




前言
记录总结一下 Hive 表如何添加新的字段以及遇到的问题。
最初是因为要验证 Hudi Schema Evolution 中的增加字段问题
SQL
alter table test_hive add columns (col_new string);
# 级联应用到分区表的所有分区
# 对于 Parquet、Text 分区表需要加cascade , ORC 分区表可以不加;建议只要是分区表都加上 cascade
# 非分区表加 cascade 会报错:Alter table with non-partitioned table does not support cascade (state=42000,code=10410)
alter table test_hive add columns (col_new string) cascade;
# 同时新增多个字段
alter table test_hive add columns (col_new1 string, col_new2 int);
# 注释
alter table test_hive add columns (col_new_with_comment string comment '测试新增字段');
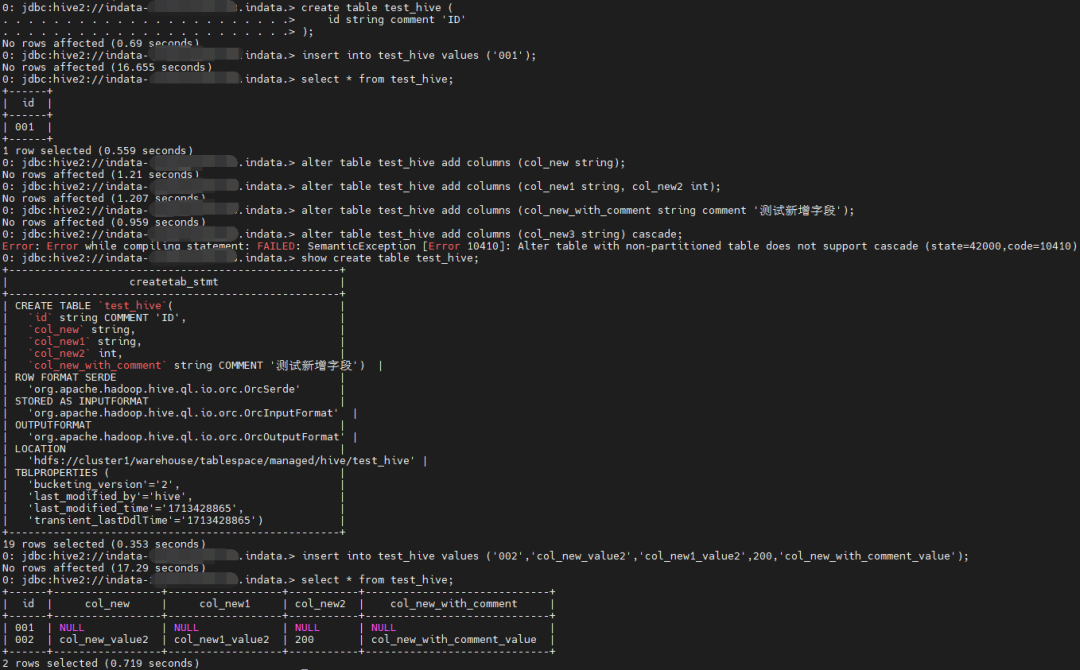
示例
建表
create table test_hive (
id string comment 'ID'
);
插入数据
insert into test_hive values ('001');
查询
select * from test_hive;
新增几个字段
alter table test_hive add columns (col_new string);
alter table test_hive add columns (col_new1 string, col_new2 int);
alter table test_hive add columns (col_new_with_comment string comment '测试新增字段');
查看表结构
show create table test_hive;
插入数据
insert into test_hive values ('002','col_new_value2','col_new1_value2',200,'col_new_with_comment_value');
查询新增列新增数据是否正常
select * from test_hive;
问题
如上SQL所述,对于 Parquet、Text 分区表增加字段时如果不加 cascade 会有问题:新增字段后,对于已存在的分区新增的数据,新增字段查询结果为null(Hive查询),用 Spark SQL 和 Flink SQL 查询正常,对应的 parquet文件实际是有数据的。新增分区对应的新增数据,查询结果正常。
问题复现
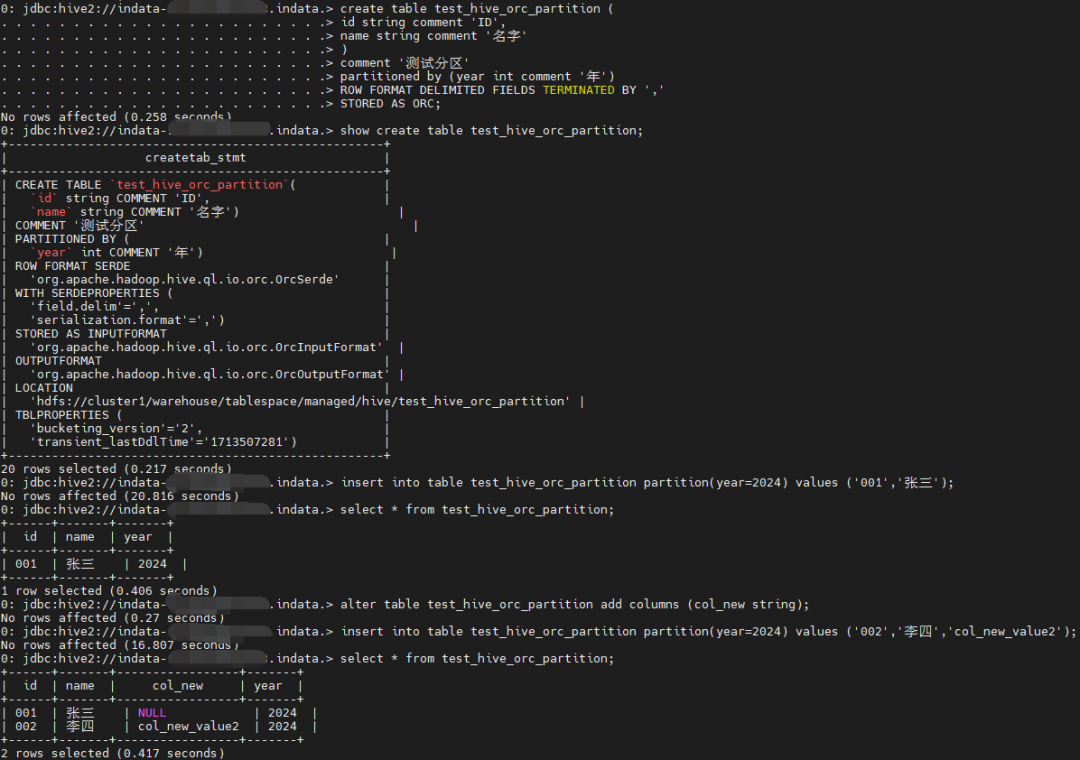
ORC 分区表
ORC 分区表不存在这个问题
建表
create table test_hive_orc_partition (
id string comment 'ID',
name string comment '名字'
)
comment '测试分区'
partitioned by (year int comment '年')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS ORC;
show create table test_hive_orc_partition;
插入数据
insert into table test_hive_orc_partition partition(year=2024) values ('001','张三');
查询
select * from test_hive_orc_partition;
新增字段
alter table test_hive_orc_partition add columns (col_new string);
插入数据
insert into table test_hive_orc_partition partition(year=2024) values ('002','李四','col_new_value2');
查询新增列新增数据是否正常
select * from test_hive_orc_partition;
可以看到一切正常:
Text 分区表
建表
create table test_hive_text_partition (
id string comment 'ID',
name string comment '名字'
)
comment '测试分区'
partitioned by (year int comment '年')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
插入数据
insert into table test_hive_text_partition partition(year=2024) values ('001','张三');
查询
select * from test_hive_text_partition;
新增字段
alter table test_hive_text_partition add columns (col_new string);
插入数据
# 已有分区
insert into table test_hive_text_partition partition(year=2024) values ('002','李四','col_new_value2');
查询新增列新增数据是否正常
select * from test_hive_text_partition;
可以看到新增字段对应的查询内容为空:
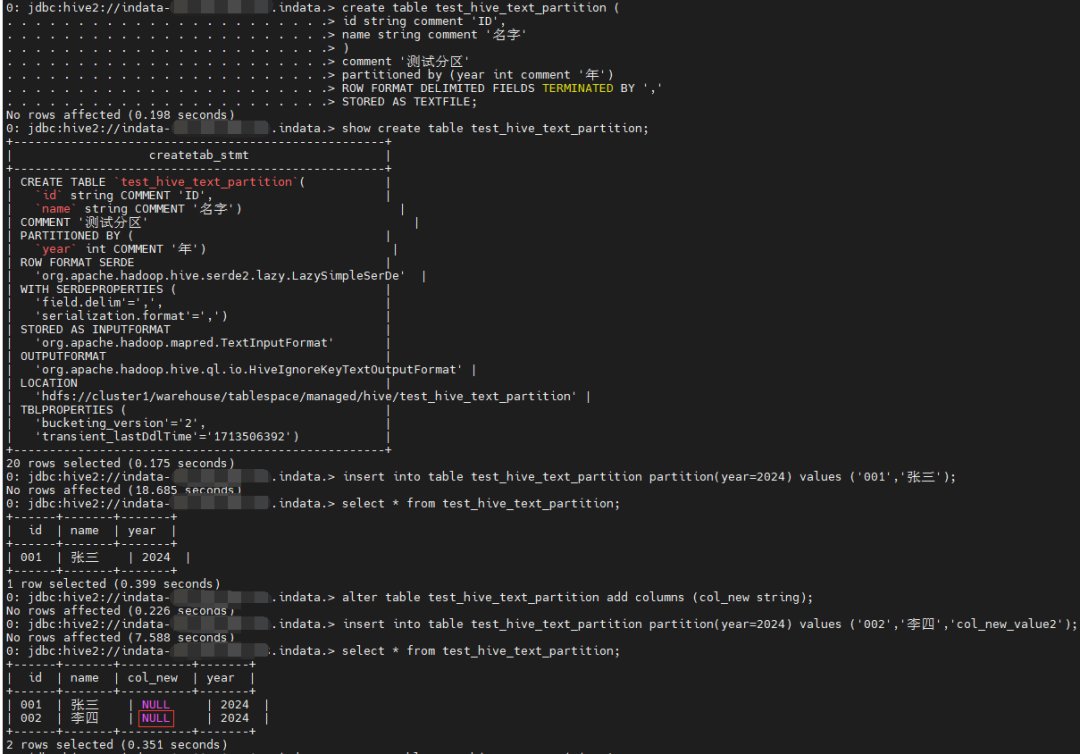
但是对应的数据文件实际是有内容的:

Parquet 分区表
建表
create table test_hive_parquet_partition (
id string comment 'ID',
name string comment '名字'
)
comment '测试分区'
partitioned by (year int comment '年')
STORED AS PARQUET;
插入数据
insert into table test_hive_parquet_partition partition(year=2024) values ('001','张三');
查询
select * from test_hive_parquet_partition;
新增字段
alter table test_hive_parquet_partition add columns (col_new string);
插入数据
# 已有分区
insert into table test_hive_parquet_partition partition(year=2024) values ('002','李四','col_new_value2');
# 新增分区
insert into table test_hive_parquet_partition partition(year=2025) values ('003','王五','col_new_value3');
查询新增列新增数据是否正常
select * from test_hive_parquet_partition;
可以看到对于已有分区新增字段对应的内容为空,新增分区新增字段对应的内容正常。
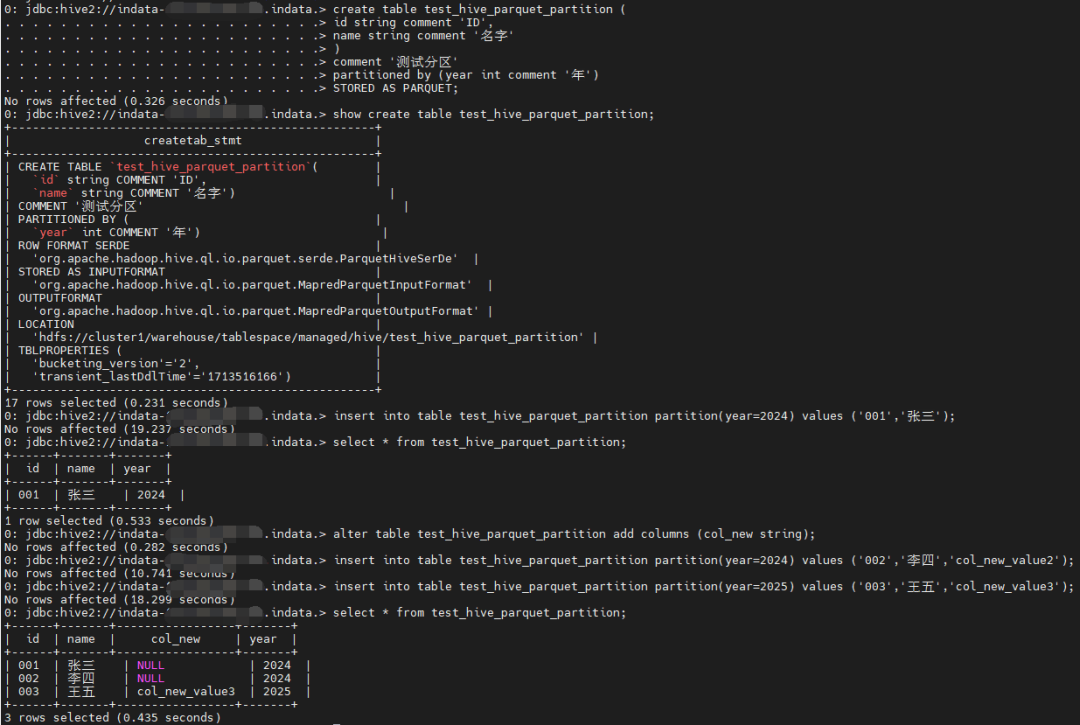
对应的parquet文件新增字段也不为空
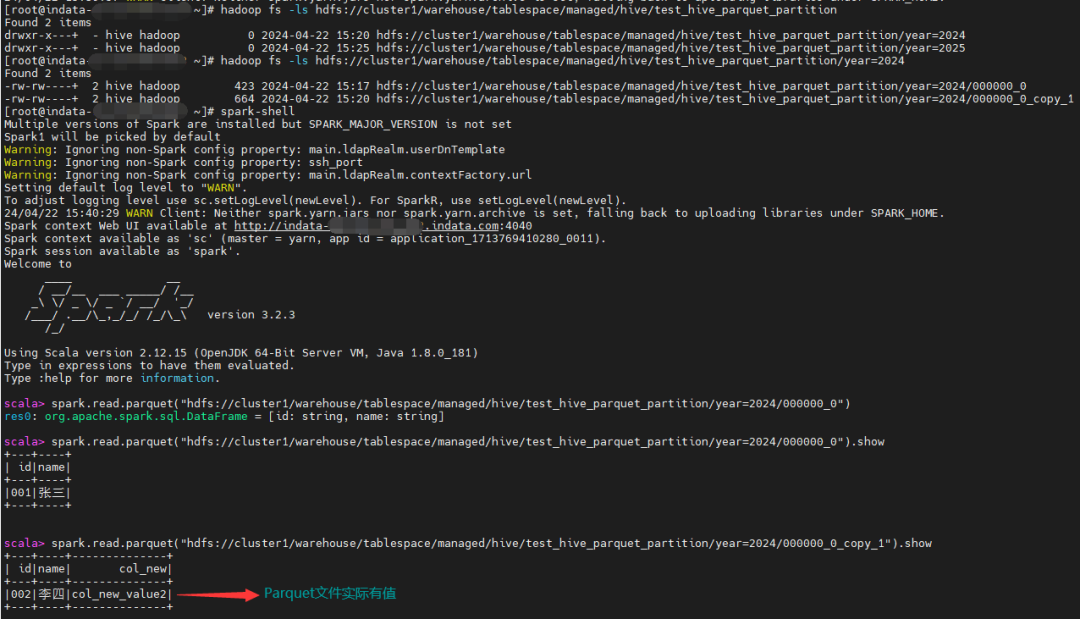
问题总结
对于某些文件类型,如ORC不存在该问题,而对于 Parquet、Text ,只有在已有分区下插入数据时,新增字段查询才为 NULL, 新增的分区正常。
问题解决
1、新增字段时添加 cascade
关键字,级联应用到分区表的所有分区
alter table test_hive_parquet_partition add columns (col_new string) cascade;
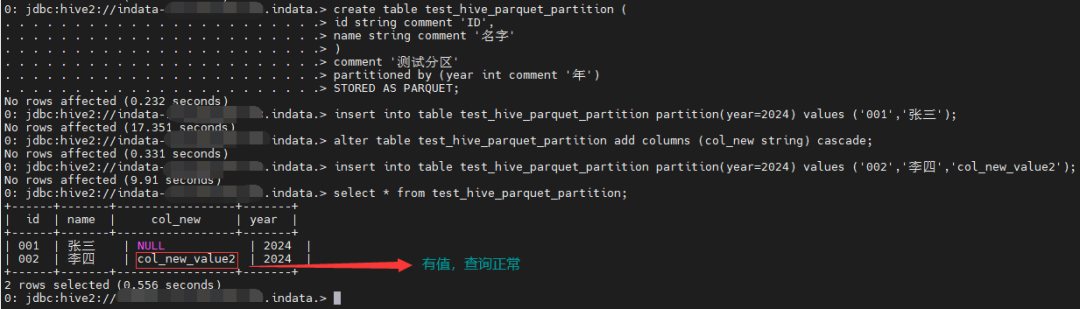
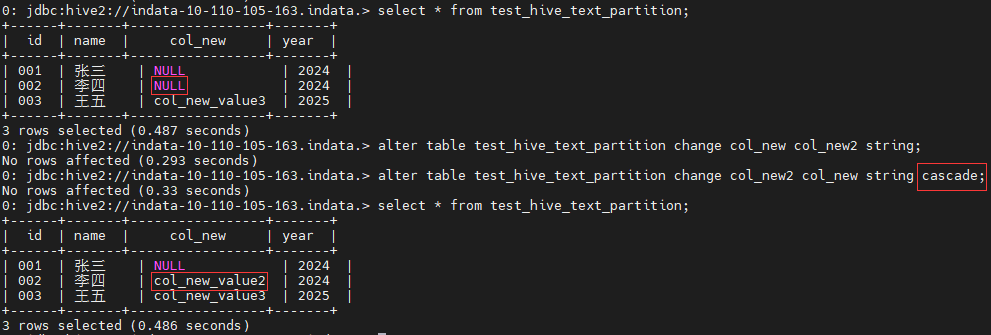
2、如果新增字段时忘了添加 cascade
,则可以通过改名的方式解决。
alter table test_hive_text_partition change col_new col_new2 string;
alter table test_hive_text_partition change col_new2 col_new string cascade;
CASCADE
仅供参考

参考
https://baijiahao.baidu.com/s?id=1724926871601854322&wfr=spider&for=pc
https://blog.csdn.net/MyNameIsWangYi/article/details/136022818
相关阅读
🧐 分享、点赞、在看,给个3连击呗!👇
