





过去一周真是惊喜连连。AI社区发布了多款备受瞩目的新模型:
StableLM-2–12B
WizardLM-2–7B 🧙♂️
Meta-Llama-3–8B 和 70B 🦙
可能是因为 StableLM 的架构相对更复杂,至今还未推出其量化版本……但是,对于 WizardLM-2 和 Llama-3,我们在 Hugging Face 上已经可以看到 GGUF 模型二进制文件。
你需要准备什么
我们将使用 llama.cpp 库和 python 在本地快速启动模型。这只是一个初步的测试设置,虽然只有文本界面……但保证百分之百可行。
需要安装的依赖
我们只需安装两个库:
只使用CPU
创建一个新目录(我创建的是 TestLlama3),进入该目录,并打开终端窗口。
python -m venv venvvenv\\Scripts\\activate # 激活虚拟环境
现在你已经拥有了一个干净的 Python 环境,我们将安装 llama-cpp-python 和 OpenAI 库:
pip install llama-cpp-python[server]==0.2.62pip install openai
注意:之所以需要安装 OpenAI 库,是因为我们将利用 llama-cpp 附带的兼容 OpenAPI 服务器。这将为你未来的 Streamlit 或 Gradio 应用做好准备😁。
如果你有 Nvidia GPU
如果你拥有 NVidia GPU,在执行 pip 命令前,你需要设置编译器标志:
$env:CMAKE_ARGS="-DLLAMA_CUBLAS=on"pip install llama-cpp-python[server]==0.2.62pip install openai
从Hugging Face下载Llama-3–8B GGUF
这才是你真正需要的:以GGUF格式压缩的模型权重。
我尝试了几个版本,但截至目前,唯一一个配备了固定分词器和聊天模板的版本是这个库:
Meta-Llama-3-8B-Instruct-GGUF:https://huggingface.co/QuantFactory/Meta-Llama-3-8B-Instruct-GGUF
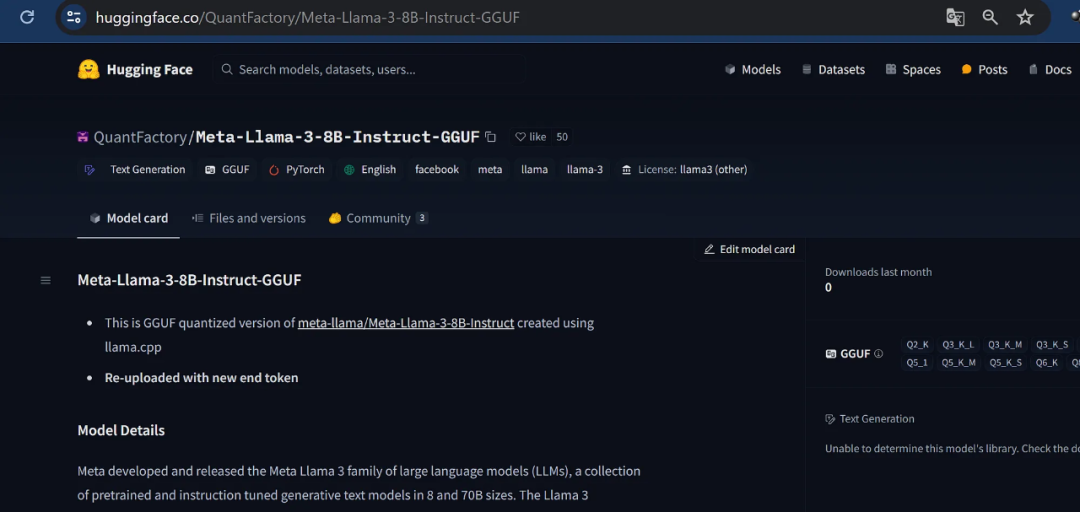
前往HuggingFace的这个链接,点击“文件和版本”并选择Q2_K(仅3Gb)或Q4_K_M(4.9Gb)。第一个虽然不那么精确但速度更快,第二个在速度和精度上达到了较好的平衡。
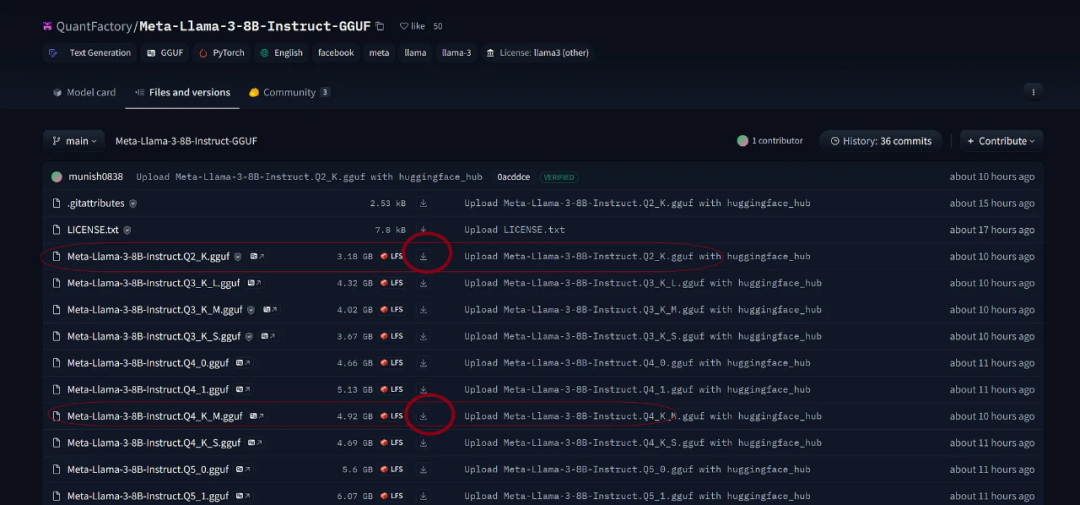
在你的主项目目录中创建一个名为model的文件夹,并将GGUF文件下载到该文件夹内。

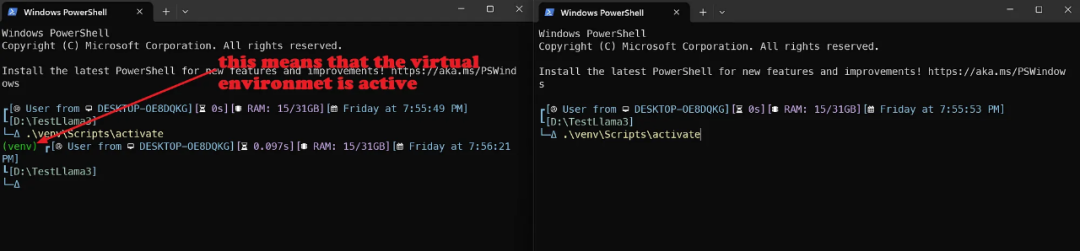
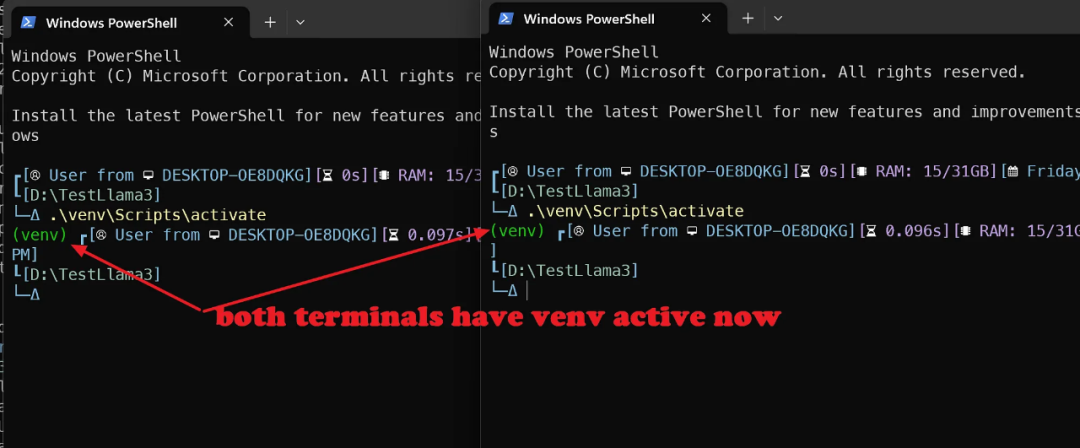
双终端策略
这里有个小技巧。最简单的方法是在一个终端窗口(激活虚拟环境后)运行 llama-cpp-server,在另一个终端窗口(同样激活虚拟环境后)运行与 API 交互的 python 文件。
因此,在主目录中打开另一个终端窗口并激活虚拟环境 venv。
Python文件
我们的 Python 文件(我称之为 Llama3-ChatAPI )是一个文本界面程序。它接收我们的提示输入,并向API服务器发送/接收指令,然后获取响应。
这很方便,因为它完全独立于你正在使用的模型。让我们来看一看:
# 在你的终端与智能助手聊天from openai import OpenAI# 指向本地服务器client = OpenAI(base_url="<http://localhost:8000/v1>", api_key="not-needed")
这里我们调用了 OpenAI 库,该库内置了标准API调用的类,我们实例化了客户端。
然后我们用第一对消息格式化消息历史:Python 字典的第一个条目是系统消息,第二个是用户提示,要求模型介绍自己。
history = [{"role": "system", "content": "你是一个智能助手。你总是提供既正确又有用的经过深思熟虑的回答。"},{"role": "user", "content": "你好,请向第一次打开这个程序的人介绍一下自己。请简洁明了。"},]print("\\033[92;1m")
这个奇怪的打印语句是一个ANSI转义码,用来改变终端颜色(如果你想了解更多,可以阅读这里:https://blog.stackademic.com/how-to-quickly-test-a-new-llm-without-wasting-time-17d1aa0ef858)。
现在我们开始一个while循环:基本上,我们总是请求用户的提示,并从我们的Meta-Llama-3–7B-instruct模型生成回复,直到我们说退出或退出。
while True:completion = client.chat.completions.create(model="local-model", # 这个字段目前未使用messages=history,temperature=0.7,stream=True,)new_message = {"role": "assistant", "content": ""}for chunk in completion:if chunk.choices[0].delta.content:print(chunk.choices[0].delta.content, end="", flush=True)new_message["content"] += chunk.choices[0].delta.contenthistory.append(new_message)print("\\"\\033[91;1m"userinput = input("> ")if userinput.lower() in ["quit", "exit"]:print("\\033[0mBYE BYE!")breakhistory.append({"role": "user", "content": userinput})print("\\033[92;1m")
首次调用是为了完成聊天:实际上,我们已经有了一个关于模型的问题
“你好,请向第一次打开这个程序的人介绍一下自己。请简洁明了。”
我们使用了 Stream 方法,因此 Python 将在 API 调用发送响应令牌的同时开始逐个显示响应。
注意:如果你没有 GPU,这可能需要几秒钟的时间,具体取决于提示的长度
最后,我们请求用户输入以准备开始新一轮:我们将新的提示添加到现有的聊天历史(history)中,以便Llama3可以开始处理它。
开始运行
在第一个终端窗口,激活虚拟环境后运行以下命令:
# 仅使用CPUpython -m llama_cpp.server --host 0.0.0.0 --model .\\model\\Meta-Llama-3-8B-Instruct.Q2_K.gguf --n_ctx 2048# 如果你有NVidia GPUpython -m llama_cpp.server --host 0.0.0.0 --model .\\model\\Meta-Llama-3-8B-Instruct.Q2_K.gguf --n_ctx 2048 --n_gpu_layers 28
这将启动与 OpenAI 标准兼容的 FastAPI 服务器。你应该会看到类似这样的东西:
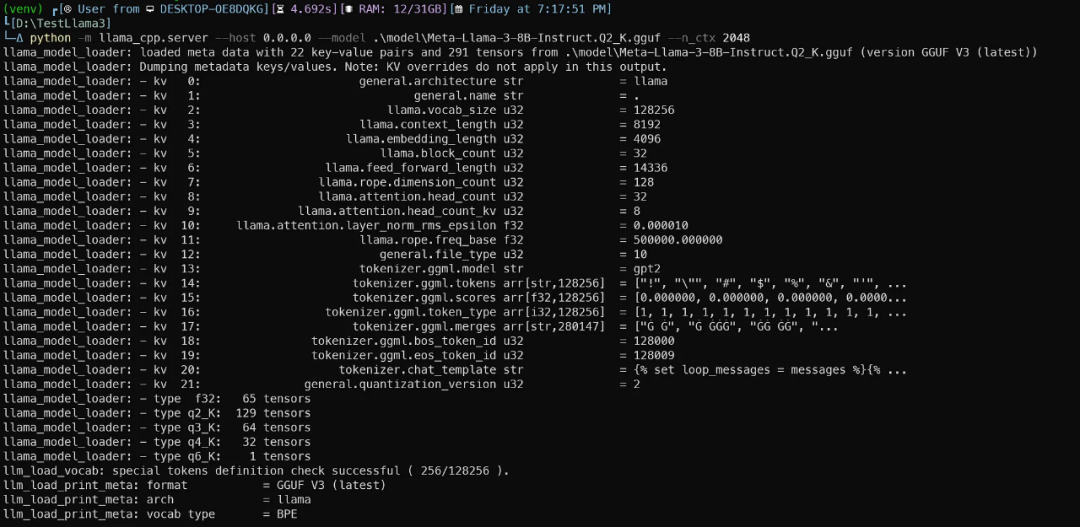
服务器准备就绪时,Uvicorn会用美丽的绿色灯光消息通知你:
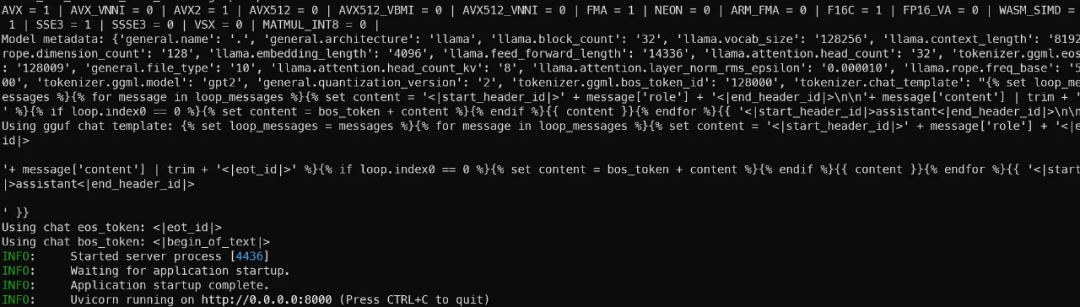
注意:我在这里只设置了2048个令牌作为上下文:实际上Llama3能够处理高达8192个令牌的上下文,但这同样也会消耗RAM或VRAM,所以我们暂时保持较低的设置(以免GPU崩溃)
注意2:这个8B参数模型实际上有33层,但我只将其中28层设置为GPU。试试看你自己能在不崩溃的情况下卸载多少层😁。
注意3:在这个例子中我使用的是Q2版本Meta-Llama-3–8B-Instruct.Q2_K.gguf。更换为Q4_K_M文件名以运行4位量化版本
创建另外一个终端,该窗口用于激活虚拟环境后运行
python .\\Llama3-ChatAPI.py
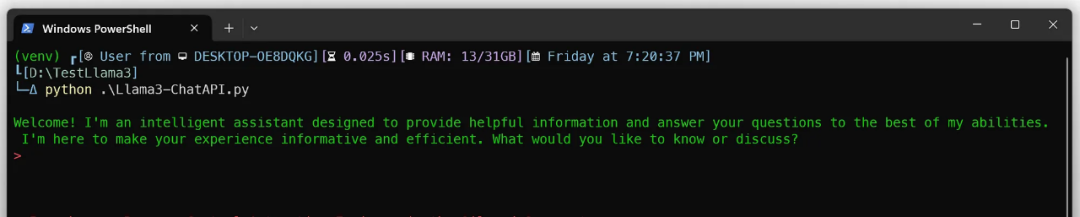
现在,你已经准备好了。随心所欲地提出任何问题。
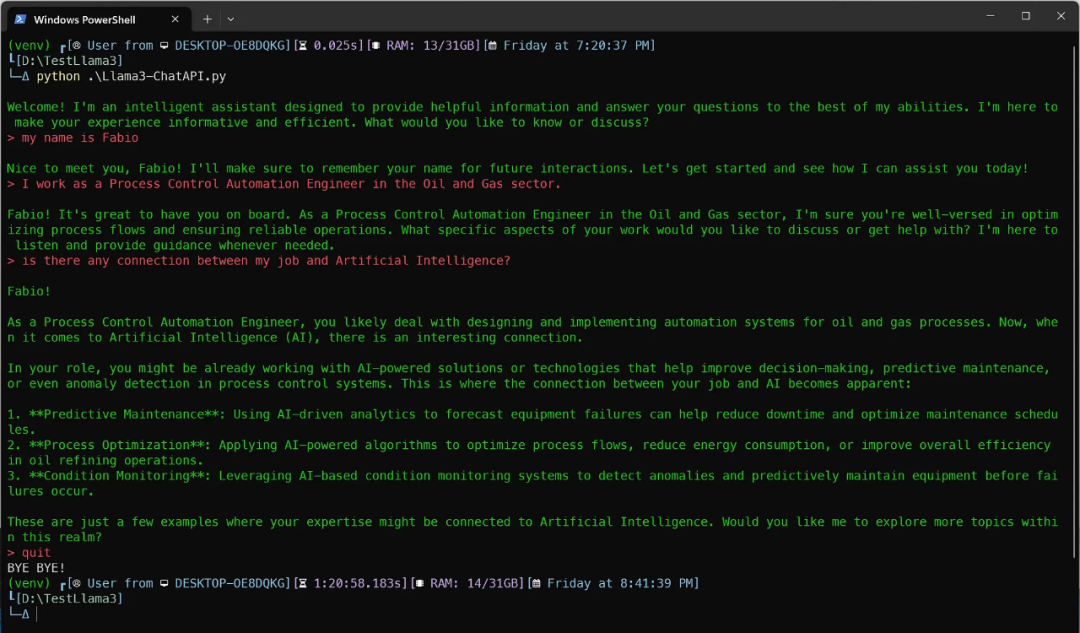
这是我与 Meta-Llama-3–8b-Instruct 的对话...
额外福利 — 你可以在Hugging Face Chat上免费运行它
如果你觉得麻烦或想尝试70B模型版本,你可以直接在HuggingFace Hub Chat这里进行:
HuggingChat:https://huggingface.co/chat/
资源:
Meta-Llama-3-8B-Instruct-GGUF:https://huggingface.co/QuantFactory/Meta-Llama-3-8B-Instruct-GGUF
ANSI转义码,用来改变终端颜色:https://blog.stackademic.com/how-to-quickly-test-a-new-llm-without-wasting-time-17d1aa0ef858
HuggingChat:https://huggingface.co/chat/
