




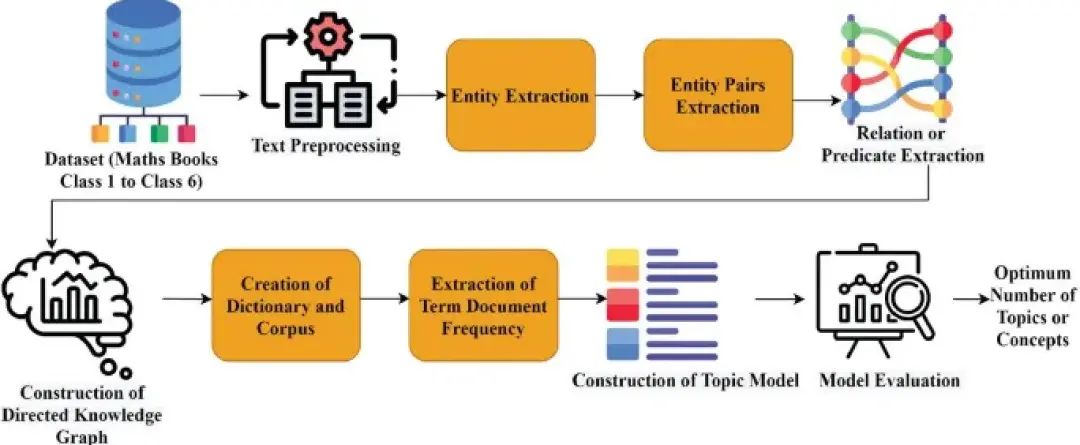
介绍
数据探索和知识可视化领域在不断发展,高级主题建模和直观的数据可视化工具之间的协同作用变得至关重要。BERTopic,一种前言主题建模框架,与 DataMapPlot,一种直观的数据可视化工具,他们两的整合在知识图谱形成领域迈出了重要一步。
定义
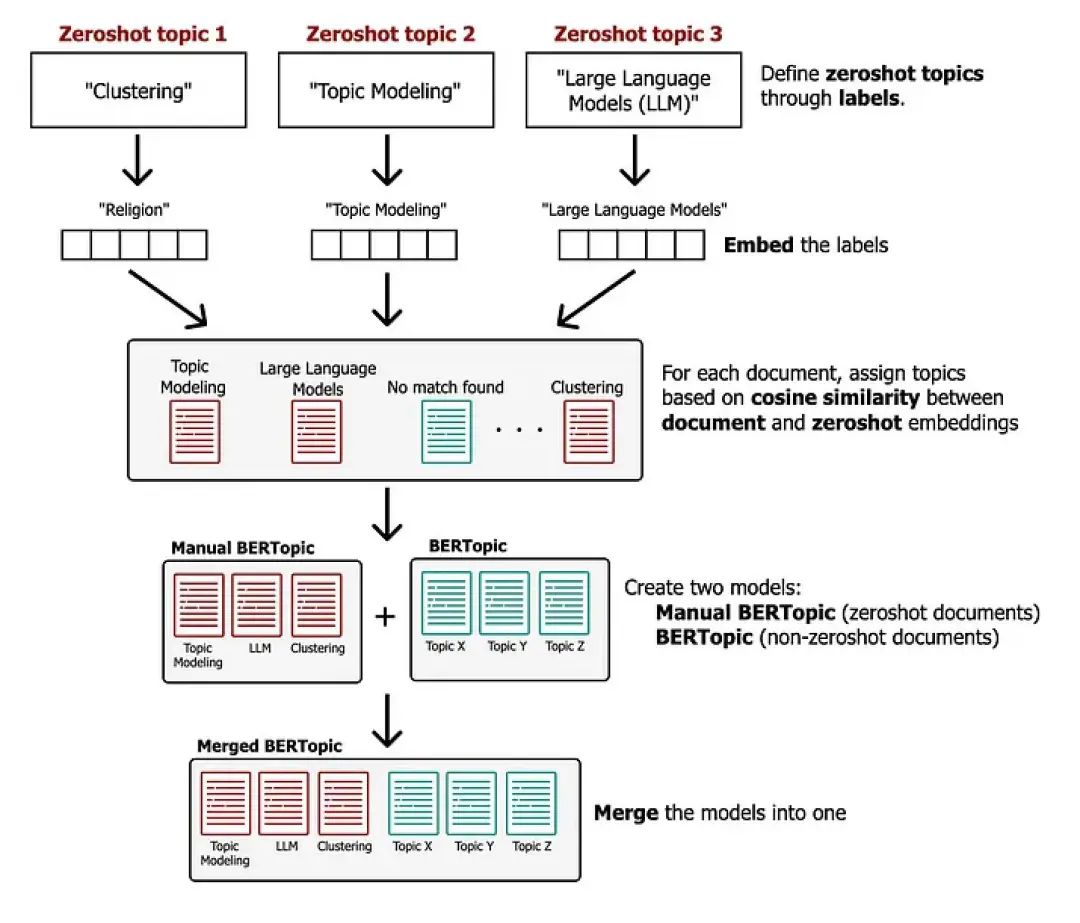
BERTopic:动态主题建模框架:BERTopic 提供了一种灵活且模块化的框架,适应各种用户需求。其模块化架构使用户能够构建适合其特定需求的主题模型,从而有效地与语言 AI 的最新进展保持一致。BERTopic v0.16 的发布引入了变革性功能,例如零样本主题建模、模型合并和对大型语言模型 (LLM) 的增强支持。
DataMapPlot:简化的数据可视化:作为 BERTopic 的补充,DataMapPlot 简化了数据映射的创建。它为用户提供了基本而强大的工具,可以毫不费力地生成标记数据图的静态图。通过轻松标记数据簇,DataMapPlot 可自动创建具有演示价值的绘图,为令人惊叹的视觉输出提供自定义选项。
整合优势
BERTopic 和 DataMapPlot 的集成融合了先进的主题建模功能和用户友好的数据可视化工具,具有许多优势:
全面的知识展示:BERTopic 灵活的主题建模与 DataMapPlot 的简化可视化相结合,可实现全面的知识表示。用户可以轻松浏览复杂的数据结构、发现错综复杂的关系并可视化主题集群,从而更全面地了解数据。
增强的可解释性和可访问性:将 BERTopic 的自适应主题建模与 DataMapPlot 的直观可视化相结合,有助于使复杂的数据结构更具可解释性。DataMapPlot 生成的可视化表示补充了 BERTopic 的见解,使更广泛的受众更容易获得数据驱动的发现。
流畅的工作流程整合:BERTopic 和 DataMapPlot 之间的协同作用简化了数据科学家和研究人员的工作流程。使用 DataMapPlot 轻松生成值得发表的绘图,补充了 BERTopic 的灵活性,促进了从数据建模到可视化表示的无缝过渡。
可定制的可视化选项:DataMapPlot 提供了用于调整视觉输出的可定制选项,这与 BERTopic 的模块化特性完美契合。这种集成允许用户根据特定偏好定制可视化效果,确保生成美观且信息丰富的数据地图。
扩展的分析能力:扩展的分析能力:通过将 BERTopic 的强大功能与 DataMapPlot 的可视化能力相结合,用户可以获得扩展的分析能力。这种集成使用户能够发现隐藏的模式,探索潜在的主题,并从复杂的数据集中获得有价值的见解。
BERTopic 和 DataMapPlot 的整合标志着朝着全面知识图谱构建迈出的重要一步,弥合了先进数据建模和用户友好可视化工具之间的鸿沟。
代码实现
我们将整合 BERTopic 和 DataMapPlot ,利用它们的功能来创建全面的主题模型并可视化数据聚类。
第 I 步:安装库
%%capture# BERTopic + llama-cpp-python!CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install llama-cpp-python!pip install bertopic datasets transformers# DataMapPlot!git clone <https://github.com/TutteInstitute/datamapplot.git>!pip install datamapplot/.# GPU-accelerated HDBSCAN + UMAP!pip install cudf-cu12 dask-cudf-cu12 --extra-index-url=https://pypi.nvidia.com!pip install cuml-cu12 --extra-index-url=https://pypi.nvidia.com!pip install cugraph-cu12 --extra-index-url=https://pypi.nvidia.com!pip install cupy-cuda12x -f <https://pip.cupy.dev/aarch64>
第二步:加载数据并下载模型
from datasets import load_dataset# ArXiv ML Documentsdocs = load_dataset("CShorten/ML-ArXiv-Papers")["train"]["abstract"]
!wget <https://huggingface.co/TheBloke/OpenHermes-2.5-Mistral-7B-GGUF/resolve/main/openhermes-2.5-mistral-7b.Q4_K_M.gguf># !wget <https://huggingface.co/TheBloke/dolphin-2.7-mixtral-8x7b-GGUF/resolve/main/dolphin-
2.7-mixtral-8x7b.Q3_K_M.gguf>
第三步:加载模型
from llama_cpp import Llama# Use llama.cpp to load in a Quantized LLMllm = Llama(model_path="openhermes-2.5-mistral-7b.Q4_K_M.gguf", n_gpu_layers=-1, n_ctx=4096, stop=["Q:", "\\n"])
第四步:使用 LLM 提示定制 BERTopic 并混合受 KeyBERT 启发的表示进行比较from bertopic.representation import KeyBERTInspired, LlamaCPPprompt = """ Q:I have a topic that contains the following documents:[DOCUMENTS]The topic is described by the following keywords: '[KEYWORDS]'.Based on the above information, can you give a short label of the topic of at most 5 words?A:"""representation_model = {"KeyBERT": KeyBERTInspired(),"LLM": LlamaCPP(llm, prompt=prompt),}
第五步:BERTopic
from sentence_transformers import SentenceTransformerfrom cuml.manifold import UMAPfrom cuml.cluster import HDBSCAN# from umap import UMAP# from hdbscan import HDBSCAN# Pre-calculate embeddingsembedding_model = SentenceTransformer("BAAI/bge-small-en")embeddings = embedding_model.encode(docs, show_progress_bar=True)# Pre-reduce embeddings for visualization purposesreduced_embeddings = UMAP(n_neighbors=15, n_components=2, min_dist=0.0, metric='cosine', random_state=42).fit_transform(embeddings)
#Define sub-modelsumap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine', random_state=42)hdbscan_model = HDBSCAN(min_cluster_size=400, metric='euclidean', cluster_selection_method='eom', prediction_data=True)
第六步:训练模型
from bertopic import BERTopictopic_model = BERTopic(# Sub-modelsembedding_model=embedding_model,umap_model=umap_model,hdbscan_model=hdbscan_model,representation_model=representation_model,# Hyperparameterstop_n_words=10,verbose=True)# Train modeltopics, probs = topic_model.fit_transform(docs, embeddings)
# Show topicstopic_model.get_topic_info()

第 7 步:使用 DataMapPlot 进行可视化
import PILimport numpy as npimport requests# Prepare logobertopic_logo_response = requests.get("<https://raw.githubusercontent.com/MaartenGr/BERTopic/master/images/logo.png>",stream=True,headers={'User-Agent': 'My User Agent 1.0'})bertopic_logo = np.asarray(PIL.Image.open(bertopic_logo_response.raw))
import datamapplotimport re# Create a label for each documentllm_labels = [re.sub(r'\\W+', ' ', label[0][0].split("\\n")[0].replace('"', '')) for label in topic_model.get_topics(full=True)["LLM"].values()]llm_labels = [label if label else "Unlabelled" for label in llm_labels]all_labels = [llm_labels[topic+topic_model._outliers] if topic != -1 else "Unlabelled" for topic in topics]# Run the visualizationdatamapplot.create_plot(reduced_embeddings,all_labels,label_font_size=11,title="ArXiv - BERTopic",sub_title="Topics labeled with `openhermes-2.5-mistral-7b`",label_wrap_width=20,use_medoids=True,logo=bertopic_logo,logo_width=0.16)
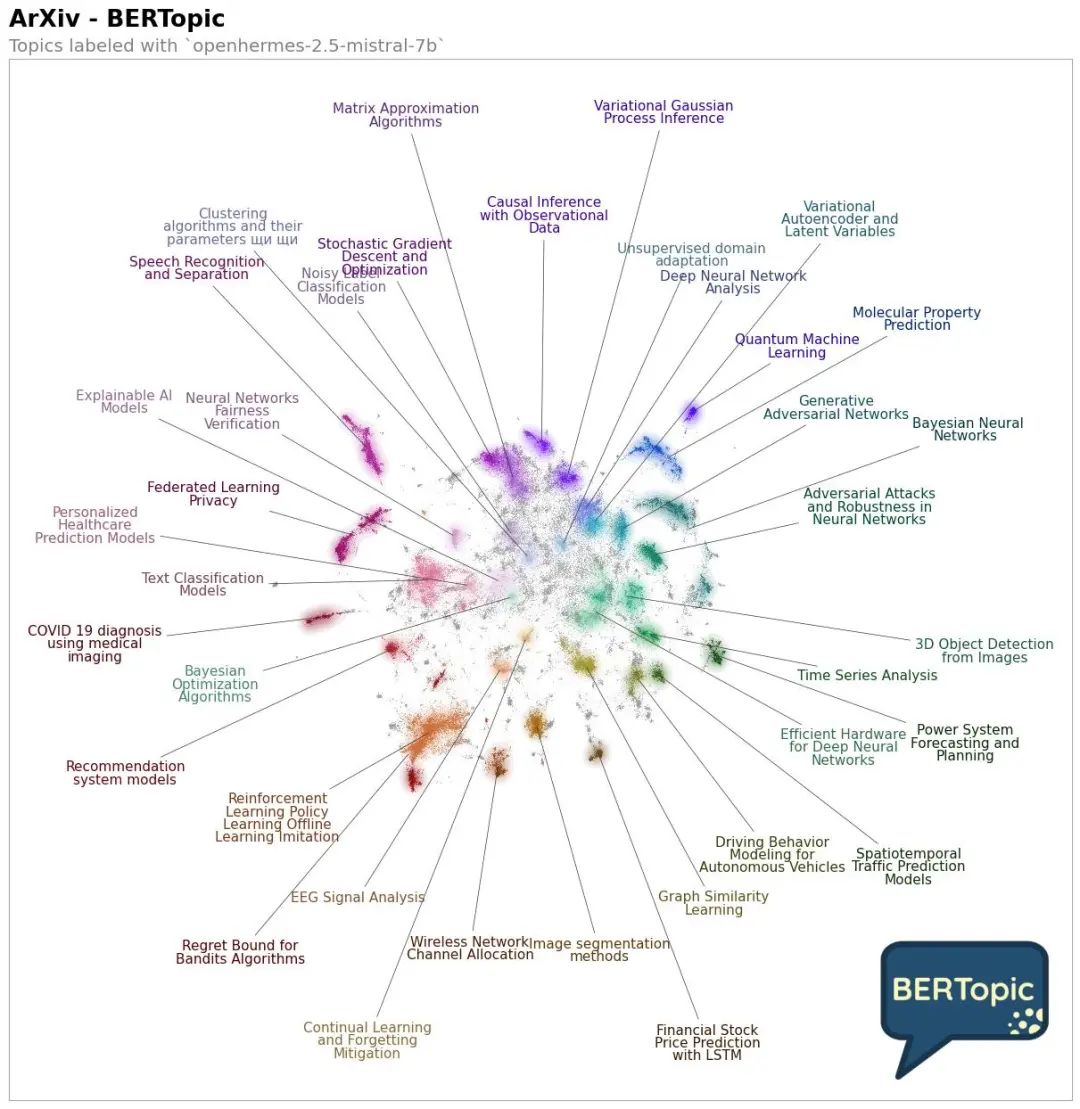
结论:
BERTopic 是一个强大的工具,它利用 BERT 嵌入的功能来揭示文本数据中的主题结构。它能够生成具有语义上下文的主题,有助于更深入地理解大型文本语料库中的潜在模式。
作为对 BERTopic 的补充,DataMapPlot 作为一种视觉辅助工具出现,通过基于地图的界面直观地表示这些主题。通过提供主题及其关系的空间安排,DataMapPlot 增强了 BERTopic 结果的可解释性,使用户能够更有效地探索和理解复杂的文本结构。
这些工具共同为主题建模和可视化提供了一个强大的框架,满足了研究人员、分析师和从业者从文本数据中寻求有意义的见解的需求。它们的协同作用扩大了主题建模的可访问性和可用性,有助于在各个领域做出更明智的决策和发现知识。
参考链接:
Colab Notebook:https://colab.research.google.com/drive/13DFJR_0_BvCs5i97XQPFWpNZuYrT2wS-#scrollTo=Ctg7wEpu9urL
BERTopic:https://www.maartengrootendorst.com/blog/bertopic/#:~:text=Well, BERTopic is a topic,topic model however you want.
MathKnowTopic:https://link.springer.com/chapter/10.1007/978-981-99-2602-2_47'
DatamapPlot:https://github.com/TutteInstitute/datamapplot
欢迎添加 二师兄 的个人微信 沟通交流(请勿重复添加)

请用个人微信添加
