





本文通过实际案例说明数据类型不一致对执行计划的影响。通过案例分析,帮助大家了解影响因素,避免踩坑。
最近在项目中有个慢sql执行查询需要100多秒,查询语句的结构其实很简单,但是调整不到想要的计划,最终发现是数据类型影响的,调整后获得理想计划。
SELECTb.YC_ID,b.YC_NAME,b.xxx...b.DEVICE_ID,'2021-12-27' as DEVICETIME ,ROUND(TO_NUMBER(data_0_0), 6) as CUR_VALUEFROMTEST1_FQ202112 ainner join TEST2 bona.data_id = b.yc_idWHEREA.OCCUR_DATE='2021-12-27';
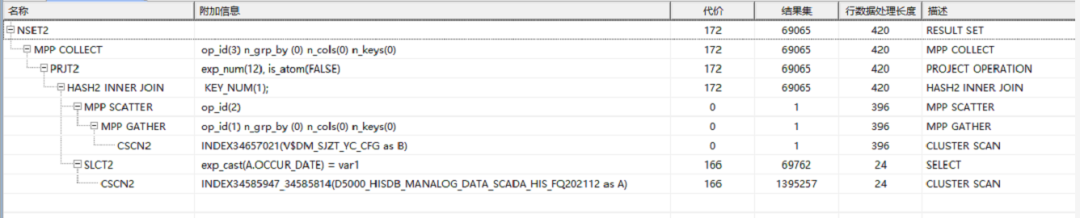
经过上述简单分析可以看出,a和b表应该做nest loop index join,且a表走(occur_date,data_id)复合索引最合适,那我们看一下实际计划:
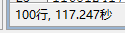
执行时间在:
实际计划为两表做了hash join,这完全不符合预期,查看a表cscn2的预估结果集为1395257,显然a表的统计信息不准确,那我们更新下统计信息并且禁用hash join,在mpp环境下强制做nl index试试:

通过上述计划可以看到,计划的确朝着我们的引导方向走了,连接方式为nest loop index join,a表为索引定位。
但是这是需要注意到的是a表索引定位方式为scan_range[(exp_cast(‘2021-12-27’),min),(exp_cast(‘2021-12-27’),max)]。这貌似不对!
虽然是ssek2,但实际上该索引只是利用到了前导列occur_date,而data_id没有用上,估计效率不会高,因为occur_date过滤完依然也有近20万的数据,加上回表和连接效率估计不会高到哪里去,二话不说实际执行以下看下效果吧!
那为什么data_id无法走索引定位呢?其实我们仔细观察执行计划就能看出端倪:
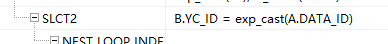
a.data_id和b.yc_id被放到了两表连接之后,并且有exp_cast操作,这时候就该想到这两个数据类型是否不一致啊。确认后果然a.data_id为bigint,而b表yc_id为numeric(20,0),存在数据类型内部转换。
那我们将sql语句改动一下,将连接列做一下数据类型转换:
a.data_id = cast(b.yc_id as bigint)
这时候我们发现执行计划变成了我们理想的计划了:

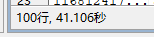
执行耗时为0.049ms,大功告成!
在进行sql语句优化过程中,有时候数据类型不一致并不会导致结果集或执行通过率,但是有时候会导致偏离理想的执行计划,大幅降低执行效率,当执行计划出现了exp_cast则一定要引起足够的重视!
以上为本期分享,希望能带给大家帮助。想要了解更多往期干货,可访问页面最下方#达梦技术干货攻略#合集或下方相关分享。在此邀请更多学员参与“达梦技术干货投稿活动”,稿件获选后将在达梦“干货分享”专栏进行发布,欢迎来稿!
相关分享:
【开班通知】DM8-DCA线上培训班招生中(2024年05月15日开班)
【开班通知】DM8-DCP线上培训班招生中(2024年05月13日开班)
【开班通知】DM8-DCM认证培训班招生中(2024年05月20日开班)
【公开课】火速关注!2024年达梦数据库运维系列公开课来啦!

