




论文介绍
https://arxiv.org/pdf/2404.14047.pdf
这篇文章探讨了Meta的LLAMA家族,尤其是最新的LLAMA3模型(超大规模预训练 15T令牌数据)。作者评估了10种现有的后训练量化和LoRA微调方法在1-8比特和各种数据集上的低比特量化性能。
LLaMA 3
https://github.com/meta-llama/llama3
Meta推出的LLaMA系列代表了自动回归大型语言模型(LLM)在Transformer架构上的突破。从其首个版本开始,拥有130亿参数的LLaMA系列就成功超越了拥有1750亿参数的规模更大的、闭源的GPT-3模型。

2024年4月18日,Meta推出了LLAMA3模型,提供了80亿和700亿参数的配置。由于在超过15万亿数据令牌上进行了广泛的预训练,LLAMA3模型在各种任务上均取得了最先进的性能,将LLaMA系列确立为最优秀的开源LLM之一,适用于各种应用和部署场景。
量化方法
GPTQ
每一列的权重都是基于固定比例的伪量化误差和从激活中计算的Hessian矩阵的逆来更新的。共享相同比例的更新列可能会生成新的最大/最小值,因此需要保存比例以便恢复。
AWQ
AWQ证明了保护仅1%的显著权重可以大大降低量化误差。通过观察每个通道的激活和权重的分布来选择显著权重通道。显著权重在量化之前也会乘以一个大比例因子进行保留。
QuIP
QuIP通过随机正交矩阵的乘法确保权重和Hessian的不一致性的高效预处理和后处理。
DB-LLM
DB-LLM通过在微观层面引入灵活的双重二值化(FDB),同时在宏观层面提出偏差感知蒸馏(DAD)方法来缓解超低比特量化的微观和宏观特性。
SmoothQuant
SmoothQuant通过离线迁移量化难度,将激活的异常值平滑处理,并实现了权重和激活的INT8量化。它适用于LLMs中的所有矩阵乘法,包括多个主流模型。
PB-LLM
PB-LLM在二值化过程中过滤出一小部分显著权重,并将它们分配到更高比特的存储中,即部分二值化。
BiLLM
BiLLM是一种为预训练LLMs量身定制的突破性1比特后训练量化方案,首先识别并结构选择显著权重,并通过有效的二值化残差逼近策略来最小化压缩损失。
高效微调方法
QLoRA
QLoRA通过将梯度反向传播到一个冻结的、4位量化的预训练语言模型中,进而传播到低秩适配器(LoRA)。基准测试中表现优于所有先前公开发布的模型,达到了ChatGPT性能水平的99.3%,而只需要在单个GPU上进行24小时的微调。
IR-QLoRA
IR-QLoRA通过信息保留将带有LoRA的量化LLMs推向高精度。IR-QLoRA基于统计的信息校准量化允许LLMs的量化参数准确保留原始信息,并基于微调的信息弹性连接使LoRA能够利用具有多样信息的弹性表示变换。
实验设置
通过官方仓库获得了预训练的LLAMA3-8B和-70B模型,选择了具有广泛影响和功能的代表性LLM量化方法:
8种PTQ方法 2种LoRA-FT方法
对于PTQ方法,我们使用WikiText2、PTB和C4数据集的部分数据作为评估数据集,使用困惑度(Perplexity,PPL)作为评估指标。
随后进一步在五个零样本评估任务(PIQA、Winogrande、ARC-e、ARC-c和Hellaswag)上进行实验,以全面验证LLAMA3的量化性能。
对于LoRA-FT方法,我们在5-shot MMLU基准上进行评估,同时还验证了LoRA-FT方法的上述五个零样本数据集。
实验结果:Post-Training Quantization
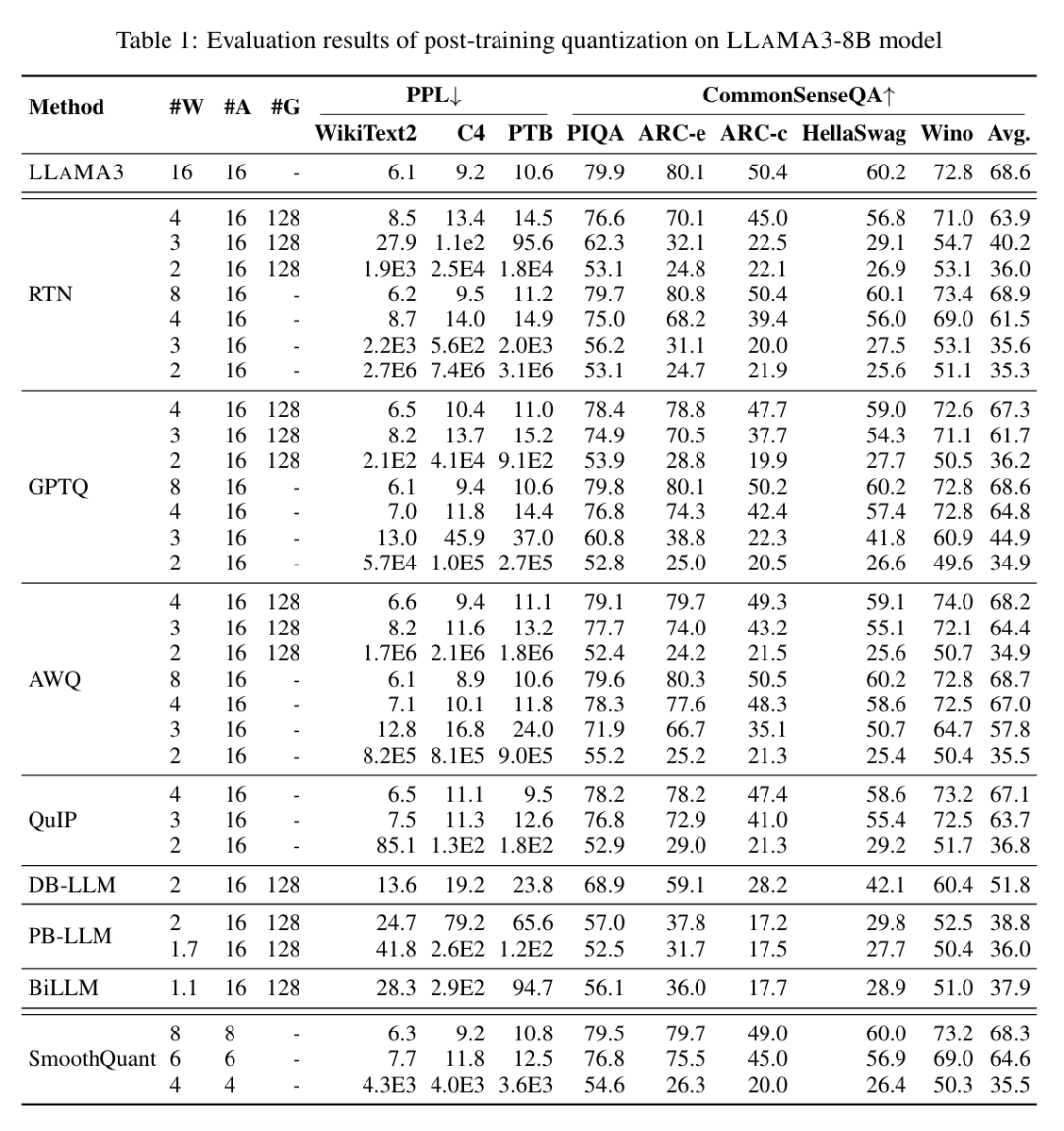
其中Round-To-Nearest(RTN)是一种普通的四舍五入量化方法。GPTQ是目前最高效、最有效的仅权重量化方法之一,它利用量化中的误差补偿。但在2-3比特下,当对LLAMA3进行量化时,GPTQ会导致严重的准确性下降。
AWQ采用异常通道抑制方法来减少权重量化的难度,而QuIP通过优化矩阵计算来确保权重和Hessian之间的不一致性。
PB-LLM采用混合精度量化策略,将大部分权重量化为1比特,同时保留一小部分显著权重的全精度。DB-LLM通过双二值化权重分割实现了高效的LLM压缩,并提出了一种考虑偏差的蒸馏策略,进一步提高了2比特LLM的性能。BiLLM通过显著权重的残差近似和非显著权重的分组量化,将LLM量化边界进一步推至1.1比特。这些专为超低比特宽度设计的LLM量化方法可以在≤2比特时实现对LLAMA3-8B的更高准确性,远远优于GPTQ、AWQ和QuIP等方法(在某些情况下甚至是3比特)。
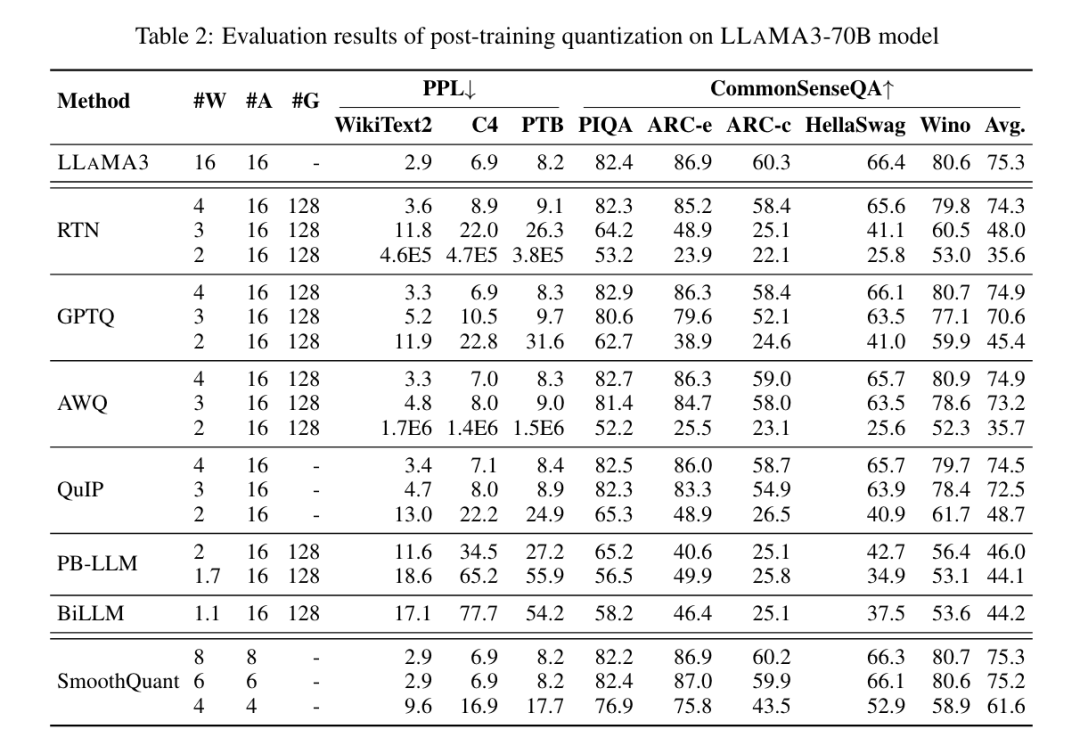
SmoothQuant可以保持LLAMA3在8比特和6比特权重和激活下的准确性,但在4比特时会出现严重准确性下降。此外我们发现LLAMA3-70B模型在各种量化方法中表现出显著的鲁棒性,即使在超低比特宽度下也是如此。
实验结果:LoRA - Fine Tuning
如表3所示。在MMLU数据集上,LLAMA3-8B在LoRA-FT量化下最显著的观察是,Alpaca数据集上的低秩微调不仅无法补偿量化引入的误差,甚至使性能下降更加严重。
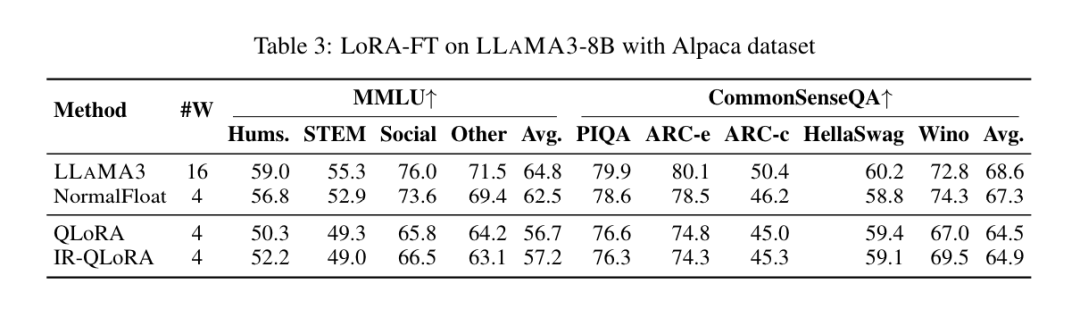
具体来说,与没有LoRA-FT的4比特对应版本相比,各种LoRA-FT量化方法在4比特下获得的量化LLAMA3的性能更差。这与LLAMA1和LLAMA2上的类似现象形成了鲜明对比,对于前者,低秩微调量化版本甚至可以轻松超越MMLU上原始FP16版本。
尽管由于量化而导致的显著性能下降无法通过微调来补偿,但4比特LoRA-FT量化的LLAMA3-8B在各种量化方法下仍明显优于LLAMA1-7B和LLAMA2-7B。例如,使用QLoRA方法,4比特LLAMA3-8B的平均准确率为57.0(FP16:64.8),超过了4比特LLAMA1-7B的38.4(FP16:34.6)18.6个百分点,并且超过了4比特LLAMA2-7B的43.9(FP16:45.5)13.1个百分点。这表明,在LLAMA3时代需要一种新的LoRA-FT量化范式。
类似的现象也出现在CommonSenseQA基准测试中。与没有LoRA-FT的4比特对应版本相比,使用QLoRA和IR-QLoRA微调的模型性能也下降了(例如,QLoRA的2.8%与IR-QLoRA的2.4%)。这进一步证明了在LLAMA3中使用高质量数据集的优势,因为一般数据集Alpaca并没有对模型在其他任务中的性能做出贡献。
# 学习大模型 & 讨论Kaggle #
每天大模型、算法竞赛、干货资讯

