




在信息爆发式增长的时代,数据如同星河般遍布在企业的各个业务角落,形成了一个庞大而复杂的信息宇宙。这些数据,既有条理分明的结构化数据,也有介于完全结构化与非结构化之间的半结构化数据,更有那些复杂且形式多样的非结构化数据,是企业数据资产重要组成部分。
其中非结构化数据包括办公文档、多媒体文件、报告、合同等,因为缺乏统一的结构化标准,难以提炼出有价值的知识并加以利用,所以一直是企业构建知识图谱的一大难题。
“TopGraph+大模型”让知识抽取更智能、更高效
为了应对这些挑战,途普智能采用了“知识图谱+大模型”融合的技术。公司在知识图谱构建领域具有显著的技术优势,其TopGraph知识构建系统结合了自然语言处理、机器学习、人工智能、知识图谱、图数据库等众多技术,可实现对结构化数据和非结构化数据的知识图谱自动化构建。产品提供了可视化标注工具和开放化的模型训练中心,其中内置了数十种抽取模型。
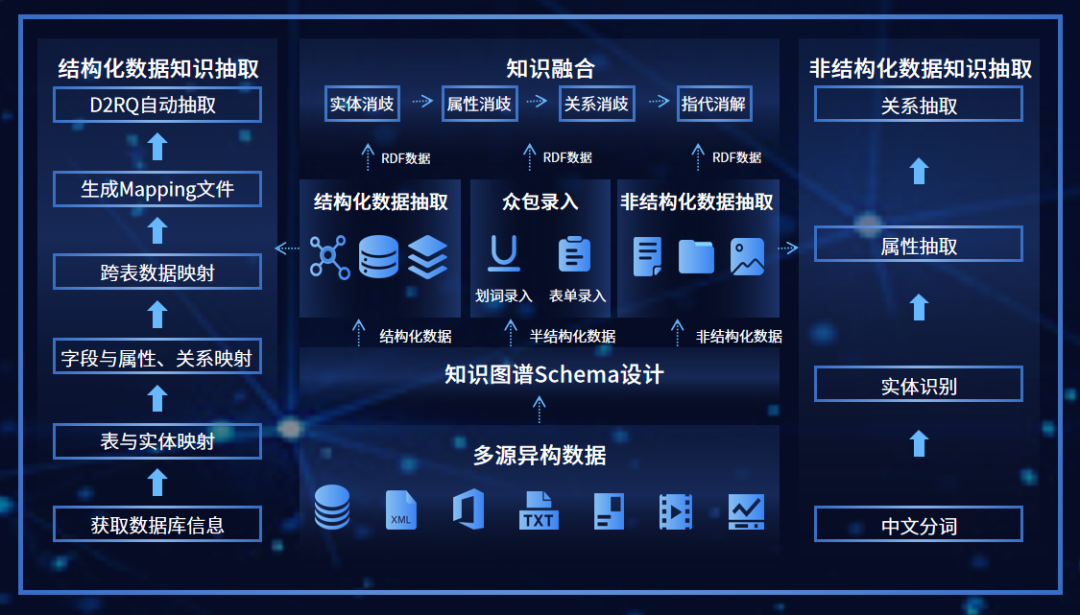
TopGraph知识构建系统
“TopGraph+大模型”在政府公文中的应用价值
以政务领域为例,“知识图谱+大模型”在其中的应用正逐渐展现出其巨大的潜力和价值,为政府决策、公共服务、政策制定等方面提供了强大的支持。其中政府公文包含大量的非结构化数据,如政策分析、会议纪要、领导讲话、政策解读等文本信息。

某政府会议记录中原始的文本信息
单个政府单位的公文数量可达到成百上千,甚至上万。传统的非结构化数据抽取方法往往依赖规则匹配,政府单位需要投入大量专业的技术人员去标注样本数据。利用TopGraph内置的多种抽取模型,并结合大模型技术,只需一个技术人员标注十几条,甚至几条样本数据,然后将标注后的样本文件,放入大模型里进行训练,即可实现数据的快速、精准地抽取。相较于传统基于深度学习和机器学习的抽取方法,使用“TopGraph+大模型”后,样本标注量减少了99%以上。

上图仅标注了3条样本数据
在“Topgraph+大模型”中我们内置了基于LLM的命名实体模型和关系抽取模型。其中命名实体模型在未经样本“重训练“的情况下,只支持人名、地名、机构名(国家或地区)的识别,通过对已有数据进行少量标注(本案例中3条),并进行模型的“重训练”(其实质是生成模型提示词),可以在原来的命名实体模型的基础上“派生”出新的子模型,该子模型可以支持“签署文件”和“行动”等实体的识别,且模型的F1值超过90%;同理通过对关系抽取模型注入少量新的样本数据,可以“派生”出新的关系抽取子模型,支持“国家/机构”对“签署文件”和“行动”的关系抽取,其模型的F1值超过80%,这样极大地降低了非结构化数据知识抽取的技术门槛和人工成本。
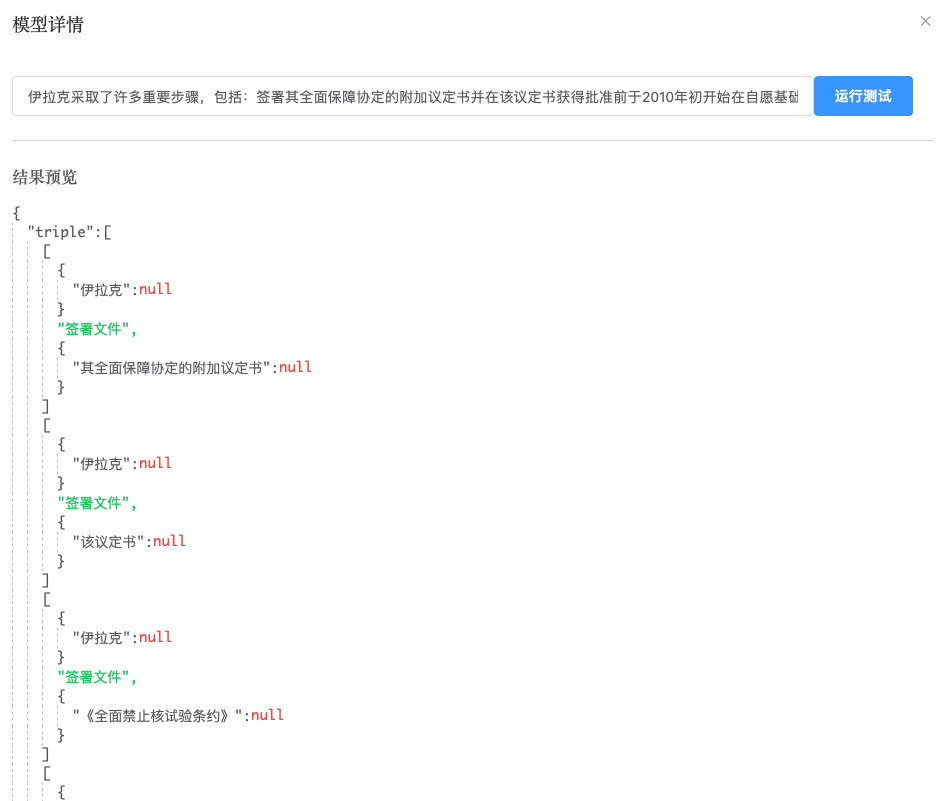
使用“TopGraph+大模型”后实现的抽取效果
展望未来
我们将不断推进“Topgraph+大模型”技术的创新与完善,开发更多高级功能,以适应企业多变的业务需求,将知识的力量转化为推动企业发展的强大动力。目前这项技术,已经成功应用于金融、政务、教育、医疗、工业等多个行业。
关于途普智能
途普智能科技(北京)有限公司是一家专注于图数据库系统研发、知识图谱应用的高科技创新企业,由北京大学科技成果转化所创立。公司致力于打造国产图数据库的“中国芯”,提供从知识构建、管理到服务系统为一体的TopGraph企业知识中台产品和行业解决方案,目前已部署于工业质量管控、金融风险分析、政务大数据、智能问答机器人、电信欺诈检测等多个场景,并在金融、政务、工业、教育、医疗等行业广泛应用。

