




点击上方“IT那活儿”公众号--专注于企业全栈运维技术分享,不管IT什么活儿,干就完了!!!
一种是通过图片转文字需要用到OCR(Optical Character Recognition,光学字符识别)技术,python通过第三方库pytesseract来实现; 一种是借助第三方识别平台识别。
通过OCR识别
1)进入登录页面,截屏有验证码的页面,保存登录页面图片到本地; 2)在登录页面中,获取验证码所在登录页面的位置; 3)打开保存在本地的登录页面图片,通过获取的验证码位置,截取到只有验证码的图片,并保存验证码图片; 4)本地打开验证码图片,通过OCR识别出验证码; 5)将识别出来的验证码输入到登录页面。
1.1 环境准备

图片转文字识别本质还是利用OCR技术,本例选用开源OCR工具tesseract来实现图片转换文字,所以要先安装tesseract。 官方下载地址:https://github.com/UB-Mannheim/tesseract/wiki 下载后双击.exe安装软件正常安装就可以,安装过程中勾选Additional language data(download)选项支持识别的语言包。 下载完成后,配置环境变量,在path里面添加Tesseract-OCR的安装目录,如E:\tools\tesseract-ocr\tesseract。 打开命令行端口,输入tesseract -v,验证是否安装成功,如下:
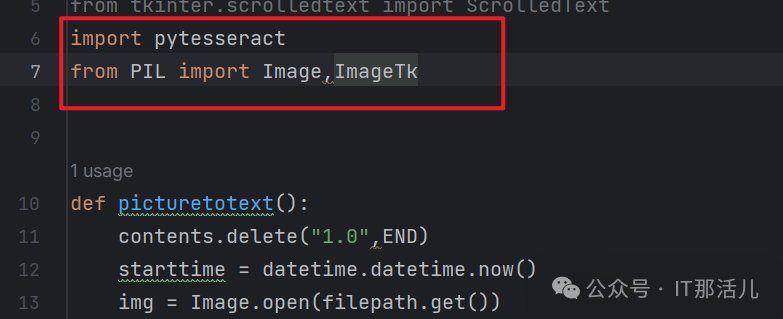
pytesseract安装,命令行端口,pip install pytesseract pillow安装,pip install pillow 进入pytesseract插件安装目录,打开pytesseract.py,修改tesseract_cmd为实际安装tesseract的地址,如下:

注意:不要漏掉r。
打开pycharm,就可以导入pytesseract使用了,如下:
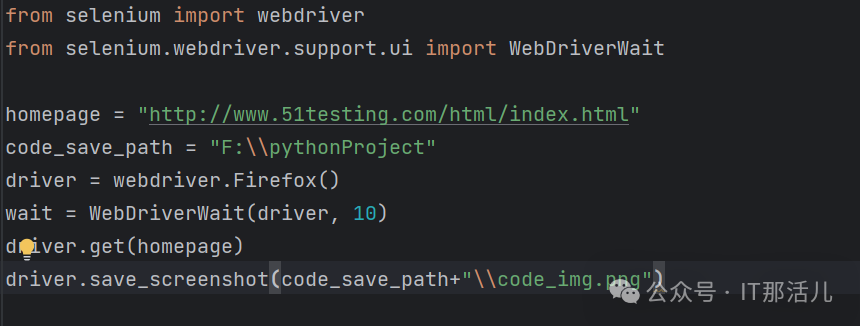
1.2 截屏保存本地
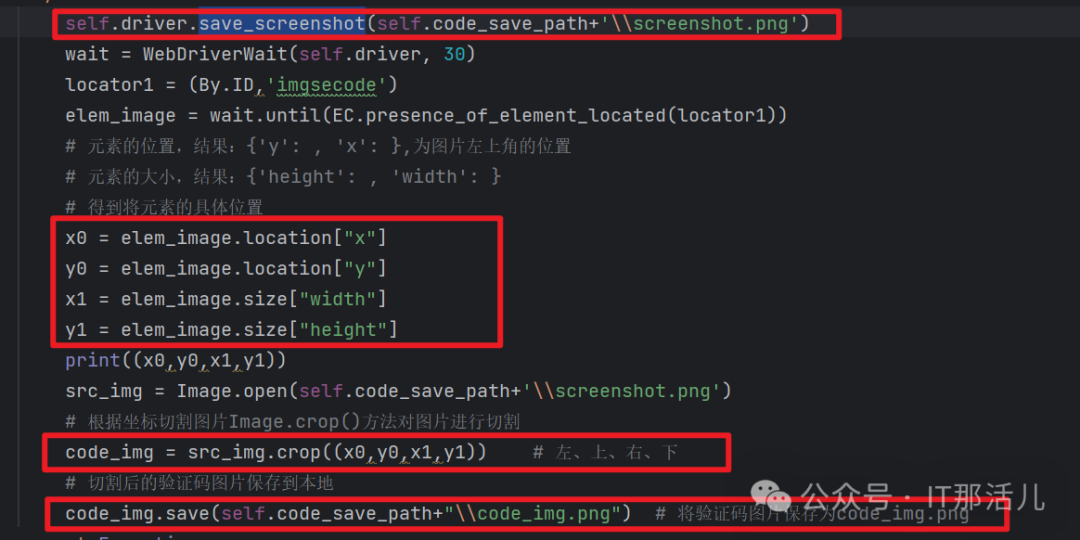
1.3 保存验证码图片
1.4 识别验证码


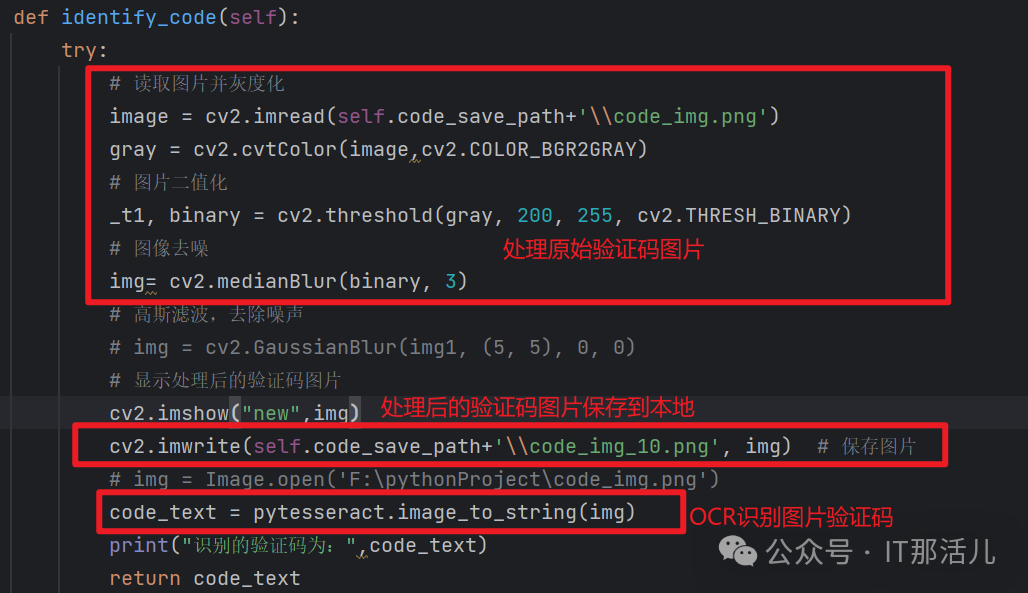
之后将识别的验证码填入登录页面的验证码框中即可。
第三方平台识别
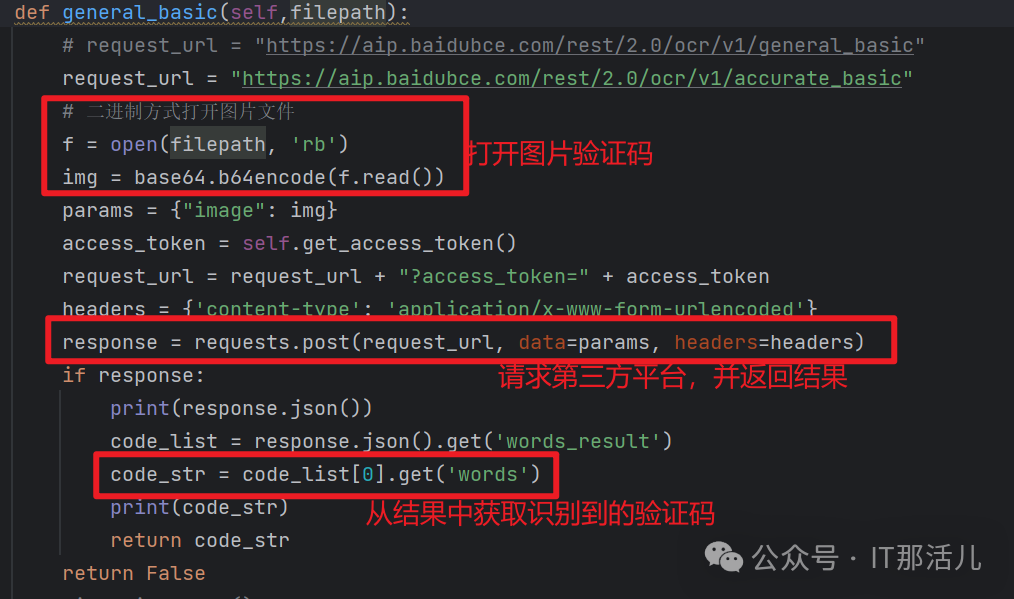
1)选择一个第三方识别图片验证码的平台,如本例选择的是百度AI开放平台 2)平台中一般都有详细的文档说明,参考文档步骤调用平台接口 3)根据平台提供的AK、SK值(收费平台的话会收费才能获取),url和请求报文,获取access_token 4)根据获取到的access_token,平台提供的请求url、请求方法、header、body参数,对平台发起url请求,返回的的结果里就有识别到的验证码

本文作者:杜俊芝(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
