




前言
在之前的文章中,我们探讨了使用 LlamaIndex 查询 NebulaGraph 时的 7 种查询策略。在本文中,我们将尝试使用全新的 Llama Pack for Neo4j,并了解如何在 Neo4j 中应用这 7 种查询策略。
首先,让我们了解一下Neo4j,并对比 NebulaGraph 。
NebulaGraph vs Neo4j
可扩展性
NebulaGraph:具有水平可扩展性。它是一个分布式图形化数据库,可以在集群中添加更多节点来实现横向扩展。支持跨多个服务器的数据自动分片。非常适合用于处理数十亿个顶点和数万亿条边的大型数据集。
Neo4j:Neo4j 随着分片数据的增长而扩展,通过分片将单个逻辑数据库划分为多个较小的数据库。在 Autonomous Clusters 上运行分片,可实现对非常大的图的无限横向扩展。
性能
NebulaGraph:针对大型数据集设计,以实现快速查询执行。
Neo4j:提供良好的性能,尤其适用于较小的数据集。然而,在非常大型图的情况下,可能不如 NebulaGraph 高效。
查询语言
NebulaGraph::使用 nGQL 的查询语言,基于 openCypher。nGQL类似于 SQL,但专门设计用于图数据库。它提供了一组丰富的功能用于遍历和分析图形数据。
Neo4j:使用 Cypher 的查询语言,同样是一种专门用于图的语言。
用例
NebulaGraph::适用于需要高度可伸缩性和性能的应用,如社交网络分析、欺诈检测和知识图管理。
Neo4j:适用于需要性能和易用性平衡的应用,如实时推荐、主数据管理和身份和访问管理。
部署
NebulaGraph:可以在本地部署或在云中部署,支持多种部署选项,包括 Docker 和 Kubernetes。
Neo4j:也可以在本地或云中部署,提供名为 Neo4j Aura 的托管云服务。
社区和支持
NebulaGraph:拥有不断壮大的用户和开发者社区,提供文档、教程和支持论坛。
Neo4j:拥有更大更成熟的社区,提供广泛的文档、培训课程和商业支持选项。
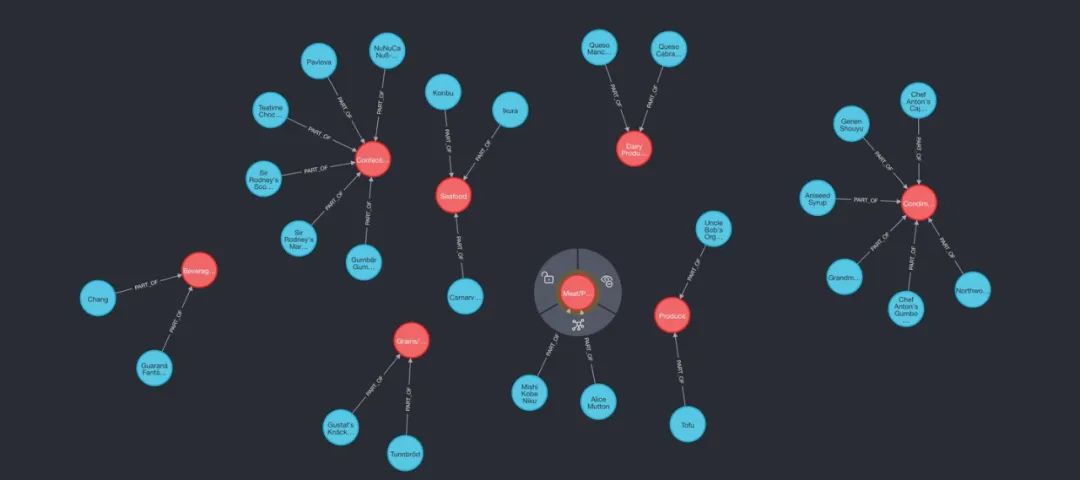
总体而言,NebulaGraph 适用于需要高度可伸缩性和性能的应用,而 Neo4j 适用于需要性能和易用性平衡的应用。
Neo4j 知识图查询的 7 种策略
与 NebulaGraph 相同,这 7 种查询策略也可以应用于 Neo4j。关于每种策略的详细解释,请参考文末参考链接。接下来基于 Neo4j 的 7 种策略:
1、KG 基于向量的实体检索
这种查询策略使用向量相似性查找知识图中的实体,提取链接的文本块,并可选地探索关系。
query_engine = neo4j_index.as_query_engine()
