,0], data.feature[i,1],data.target[i], fontsize=8, color = "b")
#测试数据
plt.scatter(test_samples_feature[:,0],test_samples_feature[:,1])
for i in range(len(test_samples_feature)):
plt.text(test_samples_feature[i,0], test_samples_feature[i,1], 'sample{}:\n'.format(i+1)+str((test_samples_feature[i,0],test_samples_feature[i,1])), fontsize=10, color = "r")
plt.show()
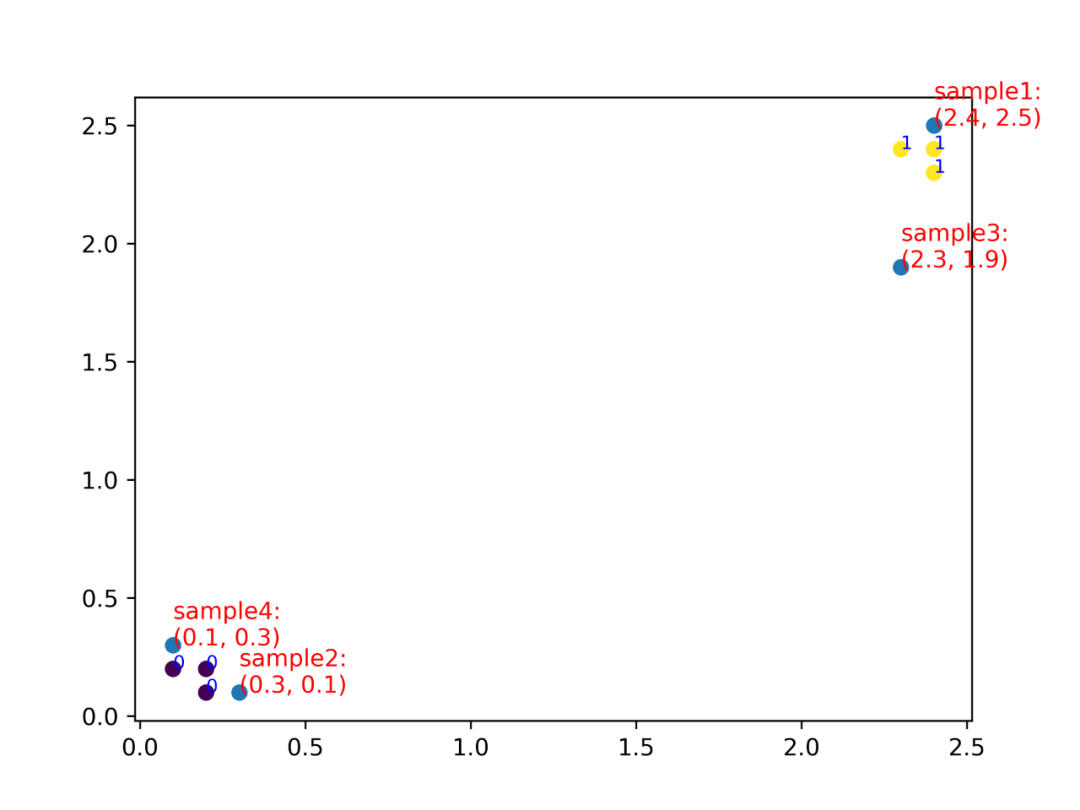
观察上图,当k取3时:
与样本1距离最近的3个样本中,大多数样本都是属于类别1的(本例是特例,全部3个样本都属于类别1),因此样本1应该归类到类别1;
与样本2距离最近的3个样本中,大多数样本都是属于类别0的,因此样本2应该归类到类别0;
与样本3距离最近的3个样本中,大多数样本都是属于类别1的,因此样本3应该归类到类别1;
与样本4距离最近的3个样本中,大多数样本都是属于类别0的,因此样本4应该归类到类别0。
所以,最终的分类结果应该是:[1,0,1,0],这与程序跑出来的结果是对应的,从而我们实现的k-近邻算法是成功的。
更多关于k-近邻算法的使用技巧
k值通常取奇数,这是因为,当k取偶数,比如k=2时,有可能距离新样本最近的2个样本分别属于两个不同的类别,此时无法判定新样本所属类别; k不宜过大,也不宜过小,通常采用交叉验证的方式进行k值的选取; 同大多数机器学习算法一样,在实际应用k-近邻算法时,为了减少特征的量纲不同而导致的各特征重要程度不一致现象,往往在将数据喂入机器学习算法之前,先对数据做归一化或者标准化等预处理工作。举个例子,对于具有3个特征的两个样本:[0.2,0.3,999], [0.3,0.2, 899],由于第三个特征数值相对于前两个特征较大,因此在计算这两个样本的距离时,第三个特征将主导最后的距离计算结果,而前两个特征的作用几乎被忽略不计了,这样的话,就相当于前两个特征传递的信息丢失了,这可不是我们所希望的!因此这一步很有必要。
参考:
[1] [李航-统计学习方法] [2] [Peter Harrington-机器学习实战]
原创不易,求个在看
你这么好看,一定要点个在看

