




书接上文,上面两篇文章介绍了 PG 单机安装及数据库的基础操作,菜鸟都可以看懂的 PostgreSQL 单机安装与基础知识学习手册(中),这一篇我们来学习 PG 数据库的体系架构。
PG 体系结构

下图是来自网络上网友自己画的 PostgreSQL 的体系架构图,我这里偷个懒就不自己画了,如有侵权,可联系我删除,谢谢!

当然,这个体系结构看着和 Oracle 的架构图差不多,PG 也是多进程架构,下面我们来先看看物理存储结构,这些是真真实实能看得到的物理磁盘文件。
0、物理存储结构
数据库的文件默认保存在数据库安装时initdb指定的目录中,数据库集簇在本质上就是一个文件目录也就是基础目录。通常基础目录路径配置到环境变量PGDATA,但这不是必须的。
在数据库目录中除了数据文件,还有参数文件、控制文件、数据库运行日志、预写日志等。
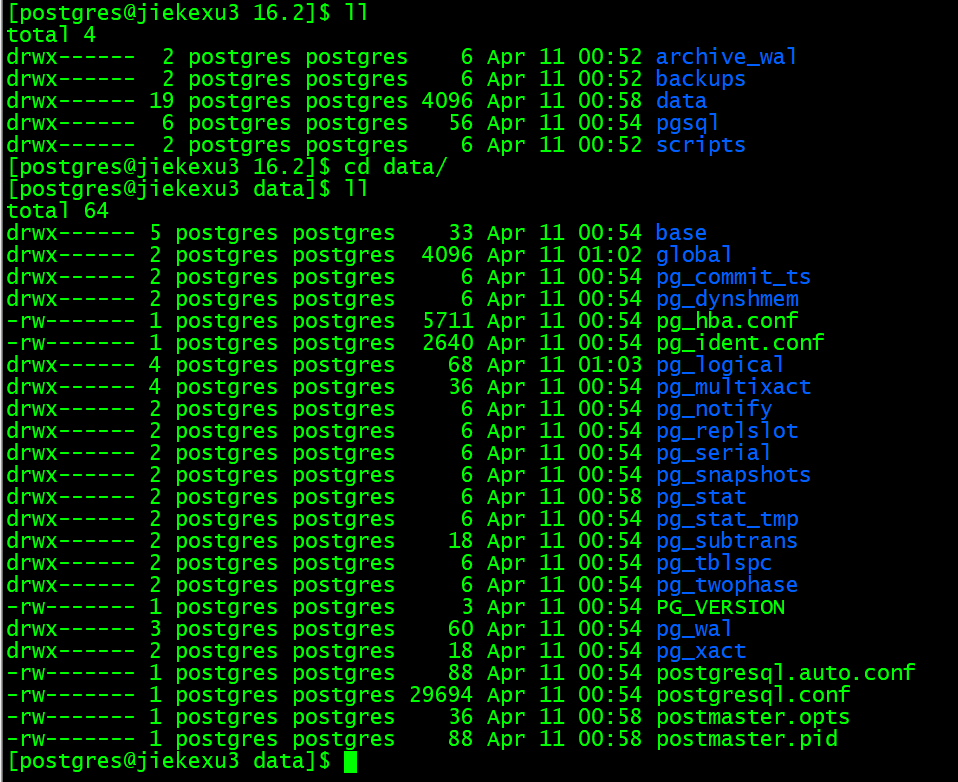
[postgres@jiekexu3 16.2]$ tree -L 1 -d data
data
├── base
├── global
├── pg_commit_ts
├── pg_dynshmem
├── pg_hba.conf
├── pg_ident.conf
├── pg_logical
├── pg_multixact
├── pg_notify
├── pg_replslot
├── pg_serial
├── pg_snapshots
├── pg_stat
├── pg_stat_tmp
├── pg_subtrans
├── pg_tblspc
├── pg_twophase
├── PG_VERSION
├── pg_wal
├── pg_xact
├── postgresql.auto.conf
├── postgresql.conf
├── postmaster.opts
└── postmaster.pid
17 directories, 7 files
下面介绍一下基础目录下子目录和文件的用途:
目录\文件 描述
base 数据库对应子目录的目录
global 数据库集簇的表的目录,比如pg_database及pg_control文件
logfile 数据库启动日志,可以手动指定名称与位置
pg_commit_ts 事物提交时间戳数据的目录
pg_dynshmem 被动态共享内存子系统所使用文件的目录
pg_hba.conf 客户端认证参数文件
pg_ident.conf 用户映射参数文件
pg_log 数据库运行日志目录,可以通过配置文件进行修改
pg_logical 逻辑复制的状态数据
pg_multixact 多事物状态数据目录
pg_notify LISTEN/NOTIFY状态数据目录
pg_replslot 复制槽数据
pg_serial 已提交的可串行化事物相关信息
pg_snapshots 导出快照的目录
pg_stat 统计子系统的永久文件目录
pg_stat_tmp 统计子系统的临时文件目录
pg_subtrans 子事物状态数据
pg_tblspc 指向表空间的符号链接
pg_twophase 两阶段事物的状态文件
PG_VERSION PostgreSQL数据库主版本号
pg_wal 预写日志目录
pg_xact 事物提交状态数据库的目录
PostgreSQL.base.conf 存储使用alter system修改的配置参数
PostgreSQL.conf 数据库参数文件
postmaster.opts 记录服务器启动命令选项
postmaster.pid 数据库启动后记录数据库进程ID
recovery.conf 数据库流复制使用参数文件
数据库目录中的 base 目录是我们数据文件默认保存目录,同时也是初始化后的默认表空间,每个数据库与 base 目录下的子目录一一对应,该子目录的名称与数据库的 oid 相同。
postgres=# select oid,datname,dattablespace from pg_database;
oid | datname | dattablespace
-------+-----------+---------------
5 | postgres | 1663
16388 | jiekexu | 1663
1 | template1 | 1663
4 | template0 | 1663
16389 | testdb | 1663
(5 rows)
postgres=# select oid,spcname from pg_tablespace;
oid | spcname
------+------------
1663 | pg_default
1664 | pg_global
1)、Oid
PostgreSQL 中所有数据库对象都由各自的对象标识符 Object Identifier Types(OID)进行内部管理,内部使用,并作为系统表的主键,它们是无符号的四字节证书。数据库对象和各个 OID 之间的关系存储在系统目录中,就像上图数据库的 OID 存储在 pg_database 系统表中,表空间的 OID 存储在 pg_tablespace 系统表中。oid2name 可以获取数据库、对象的 OID,oid 本身大小固定的,万一行数超过了 oid 的最大限制数(4 byte int),那就无法插入新行了。
数据库中表、索引、序列的对象的 OID 存储在 pg_class 系统系统表中,如下:
jiekexu=# select oid,relname,relkind from pg_class where relname like 'test%';
oid | relname | relkind
-------+---------+---------
16386 | test | r
(1 row)
2)、表空间
数据库表空间是最大的逻辑存储单位,数据库所有数据库对象都存储在表空间中。在创建数据库对象时可以指定表空间也可以使用默认表空间。
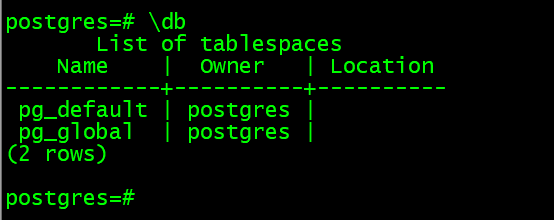
pg_global 表空间 location 显示为空,因为它是系统表空间对应的目录为 global 目录,它用来保存系统表。
pg_default 表空间location显示为空,因为它是系统表空间对应的目录为base目录,它是创建所有数据库对象的默认表空间。
执行 create tablespace 语句会创建自定义表空间:
[postgres@jiekexu3 ~]$ mkdir -p $PGDATA/pg_tblspc/tbs_mydb
[postgres@jiekexu3 ~]$ echo $PGDATA
/u01/app/pg/16.2/data
[postgres@jiekexu3 ~]$ psql
psql (16.2)
Type "help" for help.
postgres=# create tablespace tbs_mydb location '/u01/app/pg/16.2/data/pg_tblspc/tbs_mydb';
WARNING: tablespace location should not be inside the data directory
CREATE TABLESPACE
postgres=# \db tbs_mydb
List of tablespaces
Name | Owner | Location
----------+----------+------------------------------------------
tbs_mydb | postgres | /u01/app/pg/16.2/data/pg_tblspc/tbs_mydb
(1 row)
tbs_mydb 为自定义表空间,自定义表空间需要指定到实际的真实的物理目录,自定义表空间好处是可以把不同的数据存储到不同性能的磁盘上减少 IO 争用,提高读写速度,当然这个也不是一定的,大家可以灵活运用。
新建表指定表空间
postgres=# create table test2 (ID int) tablespace tbs_mydb;
CREATE TABLE
postgres=# select * from pg_tablespace where spcname ='tbs_mydb';
oid | spcname | spcowner | spcacl | spcoptions
-------+----------+----------+--------+------------
16389 | tbs_mydb | 10 | |
(1 row)
postgres=# select relname,reltablespace from pg_class where relname like 'test%';
relname | reltablespace
---------+---------------
test2 | 16389
(1 row)
在创建表空间时会在指定的表空间目录下创建版本特定的子目录(如下图PG_16_202307071),文件命名方式为:PG_主版本号_目录版本号。
在创建表时指定自定义表空间,则在特定的子目录下创建表所属的数据库 OID 相同的新目录。

3)、数据文件
我们知道表存储在表空间中,每个小于 1GB 的表或索引都在相应的目录中存储为单个文件,当大于 1GB 时数据库自动将其分为多个文件来存储,文件命名格式如 relfilenode.1、relfilenode.2、…relfilenode.n,relfilenode 的值取决于系统表 pg_class 中的 relfilenode 字段值,默认 relfilenode 值与 OID 相同,但是当多次执行VACUUM/TRUNCATE 后,两个值就会出现不一致。上面提到过所有数据库对象都是通过 oid 来管理的。relfilenode 标识对象物理位置的数字标号,会随数据存放的位置变化而变化,我们可以通过数据库内部函数 pg_relation_filepath 查看文件物理路径;可以通过函 数pg_relation_filenode() 获得对象的 relfilenode。
postgres=# select pg_relation_filepath('test2');
pg_relation_filepath
---------------------------------------------
pg_tblspc/16394/PG_16_202307071/5/16395
(1 row)
postgres=# \c jiekexu
You are now connected to database "jiekexu" as user "postgres".
jiekexu=# \d
List of relations
Schema | Name | Type | Owner
--------+------+-------+----------
public | test | table | postgres
jiekexu=# select pg_relation_filepath('test');
pg_relation_filepath
----------------------
base/16388/16390
(1 row)
-- 通过 oid2name 获取 filenode
$ oid2name -d postgres
From database "postgres":
Filenode Table Name
----------------------
49159 test
4)、空闲空间映射(FSM)
空闲空间映射(Free Space Map)简称为 FSM,每一个表和索引(除了哈希索引)都有一个空闲空间映射(FSM)来保持对关系中可用空间的跟踪,伴随主关系数据被存储在一个独立的关系分支中,以关系的文件节点号加上一个 _fsm 后缀命名。FSM 文件是执行 VACUUM 操作时,或者是为了插入行而第一次查询 FSM 文件时才会创建,PostgreSQL 使用了树形结构组织 FSM 文件,FSM 可以在数据插入时快速找到满足大小要求的空闲空间,从而复用空闲空间。在每一个 FSM 页面中是一个二叉树,存储在一个数组中,每一个节点一个字节。每个叶节点表示一个堆页面或者一个下层 FSM 页面。在每一个非叶节点中存储了它孩子节点中的最大值。因此叶节点中的最大值被存储在根中。pg_freespacemap 模块可以用来检查存储在空闲空间映射中的信息。
5)、可见性映射(VM)
为了能加快 VACUUM 清理的速度和降低对系统I/O性能的影响,V8.4版本以后为每个数据文件加了一个后缀为“__vm “的文件。每一个表都有一个可见性映射(VM)用来跟踪哪些页面只包含已知对所有活动事务可见的元组,它也跟踪哪些页面只包含未被冻结的元组。它随着主关系数据被存储在一个独立的关系分支中,以该关系的文件节点号加上一个 _vm 后缀命名。有了这个文件后,通过 VACUUM 命令扫描这个文件时,如果发现VM文件中这个数据块上的位表示该数据块没有需要清理的行,则会跳过对这个数据块的扫描,从而加快 VACUUM 清理的速度。可见性映射仅为每个堆页面存储两个位。第一位如果被设置,表示该页面上的元组都是可见的,或者换句话说该页面不含有 任何需要被清理的元组。这些信息也可以被 index-only
scans 用来只依靠索引元组回答查询。第二位如果被设置,表示该页面上的元组都已经被冻结。这也意味着防回卷清理操作也不需要重新访问该页面。pg_visibility 模块可以被用来检查存储在可见性映射中的信息。
6)、Page 页结构
PostgreSQL 中的 page 指的是数据文件内部被划分的一个个固定长度的页,和 Oracle 中的数据块类似。page 默认大小是 8k,可以在编译数据库时通过 -with-blocksize 参数指定。文件中的 Page 从 0 开始一个个进行编号,当一个 8k 的 Page 写满时就会在该 Page 尾部追加一个新的 Page。这也是为什么 PG 中单表只能是 32T,因为 PG 默认采用 32 位寻址,也就是说单张表的数据文件最多有 2^32=4294967296 个 Page。
下图是一个 Page 的结构图:
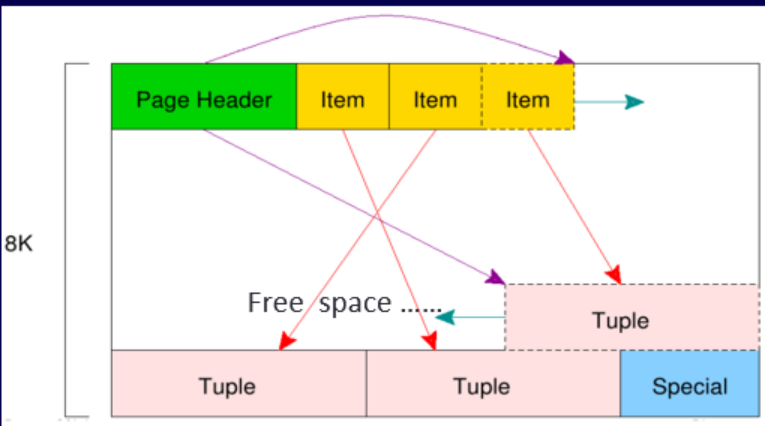
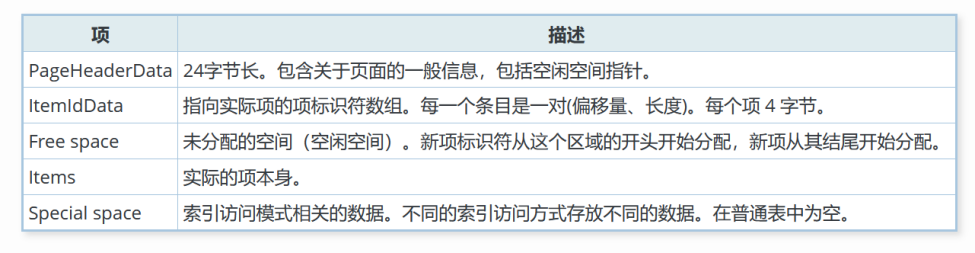
所有细节都可以在src/include/storage/bufpage.h中找到。每个页面的头24个字节组成页头(PageHeaderData)。第一个域跟踪与此页面相关的最近的 WAL 项。第二个域包含该页面的校验码(如果datachecksums被启用)。接下来一个2字节的域包含标志位。此后跟随着三个 2 字节的整数域(pd_lower、pd_upper和pd_special)。 这些域包含从页面开始位置到未分配空间开头的字节偏移、到未分配空间结尾的字节偏移以及到特殊空间开头的字节偏移。页面头中再接下来的 2 字节(pd_pagesize_version)存储页面尺寸和一个版本指示器。从PostgreSQL8.3 开始的版本号为 4;PostgreSQL 8.1 和 8.2 使用版本号3;PostgreSQL 8.0 使用版本号 2;PostgreSQL 7.3 和 7.4 使用版本号 1; 更早的版本使用版本号 0(基本页面布局和头格式在大部分这些版本里都没有改变,但是堆的行头部布局有所变化)。 页面大小主要用于交叉检查;目前在一次安装里,还不能支持多于一种页面大小。最后的域是一个提示,它显示删除该页是否可能获益:它跟踪在页面上最老的未删除的XMAX。
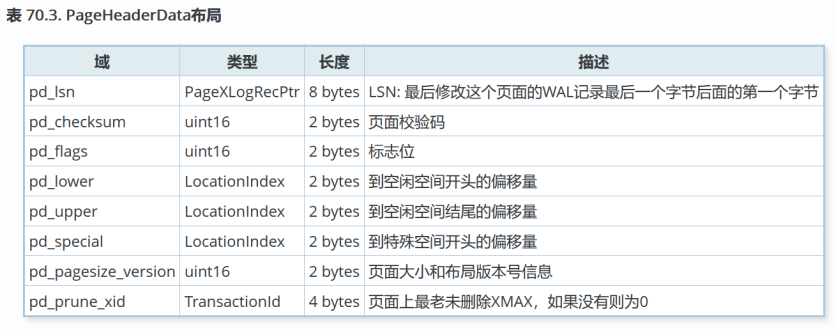
http://postgres.cn/docs/14/storage-page-layout.html
在页头后面是项标识符(ItemIdData),每个占用 4 个字节。一个项标识符包含一个到项开头的字节偏移量(它的长度以字节计),以及一些属性位,这些属性位影响对它的解释。新的项标识符根据需要从未分配空间的开头分配。项标识符的数目可以通过查看pd_lower来判断,在分配新标识符的时候pd_lower会增长。因为一个项标识符在被释放前绝对不会移动,所以它的索引可以用于长期地引用一个项, 即使该项本身因为压缩空闲空间在页面内部进行了移动。实际上,PostgreSQL创建的每个指向项的指针(ItemPointer,也叫做CTID)都由一个页号和一个项标识符的索引组成。
项本身存储在从未分配空间末尾开始从后向前分配的空间里。它们的实际结构取决于表包含的内容。表和序列都使用一种叫做 HeapTupleHeaderData 的结构。最后一部分是“特殊部分”,它可以包含访问方法想存放的任何东西。比如,b-tree 索引用它存储指向页面的左右兄妹的链接,以及其他一些和索引结构相关的数据。普通表并不使用这个部分(通过设置pd_special等于页面大小来表示)。
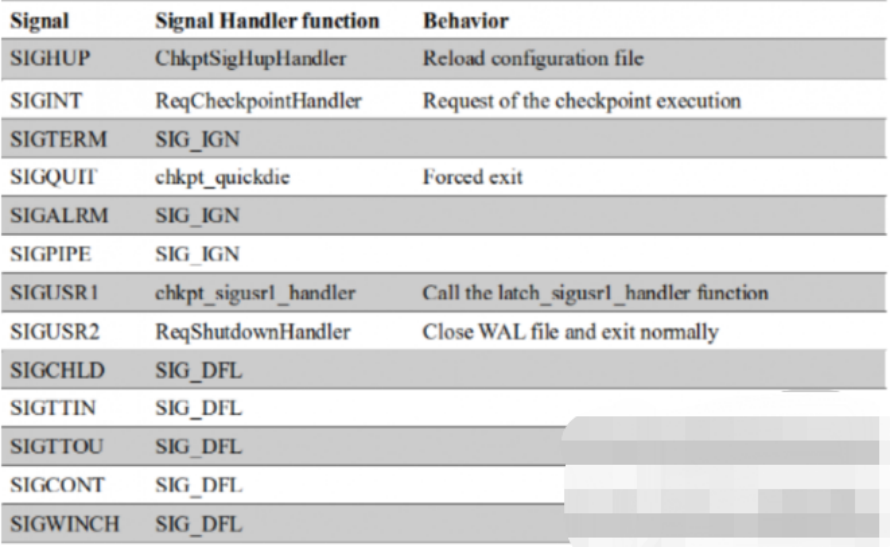
1、进程结构
PostgreSQL 是多进程多线程架构,主要有如下进程:
[postgres@jiekexu-test ~]$ ps -ef | grep postgres
postgres 65474 1 0 Sep20 ? 00:01:34 /home/postgres/PostgreSQL-13.4/bin/postgres
postgres 65475 65474 0 Sep20 ? 00:00:00 postgres: logger
postgres 65477 65474 0 Sep20 ? 00:00:04 postgres: checkpointer
postgres 65478 65474 0 Sep20 ? 00:09:37 postgres: background writer
postgres 65479 65474 0 Sep20 ? 00:10:14 postgres: walwriter
postgres 65480 65474 0 Sep20 ? 00:03:30 postgres: autovacuum launcher
postgres 65481 65474 0 Sep20 ? 00:00:16 postgres: archiver
postgres 65482 65474 0 Sep20 ? 00:04:14 postgres: stats collector
postgres 65483 65474 0 Sep20 ? 00:00:03 postgres: logical replication launcher
root 97308 97232 0 11:04 pts/5 00:00:00 su - postgres
postgres 97309 97308 0 11:04 pts/5 00:00:00 -bash
postgres 97410 97309 0 11:05 pts/5 00:00:00 ps -ef
postgres 97411 97309 0 11:05 pts/5 00:00:00 grep --color=auto postgres
logger --后台日志写进程
checkpointer --检查点进程,对应oracle的ckpt进程。
background writer --后台写进程,对应Oracle的dbwr进程。
walwriter --wal日志写进程,对应Oracle的lgwr进程。
autovacuum launcher --autovacuum的检测进程,必要时会通知postmaster进程fork产生autovacuum进程。
archiver --wal日志归档进程
stats collector --统计信息收集进程
logical replication launcher --复制同步相关
Postmaster是守护进程,实际上是第一个postgres进程,主要职责有:
• 数据库的启停
• 监听客户端连接
• 为每个客户端连接衍生(fork)专用的postgres服务进程
• 当postgres进程出错时尝试修复
• 管理数据文件
• 管理数据库的辅助进程
Postgres进程是实际上是postmaster的子进程:
• 直接与客户端进程通讯
• 负责接收客户端所有的请求
• 包含数据库引擎,负责解析SQL和生成执行计划等
• 根据命令的需要调用各中辅助进程和访问各内存结构
• 负责返回命令执行结果给客户端
• 在客户端断开连接时释放进程
除了守护进程 postmaster和服务进程 postgres外,PostgreSQL 在运行期间还需要一些辅助进程才能工作,这些进程包括:
❑ background writer:也可以称为bgwriter进程,bgwriter进程很多时候都是在休眠状态,每次唤醒后它会搜索共享缓冲池找到被修改的页,并将它们从共享缓冲池刷出。
❑ autovacuum launcher:自动清理回收垃圾进程。
❑ WAL writer:定期将WAL缓冲区上的WAL数据写入磁盘。
❑ statistics collector:统计信息收集进程。
❑ logging collector:日志进程,将消息或错误信息写入日志。
❑ archiver:WAL 归档进程。
❑ checkpointer:检查点进程。
PG 主要进程被 kill 掉后的影响
PostgreSQL允许多个客户端同时连接,配置参数 max_connections 用于控制最大客户端连接数(默认为100)。当 Logger 进程被 kill 自动重启后,数据库没有什么问题,已连接的会话也都工作正常。同理,stats collector、logical replication launcher、archiver等进程被杀,都会安全的被重新启动。对于 checkpointer 进程,如果把只有的关键服务进程杀掉,PG数据库如果设置为restart_after_crash=on,那么杀掉这个进程,PG会自动重启后台进程,不过backend进程会受到影响,需要重连。只要我们的应用具备自动重连的能力,那么应用很快就可以恢复。如果restart_after_crash设置为off,那么PG实例会宕机。Bgwriter、walwriter等后台进程的情况也都是类似的。一些和核心功能无关的PG服务进程是可以比较安全的被杀掉的,一般来说Postmaster可以自动重启这些进程,不会影响backend。有些核心的服务进程如果被杀掉了,Postmaster需要重启一系列服务进程,为了确保数据库的一致性,所有的backend进程都会重置,这样所有的会话都会中断,需要重新连接。
postgres=# SHOW restart_after_crash;
restart_after_crash
---------------------
on
(1 row)
对于 Hang 的进程或者已死掉的进程一般不建议直接 kill -9, 需使用 kill 发送信号量尝试是否可以恢复,如果不能再使用 kill -9 极端手段。使用 kill -SIGINT 或者 kill -SIGTERM 这两种去杀掉 backend,这两种 kill 命令对应于 PG 清理 backend 的两个存储过程: pg_cancel_backend和 pg_terminate_backend。向 backend 发送 SIGINT 的时候,backend 会终止当前的事务,不过并不会结束会话,而向 backend 发送 SIGTERM 的时候除了中断当前的事务还会中断会话。
Postgres 服务器进程是 PostgreSQL 数据库服务器中所有进程的父进程,在早期版本中被称为”postmaster”。
当执行 pg_ctl start 的时候会启动一个 postgres 服务器进程。它会在内存中分配共享内存区域,启动各种后台进程,如有必要还会启动复制相关进程与后台工作进程,并等待来自客户端的连接请求。每当接收到来自客户端的连接请求时就,它都会 fork 一个服务器进程,然后由启动的服务进程处理该客户端发出的所有请求。
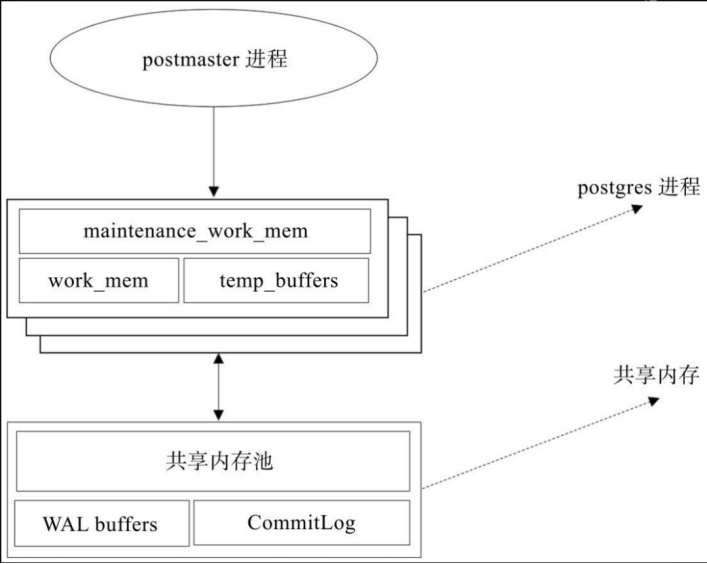
2、内存结构
本地内存由每个后端服务进程分配以供自己使用,当后端服务进程被 fork 时,每个后端进程为查询分配一个本地内存区域。本地内存由三部分组成:work_mem、maintenance_work_mem 和 temp_buffers。
❑ work_mem:当使用ORDER BY或DISTINCT操作对元组进行排序时会使用这部分内存。
❑ maintenance_work_mem:维护操作,例如VACUUM、REINDEX、CREATE INDEX等操作使用这部分内存。
❑ temp_buffers:临时表相关操作使用这部分内存。
共享内存在PostgreSQL服务器启动时分配,由所有后端进程共同使用。共享内存主要由三部分组成:
❑ shared buffer pool:PostgreSQL将表和索引中的页面从持久存储装载到这里,并直接操作它们。默认值是128MB,推荐值:1/4 主机物理内存大小。
❑ WAL buffer:WAL文件持久化之前的缓冲区。
❑ CommitLog buffer:PostgreSQL在Commit Log中保存事务的状态,并将这些状态保留在共享内存缓冲区中,在整个事务处理过程中使用。
全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
❤️ 欢迎关注我的公众号【JiekeXu DBA之路】,一起学习新知识!
————————————————————————————
公众号:JiekeXu DBA之路
墨天轮:https://www.modb.pro/u/4347
CSDN :https://blog.csdn.net/JiekeXu
ITPUB:https://blog.itpub.net/69968215
腾讯云:https://cloud.tencent.com/developer/user/5645107
————————————————————————————

