基于时序数据和机器学习的
耕林园草自动提取
耕地资源---保障粮食安全的基础
众所周知,民以食为天,耕地资源无疑是撑起这片天的基础,只有守住一定数量的耕地,才能保障中国粮食安全。而随着人口的增加,城镇化、工业化进程的不断加快和部分地区由于经济利益等因素驱动,出现耕地“非农化”、“非粮化”倾向,耕地逐年减少,已经迫近18亿亩红线。为此,国务院办公厅于2020年下半年先后印发《关于坚决制止耕地“非农化”行为的通知》和《关于防止耕地“非粮化”稳定粮食生产的意见》,坚决守住耕地红线。为了开展耕地资源的保护,采用卫星影像对土地利用分类进行研究,成为了近几年遥感领域的研究热点。我们以河北保定市安国市为实例,探索哨兵二号影像在耕、林、园、草等图斑的自动提取。
遥感与地理信息系统一体化
随着空间信息市场的快速发展,遥感和GIS从以往的相互独立到如今的紧密结合,遥感影像为GIS的基础,GIS帮助提升遥感影像的利用价值,遥感与地理信息系统一体化也逐渐成为一种发展趋势,易智瑞公司的桌面端产品GeoScene Pro和服务器端产品GeoScene Enterprise从整个软件构架体系上实现了遥感和GIS的无缝结合,为遥感和GIS的一体化集成提供了最佳的解决方案。在遥感影像方面,GeoScene具有影像读取、可视化与探索、影像管理、地图生产和影像分析五大关键能力。
我们以耕林园草的自动提取这一应用场景为切入点,体验GeoScene Pro的影像分析能力。
研究区概况
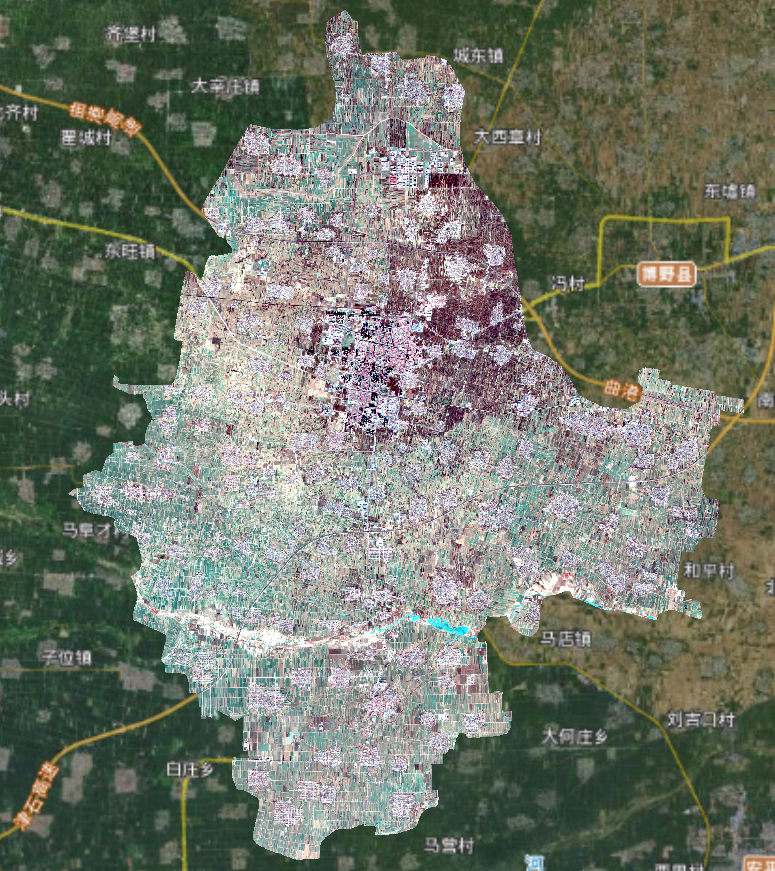
研究区位于中国河北省保定市安国市,其地处华北平原腹地,位于北纬38°15′,东经115°10′至115°29′之间。该区域的土地利用类型以耕地为主,包括小麦、豆类等主要粮食作物,和药材、棉花、油料作物等经济作物;其他土地利用类型包括林地、园地、草地、水体、建设用地等。
数据源
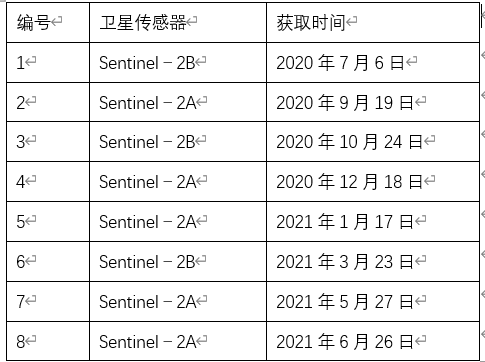
本研究选取Sentinel-2A/B影像共计8景,获取时间段为2020年7月到2021年6月,空间分辨率10 m,影像经过了正射纠正,质量较好,无条带噪声且覆盖整个研究区,均由欧洲航天局官网下载,获取到的8 景影像数据如表所示。
分类方法
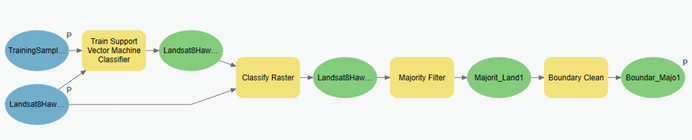
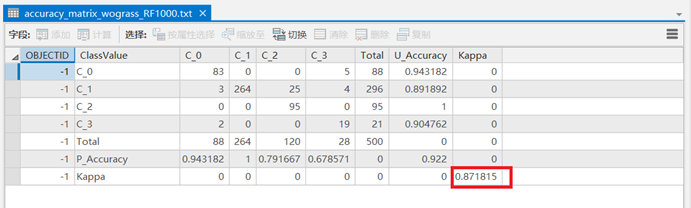
耕、林、园、草具有细碎并且形式多样、类型复杂、异物同谱等特点,给耕、林、园、草自动提取造成了难度,基于单时相数据的提取效果较差,因此我们采用时序数据结合随机森林的分类方法,实现耕、林、园、草的自动提取,提高分类的精度。首先,利用多时相的影像数据来构建NDVI时序数据集,然后结合随机森林和支持向量机两种分类算法进行耕、林、园、草的提取,最后进行精度评定,其中随机森林的Kappa系数达到了0.871815。
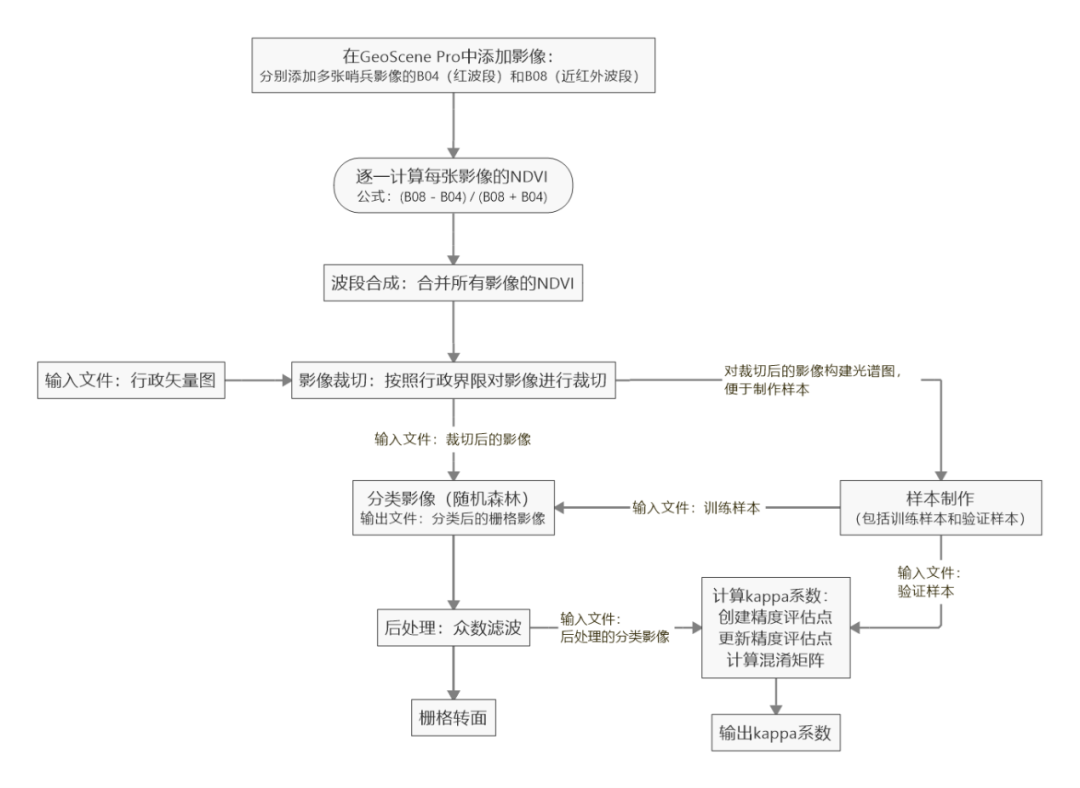
GeoScene Pro提供了计算NDVI、波段合成、影像裁切、查看时序影像光谱图、样本制作、影像分类、后处理(众数滤波),以及精度评定,和栅格转面等工具。具体流程图如下所示:
耕林园草提取依据
NDVI即归一化植被指数,是近红外波段的反射值与红光波段的反射值之差比上两者之和,NDVI=(NIR-RED)/(NIR+RED),能够有效区分绿色植被信息和土壤背景信息。NDVI数值位于[-1,1]之间,负值表示地面覆盖为云、水、雪等,对可见光高反射;0表示有岩石或裸土等,NIR和RED近似相等;正值,表示有植被覆盖,且随覆盖度增大而增大。
基于时序数据和随机森林来提取耕、林、园、草,最重要的依据就是,不同地物类别多时相NDVI的特征曲线的独特性。
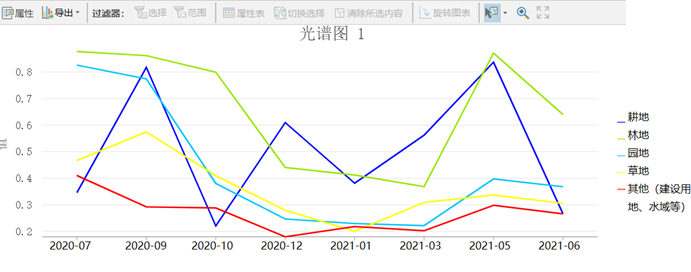
1) 耕地存在间作,轮作,并且农作物类型复杂,可以根据NDVI的多样性,以及耕地纹理的规整性来判断为耕地;
2) 林地NDVI 5月开始上升,7月开始下降,并且NDVI值较高;
3) 园地NDVI 5月开始上升,9月到达顶峰,NDVI低于林地;
4) 草地 NDVI 曲线跟林地相似,NDVI低于林地;
5) 其他:水域:NDVI低于0,并且保持全年平缓;建筑物:NDVI较低,并且全年几乎无变化。
具体流程
1. 启动GeoScene Pro新建工程
启动 GeoScene Pro。如果出现提示,请使用您获得许可的帐户进行登录,如果没有许可,可以联系客服购买。
GeoScene Pro 随即打开启动画面。选择地图来新建一个工程,输入名称和路径之后点击确定。
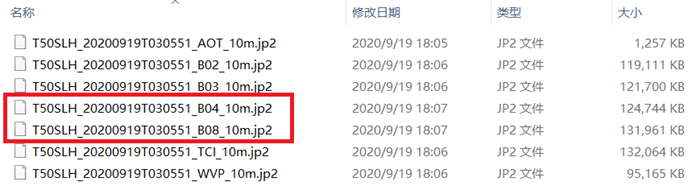
2. 影像的加载
打开哨兵影像所在的文件夹,选中B04(红波段)和B08(近红外)两个波段,拖拽到GeoScene Pro的图层中,即可加载。
3. 逐一计算每张影像的NDVI
以景为单位,逐一计算每张影像的NDVI,并输出多张影像的NDVI。
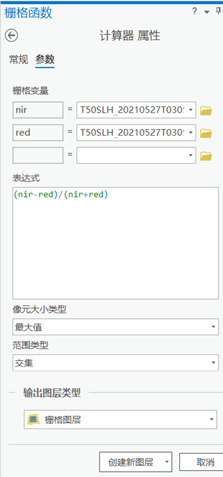
步骤:依次选择影像 –> 栅格函数 –> 数学分析 –> 计算器,来打开栅格计算器。
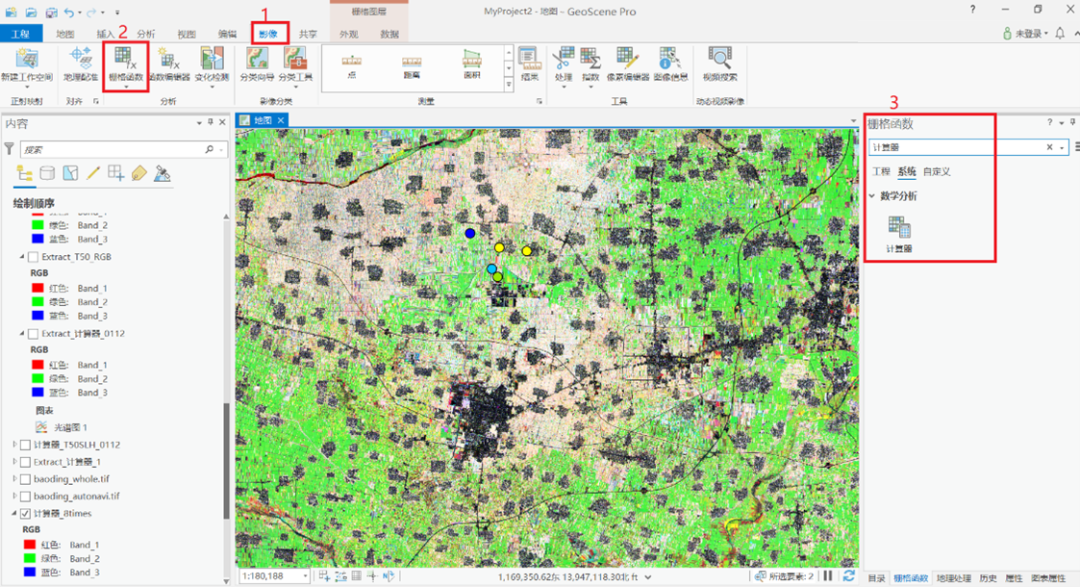
参数设置:
在栅格变量左边输入nir变量名,右边选取对应的波段号为b08的影像
再次以同样的方式输入red和对应的波段为b04影像
在表达式一栏中输入计算NDVI的表达式(nir - red) / (nir + red)
点击创建图层来生成NDVI
之后依次计算所有时期的NDVI
4. 波段合成:合并所有影像的NDVI
多波段的合成是为了便于直接提取每个像素点对应的所有波段的NDVI的值。
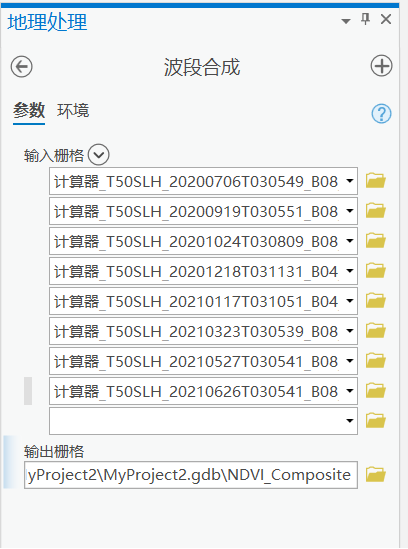
步骤:地理处理 –> 栅格处理 –> 波段合成
5. 影像裁切:按照行政界限对影像进行裁切
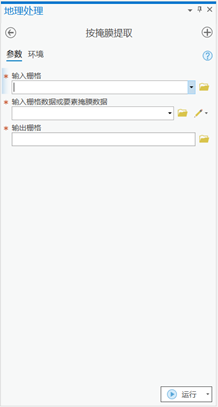
将安国的矢量行政边界加载到GeoScene Pro中,在地理处理 –> 空间分析工具 –> 提取分析 –> 按眼膜提取。
参数设置:
输入栅格:输入待裁剪的影像(上一步合成的NDVI影像)
输入栅格或要素掩膜数据:输入矢量边界文件
输出栅格:输入裁剪结果的路径和文件名
6. 制作样本
裁切后的影像在Geoscene Pro中构建光谱图,依据耕林园草NDVI的先验知识,辅助哨兵自带的RGB影像,和同区域的其他高精度正射影像,制作样本,包括训练样本和验证样本,具体制作流程如下:
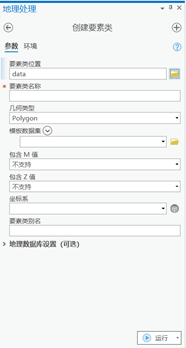
a) 创建两个矢量面文件,一个作为训练样本,一个作为测试样本。其中训练样本是为了训练分类,测试样本为了测试模型的准确性。通过“视图-目录窗格-找到存放文件夹-右击新建shape file文件”打开创建要素类。
参数设置:
要素类位置:输入具体存放路径
要素类名称:输入名称加.shp文件后缀
几何类型:polygon
b) 对两个矢量(训练和测试)分别开始选取样本,即耕林园草和其他类别。以训练集为例,通过选中“创建的矢量-编辑-创建要素-选中待编辑的要素-选择任意多边形”来打开选取样本工具。
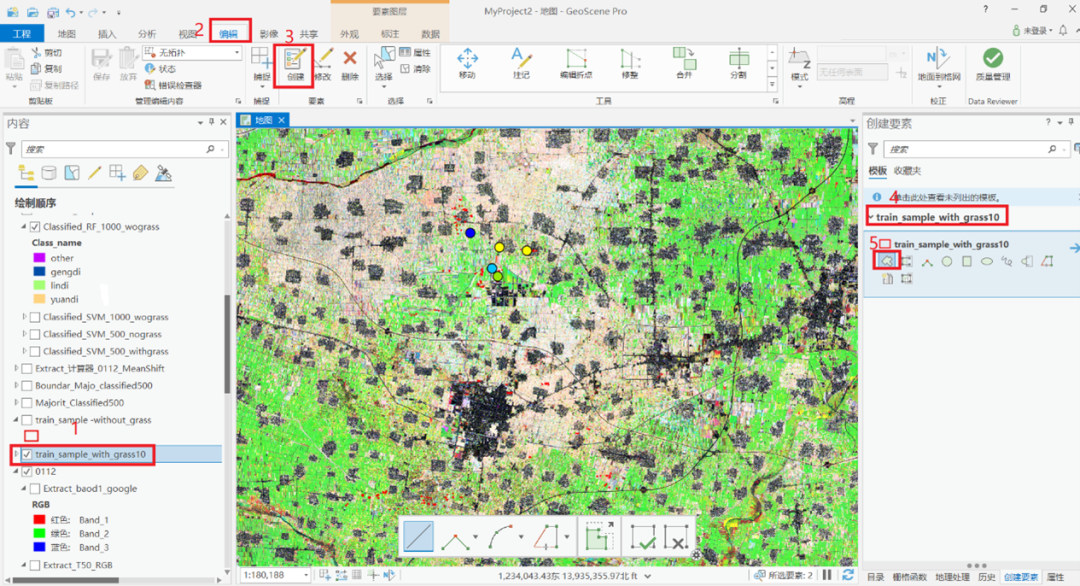
样本选取和保存:
鼠标左击图层,确认一点,之后继续左击,完成时连续左击两次,画完一个面
之后分布均匀的画上一百个
画完之后,点击保存即可
最终程序会在这些图形中选取一个或多个点作为样本集
增加字段:样本选好之后,右击矢量样本打开属性表来增加字段。目的是为了符合该工具的输入格式。
具体操作:
1) 点击属性表的添加,添加“classname”和“classvalue”字段。类型分别是文本和长整型。随后保存。
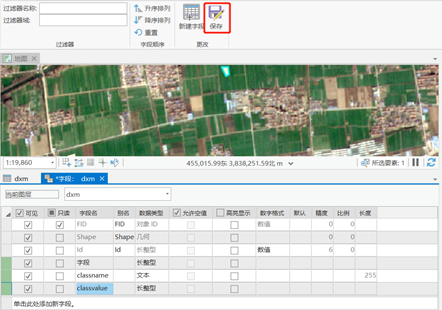
2) 选中classname,点击计算,输入‘gengdi’,将选中的耕地样本命名为‘gengdi’,同样的方式,将classvalue改为1。
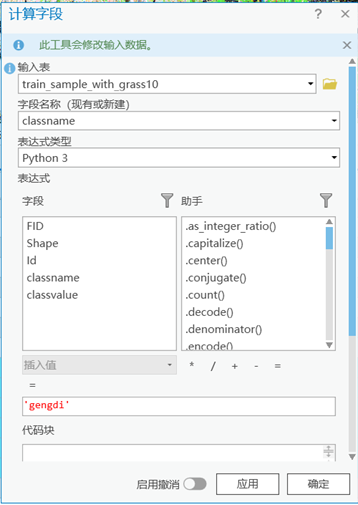
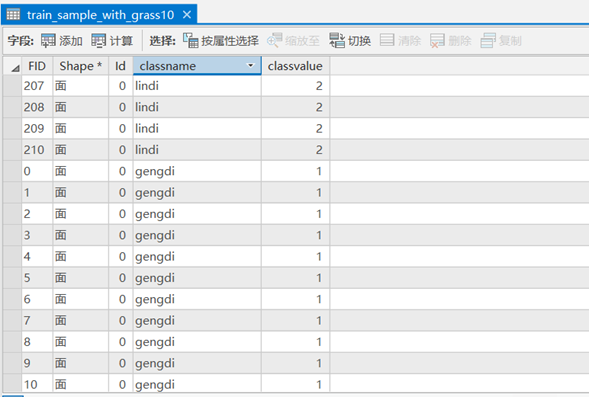
3) 如上同样的操作分别选取林地、园地、草地、其他,设置相应的classname和classvalue。最终结果如下图所示。
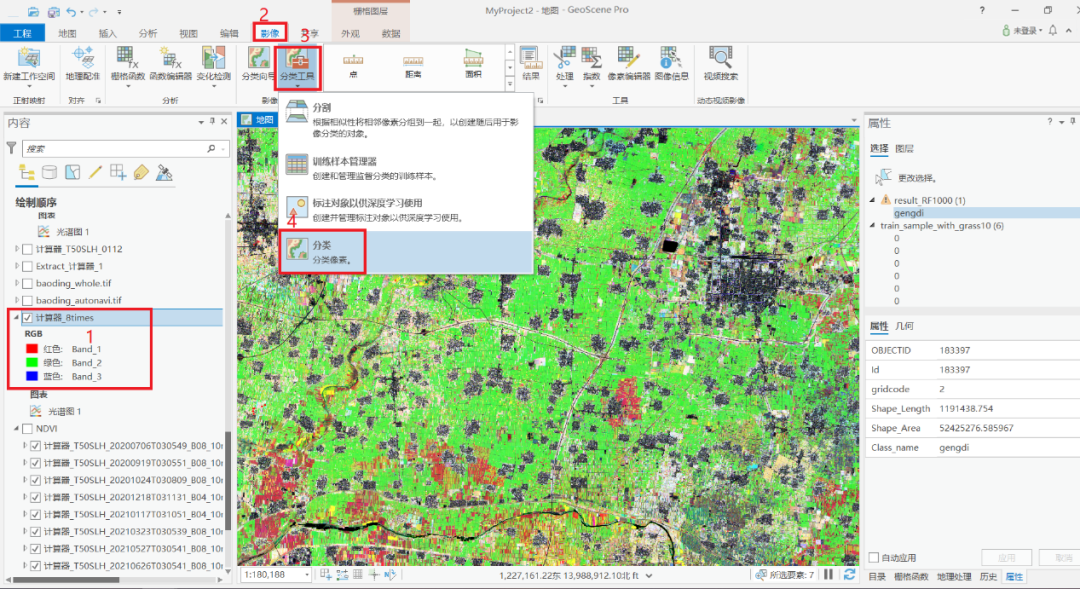
7. 基于随机森林的分类影像
选中待分类影像,即合成的多时相NDVI图,选择影像-分类工具-分类。
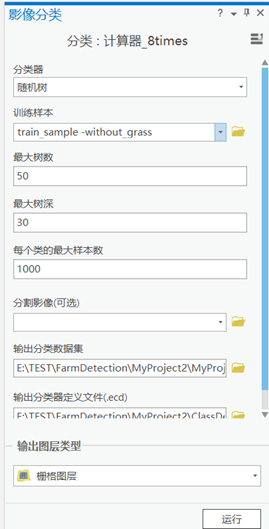
参数设置:
分类器:选择随机树(可选支持向量机作为比较)算法
训练样本:输入样本矢量文件
每个类的最大样本数本课程中选了1000
其余参数默认
8. 后处理(众数滤波)
具体步骤:地理处理 -> 工具箱 -> 空间分析工具 -> 栅格综合 -> 众数滤波
参数设置:
输入栅格:步骤7得到的分类栅格影像
输出栅格:自定义输出影像
其他使用默认参数
9. 计算Kappa系数
为了确保训练的模型是否以达到可以接受的精度,计算评价指标Kappa系数。
a) 创建精度评估点
这一步是为了确保训练的模型是否以达到可以接受的精度。评价指标是Kappa系数,Kappa系数用于一致性检验,也可以用于衡量分类精度,Kappa系数的计算是基于混淆矩阵的。我们将通过创建精度评估点和更新精度评估点来计算混淆矩阵和Kappa系数。
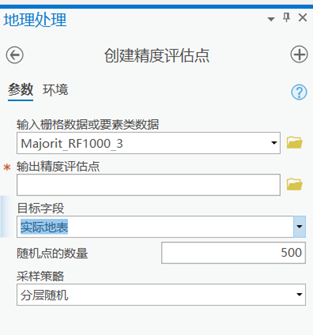
打开创建精度评估点工具。
参数设置:
输入栅格数据或要素类数据:输入测试样本的矢量文件
输出精度评估点:输入保存的路径、名称和‘.shp’后缀
目标字段:实际地表
随机点数量选500,也可默认或自己定
其他参数默认即可
b) 更新精度评估点
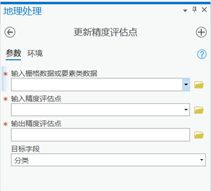
打开更新精度评估点工具。目的是将识别的结果和对应的自己的标注的结果放在一起,便于计算混淆矩阵。

参数设置:
输入栅格数据或要素类数据:输入分类结果文件
输入精度评估点:输入精度评估点矢量文件
输出精度评估点:输入更新后的精度评估点路径、名称和后缀‘.shp’
目标字段:选择分类
c) 计算混淆矩阵
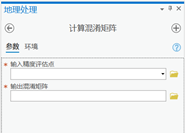
打开计算混淆矩阵工具。

参数设置:
输入精度评估点:输入更新精度评估点矢量文件
输出混淆矩阵:输入计算结果的输出路径、名称以及后缀‘.txt’
将输出包含混淆矩阵和Kappa系数的表。
10. 栅格转面
在地理处理中搜索栅格转面,打开栅格转面。
参数设置:
输入栅格:第8步后处理后的影像
字段:classname
输出:自定义分类后图斑
分类精度评价和分析
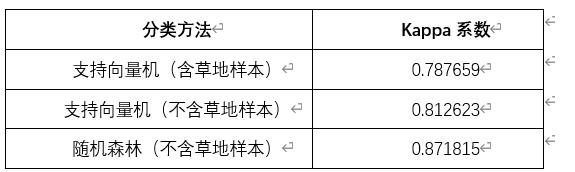
由于草地较少,草地样本为20,其他类型样本都为100,草地样本较少影响了整体分类的精度。将草地样本删除后,分类精度明显提高。因此,为了得到最佳的分类效果,尽量保证每个类别的样本数一致。
分别采用了支持向量机和随机森林两种机器学习算法进行耕、林、园、草的分类,无论是从直观效果,还是Kappa系数上,随机森林的分类精度更高,分类结果更为准确。

结论
在充分考虑地物的时序变化趋势基础上,加入时序数据能够有效地解决同谱异物的问题。将时序数据与随机森林相结合的耕、林、园、草自动提取路线,具有分类速度快、处理时间段,标注样本不过分依赖影像分辨率等优点,对耕、林、园、草的提取有很好的适用性。
GeoScene Pro不仅提供了一系列专业的栅格分析工具,而且提供Model Builder建模工具,可将相关分析工具串联成一个工作流,一键式输出结果,简化工作流程,提高工作效率。