




本期的“含英咀华”为大家带来的是社区技术论坛中的精选文章《分布式数据库到oracle的数据迁移》,希望能对大家的工作学习有所帮助。
在BSS 3.0项目实施过程中,在原有的oracle系统和分布式数据库系统(UDAL+MySQL)之间,涉及到大量数据的转化、迁移。
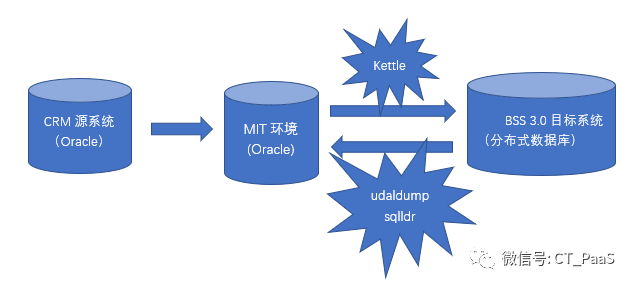
在实施过程中,一般在源系统和目标系统间需要一个中间环境,完成ETL工作。
1)源系统为CRM数据库,一般选择从Oracle数据库的复制库如dataguard库抽取数据。
2)中间环境一般也采用Oracle。通过dblink或者其他方式从源系统完成数据抽取(E);然后通过数据转化,直接转换成需要加载到目标系统的模型(T),并根据目标系统的分片方式,可以预先分好表,这部分一般采用存储过程等方式。最后一步是将MIT环境(Oracle)中的数据加载到分布式数据库目标系统中,这一步可以采用udaldump或者其他工具,浙江采用了kettle来完成。
在目标系统数据验证或者上线后,根据割接方案的不同,经常会涉及到原系统和目标系统不同模型之间的数据比对。需要把分布式数据库中的数据迁移回中间环境,进行数据比对。
本文主要讨论将分布式数据库数据批量迁移到Oracle中的过程。主要步骤是通过udaldump从分布式数据库导成文本文件,然后通过sqlldr加载到oracle数据库中。
1udaldump
数据同步工具udaldump的主要功能是从Mysql、Oracle、Udal数据库中导出、导入数据。同步流程为: 解压数据同步工具程序包 -> 准备导出、导入参数 -> 执行命令 。
同步类型
源/目标 | mysql | udal | oracle | csv | sql | hdfs |
mysql | 1 | 1 | 0 | 1 | 0 | 1 |
udal | 1 | 1 | 0 | 1 | 0 | 1 |
oracle | 1 | 1 | 0 | 1 | 0 | 1 |
csv | 1 | 1 | 0 | 0 | 0 | 0 |
sql | 0 | 0 | 0 | 0 | 0 |
由于udaldump不支持直接导入oracle,所以采用从udal将数据导成csv的方式。
1.1安装
将udaldump安装在/backup/install目录下,直接解压安装包ctg-udal-dump-2.3.0_P1.tar.gz文件即可。需要预选安装好JDK 1.8。
1.2参数文件
一般通过参数文件来调用,数据导出到/backup/dumpdata目录,示例如下:
/backup/install/dump/bin/start-opt/backup/dumpdata/test2csv.prop-eD backup/dumpdata/testexp
通过dio模式,直接从gateway抽取数据,通过选择master=false,从gateway的只读端口,也就是teledb的slave从节点抽取数据,尽量减少对源系统的影响。
示例参数文件如下:
#test2csv.prop
sh=134.1.1.12
sP=8801
su=dump_user sp=dump_password
# DBProxy作为源数据库必须配置Dio模式
dio
#当使用了dio选项时(否则忽略该参数),zk连接信息的json串(从Udal管理平台获)
zk='{"zkUrl":"134.1.1.15:2182,134.1.1.16:2182,134.1.1.17:2182,134.1.1.18:2182,134.1.1.19:2182","namespace":"udal_cluster/tenant_2","digest":"root:root"}'
#cluster的编号
#dbproxycus
cid='/dbproxy_cluster/dbproxy_cluster_0000001004'
#当使用了dio选项时(否则忽略该参数),直连mysql时是否从master数据库进行读取 master=false
#生产者线程数,dio模式,一次性读取多少分片
rt=16
#消费者线程数
ct=32 #fieldsTerminatedBy导出文件时列之间的间隔符,默认为'|',某些列里面如果包含了|,就需要设置别的列分隔符
ftb='^&'
#The character within which to enclose non-numeric column values
oeb='"'
#设置ltb的目的是为了某些列里面包含默认的回车符
ltb='<<LTB>>'
#xml形式的导入导出数据库相关配置项
x='<etl><schemas><schema src="bss_customer" des="dump"><tables>
<table src="customer"exclusiveColumn=""><filter/></table>
<table src="cust_brand"exclusiveColumn=""><filter/></table>
<table src="tax_payer"exclusiveColumn=""><filter/></table>
<table src="tax_payer_attr"exclusiveColumn=""><filter/></table>
<table src="cust_attr" exclusiveColumn=""><filter/></table><table src="party" exclusiveColumn=""><filter/></table></tables></schema></schemas></etl>'
#当使用了dio选项时,导出文件时是否每个表数据导出至一整个大文件中,若未设置该参数,则可能该表的每个分片单独摆放至一个数据文件中。这个参数当前ctg-udal-dump-2.3.0_P1.tar.gz版本不起作用。
whole=true
#是否清空异常数据目录
eC
eF
#是否以truncate形式清空目标数据库中的数据或文件导出目录
c
#文件导出时目标目录不为空是否强制清空
f
# dD=/backup/dumpdata/cusalldata
1.3命令
nohup/backup/install/dump/bin/start-opt/backup/dumpdata/cus2csv.prop-eD backup/dumpdata/cusallexp >cusall.out 2>&1 &
1.4导出文件说明
分片表
Schema名字/表名/dn名/表名.csv
一个表每个分片一个目录
全局表
随机选择一个DN导出
单片表
从所在的单个DN,导出
2sqlldr
需要在udaldump导出机器上安装oracle客户端。
nohup sqlldr udal/udal@mit control='account.ctl' log='account.log' direct=true >account.out 2>&1 &
2.1问题
列里面有|字符,需要修改 udaldump导出文件,设置ftb参数
#fieldsTerminatedBy导出文件时列之间的间隔符,默认为'|'
ftb='^&'
含有换行字符的字符串,,需要修改 udaldump导出文件,设置ltb参数
#The character within which to enclose non-numeric column values
oeb='"'
ltb='<<LTB>>'
2.2参数文件
--account.ctl
LOAD DATA
CHARACTERSET 'UTF8'
INFILE 'cusalldata/SMT_BSS_CUSTOMER/account/dn1/account.csv' "STR '<<LTB>>'"BADFILE 'cusalldata/SMT_BSS_CUSTOMER/account/dn1/account.bad'
INFILE'cusalldata/SMT_BSS_CUSTOMER/account/dn2/account.csv' "STR '<<LTB>>'"BADFILE 'cusalldata/SMT_BSS_CUSTOMER/account/dn2/account.bad'
…省略
INFILE'cusalldata/SMT_BSS_CUSTOMER/account/dn96/account.csv'"STR '<<LTB>>'"BADFILE 'cusalldata/SMT_BSS_CUSTOMER/account/dn96/account.bad'
truncate
INTO TABLE account
FIELDS TERMINATED BY "^&" optionally enclosed by '"'
TRAILING NULLCOLS
-- Column Name Order:
(
ACCT_ID,
ACCT_NAME,
ACCT_CD,
CUST_ID,
ACCT_LOGIN_NAME,
LOGIN_PASSWORD,
ACCT_BILLING_TYPE,
PROD_INST_ID,
EFF_DATEdate "YYYY-MM-DD HH24:MI:SS",
EXP_DATEdate "YYYY-MM-DD HH24:MI:SS",
STATUS_CD,
STATUS_DATE date "YYYY-MM-DD HH24:MI:SS",
CREATE_STAFF,
CREATE_DATE date "YYYY-MM-DD HH24:MI:SS",
UPDATE_STAFF,
UPDATE_DATE date "YYYY-MM-DD HH24:MI:SS",
REMARK,
EXT_ACCT_ID,
EXT1_ACCT_ID,
EXT2_ACCT_ID,
EXT3_ACCT_ID,
GROUP_ACCT_ID,
region_id
)
2.3日志文件
account.log
…省略
Table ACCOUNT:
103817429 Rows successfully loaded.
19 Rows not loaded due to data errors.
0 Rows not loaded because all WHEN clauses were failed.
0 Rows not loaded because all fields were null.
Date conversion cache disabled due to overflow (default size: 1000)
Bind array size not used in direct path.
Column array rows :5000
Stream buffer bytes:256000
Read buffer bytes:1048576
Total logical records skipped:0
Total logical records read:103817448
Total logical records rejected:19
Total logical records discarded:0
Total stream buffers loaded by SQL*Loader main thread:23811
Total stream buffers loaded by SQL*Loader load thread:47498
Run began on Mon Jun 25 19:27:22 2018
Run ended on Mon Jun 25 19:59:52 2018
Elapsed time was:00:32:30.48
CPU time was:00:29:38.86
查看日志文件,检查数据导入情况。并通过检查bad文件,查找记录被rejected的原因。
好了,本期的“含英咀华”就到这里了,欢迎各位在公众号中留言你们想要阅读的文章类型,统计完成后我们会在之后的“含英咀华”中发布于此相关的文章和案例,希望在之后的时间中继续为大家带来实用的文章和案例。
最后,感谢各位的阅览。
