




作者:刘人杰 RisingWave Labs 内核开发工程师
1什么是 Apache Iceberg
Apache Iceberg[1]是一种被广泛采用的开放式 Table 格式,在 Lakehouse 架构中发挥着至关重要的作用。作为一种流行的表格式,Apache Iceberg 具有以下几个主要特点:
多引擎支持。Apache Iceberg 的 Spec[2]不受任何特定计算引擎或编程语言的约束,提供了一个可在不同系统中实施的清晰定义。 高性能。Apache Iceberg 专用于高效处理大量数据。 ACID 保证。Apache Iceberg 可确保数据操作的原子性、一致性、隔离性和持久性(以上四个特性简写为 ACID 特性)。
此外,它还有一些可以进一步探索的高级功能,比如分支(Branching)和时间旅行(Time Travel)等。
2为什么要重构连接器
我们在 RisingWave 中引入了新版 Iceberg Sink 连接器,以解决原始版本中遇到的各种问题。原始版本将 Java 库封装在 Rust 中来满足用户的需求,但随着用户越来越多,我们发现了一些问题。
比如,数据转换为 Java 数据时,序列化/反序列化以及不必要的内存分配引发的性能问题。此外,由于跨语言转换,很难确保与 Iceberg 高级功能(如多目录支持和隐藏分区)的兼容性。
为了解决这些问题、更好地为用户提供服务,我们决定使用 Rust 重写 Iceberg 连接器。得益于 Apache Iceberg 完善的 Spec[3]和设计,重构过程非常顺利。我们已经将新版本贡献到 apache/iceberg-rust[4] 仓库。新版连接器的文档可在此处[5]找到。
3架构
Apache Iceberg 的一个显著特点是,它可清楚地将元数据层与数据层分隔开。这种设计允许计算引擎独立扩展其读写进程,同时在 S3 或 HDFS 等无限存储系统上保证 ACID(原子性、一致性、隔离性、持久性)。
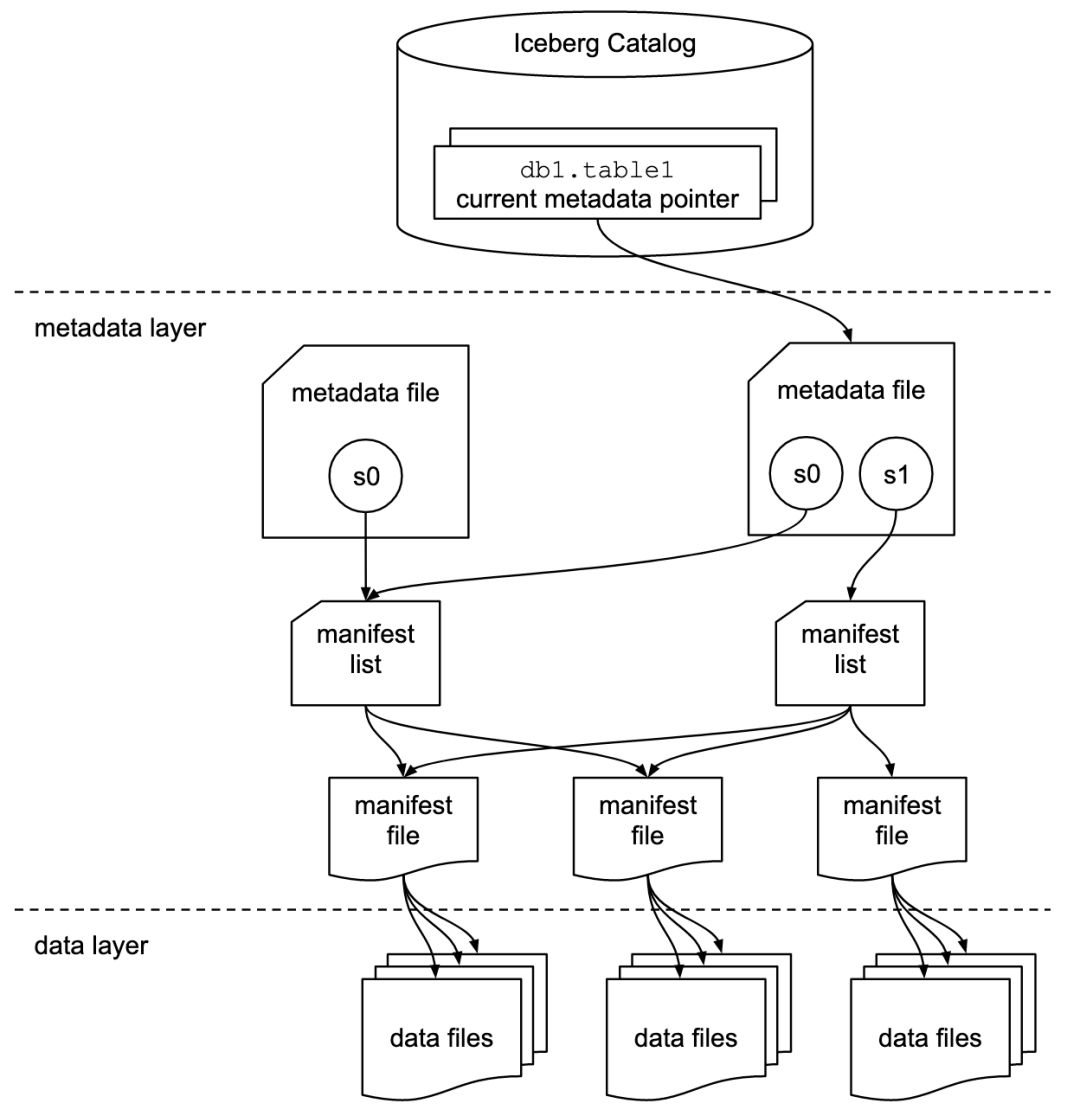
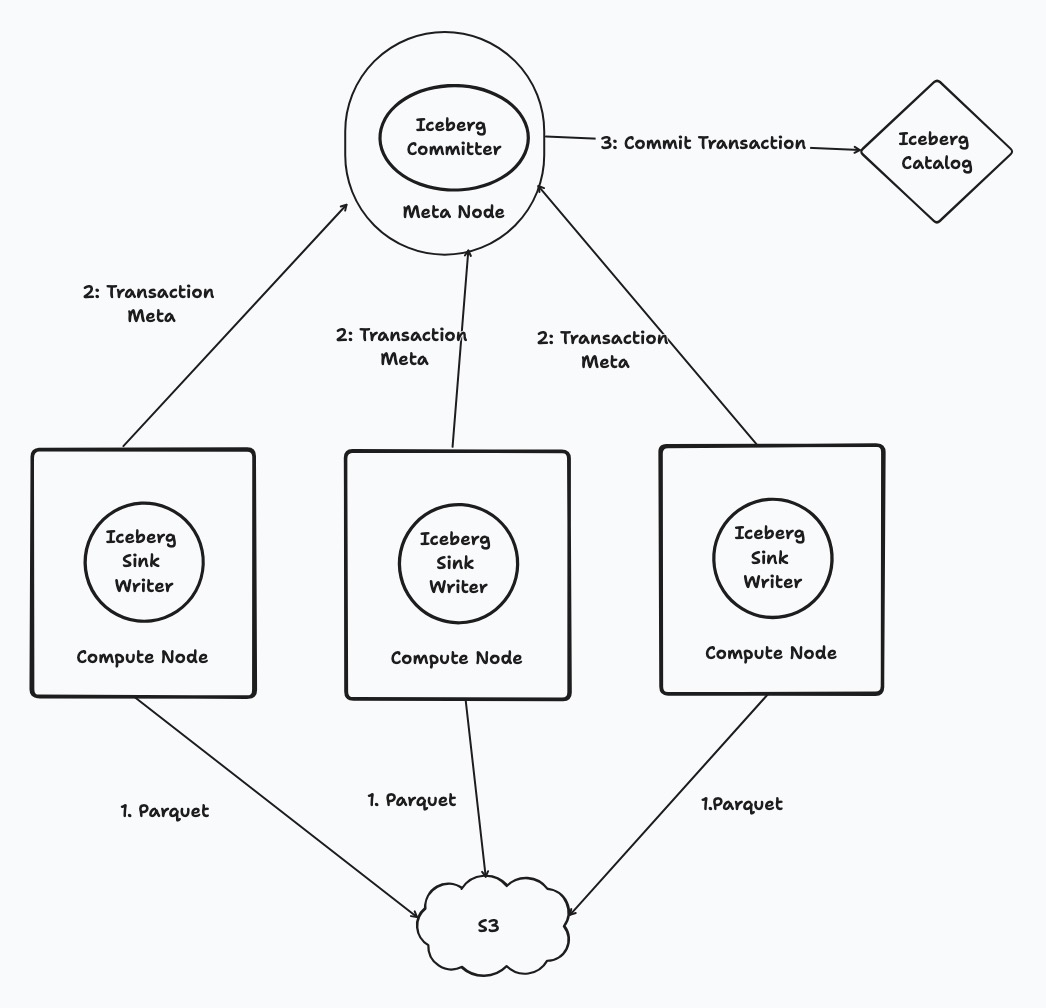
RisingWave 中的 Iceberg Sink 连接器采用的设计可将写入数据的过程与提交到 Iceberg 目录的行为分开。触发检查点时,会将数据刷新到 Parquet 文件中,然后继续将事务提交到 Iceberg 目录。这种方法既能实现可扩展的数据摄取,又能保证 Iceberg 表提供的 ACID。
4如何利用 Iceberg v2 中的流式更新支持
Iceberg 早期设计用于 Append-Only 操作,而 Iceberg v2 增加了支持删除的功能,从而实现了高效的流式更新。Apache Iceberg 具有两种删除类型:等式删除(Equation deletion)和位置删除(Position deletion)。
等式删除:用于删除与先前版本中具有相同等式删除键的数据。 位置删除:用于删除先前或当前版本中具有相同位置的数据。
在新版 Iceberg 连接器中,更新 Jerry
计数的过程如下:
最初,当执行操作 update count = 5 where name = 'Jerry'
时,RisingWave 会创建一个等式删除条目,删除条件为name = 'Jerry'
的行。随后,将数据('Jerry', 5)
写入数据文件。此时,我们记录了 name = 'Jerry'
对应的数据位置在文件s3://test/1.parquet
的第 3 位。当我们执行操作 update count = 7 where name = 'Jerry'
时,我们会添加一个位置删除('s3://test/1.parquet', 3)
用来删除上一条记录。随后将('Jerry', 7)
写入数据文件。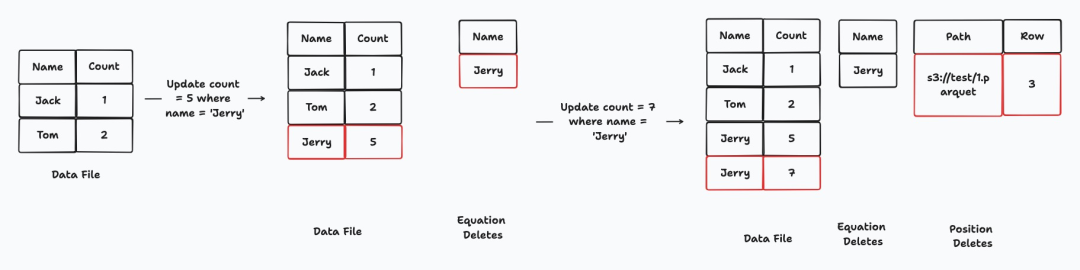
Jerry计数的过程
5可能的表维护问题及解决方案
RisingWave Iceberg 连接器可提供高吞吐量摄取。不过,也会出现一些常见问题:
快照过多:提交到 Iceberg 表会创建新的快照,可能会增加元数据文件的大小。 大量小文件:频繁提交到 Iceberg 表会生成小文件,从而对读取性能产生负面影响。 删除文件过多:尽管 Iceberg + RisingWave 可以实现高效更新,但删除文件过多也会影响读取性能。
Iceberg 社区提供了几种操作[6]来缓解这些问题:
使用 expire_snapshots
和remove_orphan_files
清空旧快照并释放数据文件。使用 rewrite_position_delete_files
将小的位置删除文件合并为大文件。使用 rewrite_data_files
完全清除删除文件,从而实现最佳读取性能。
6结论
RisingWave 对 Iceberg 的原生支持能为用户带来许多益处。通过集成 Iceberg v2 的高级功能,RisingWave 提高了效率和稳定性。这让 RisingWave 用户能够最大限度地发挥数据潜力,并从数据湖架构中提取有价值的见解。此次更新使用户能够充分利用 RisingWave 和 Iceberg 的优势,从而激发更多可能性。
参考资料
Apache Iceberg: https://iceberg.apache.org/
[2]Spec: https://iceberg.apache.org/spec/
[3]Spec: https://iceberg.apache.org/spec/
[4]apache/iceberg-rust: https://github.com/apache/iceberg-rust
[5]此处: https://zh-cn.risingwave.com/docs/current/sink-to-iceberg
[6]几种操作: https://iceberg.apache.org/docs/latest/spark-procedures/
关于 RisingWave


往期推荐
技术内幕
