





Redis 的复制总结一波,大家平时使用的时候是否思考过Redis 实现复制的原理是什么呢?今天从以下几方面总结一下:Redis 复制是什么?能干嘛?怎么玩?原理是什么呢?带上聪明的小脑袋,让我们一起学习学习
1、其实也就是我们所说的主从复制,主机数据更新后根据配置和策略,自动同步到备机的master-slaver机制,Master以写为主,Slave以读为主;
2、Redis 复制可以实现:
① 读写分离,减轻主库压力;
② 容灾恢复;
3、实现方式主要有三招:一主两从、薪火相传、反客为主;
一主两从
① 端口port 分别为6379/6380/6381
② pid文件名字:pidfile
② 开启守护进程:daemonize yes
③ log文件名字:logfile
④ dump.rdb名字:dbfilename
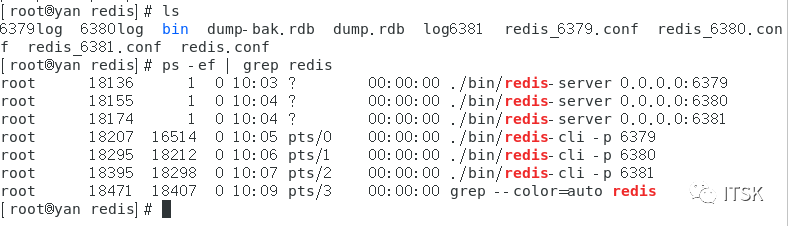
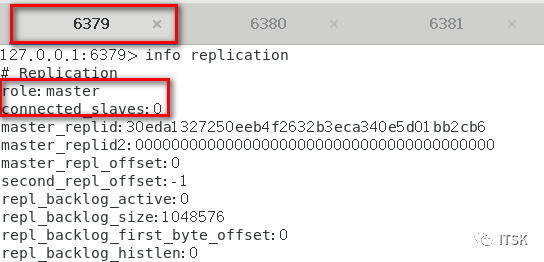
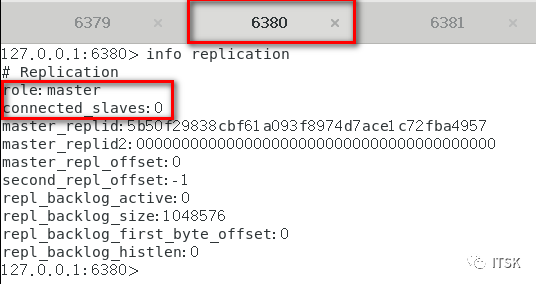
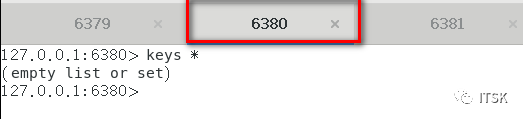

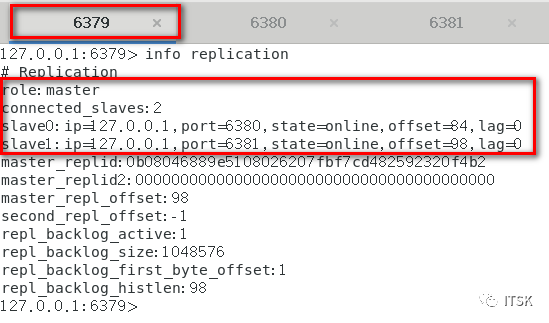
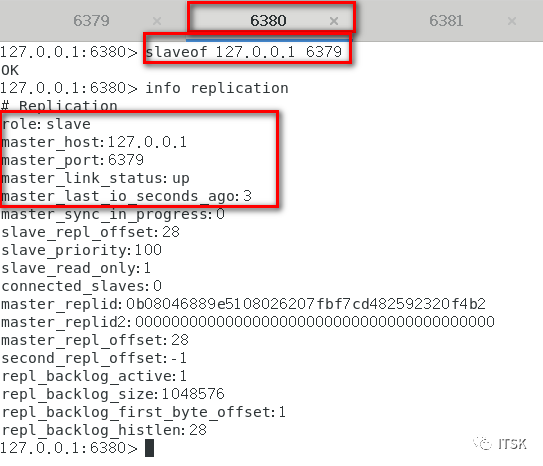
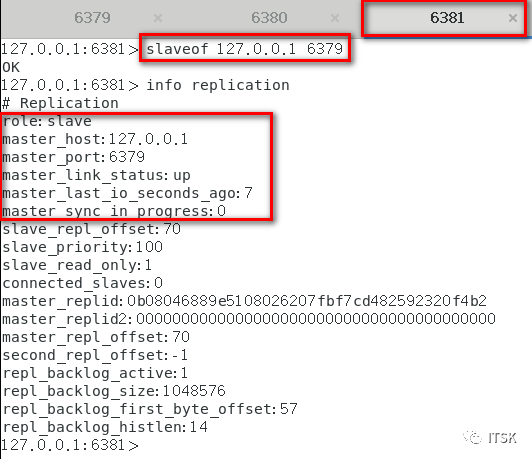
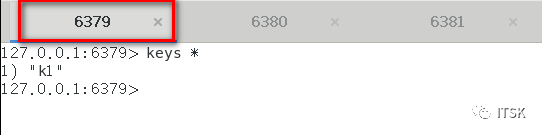
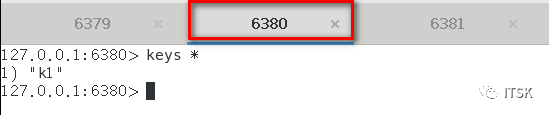

从机在第一次复制的时候会进行全量复制,关系建立后从机针对主机的每个命令会进行增量复制,以上我们就实现了redis的复制,没错,挺简单。
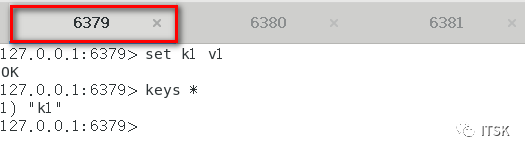
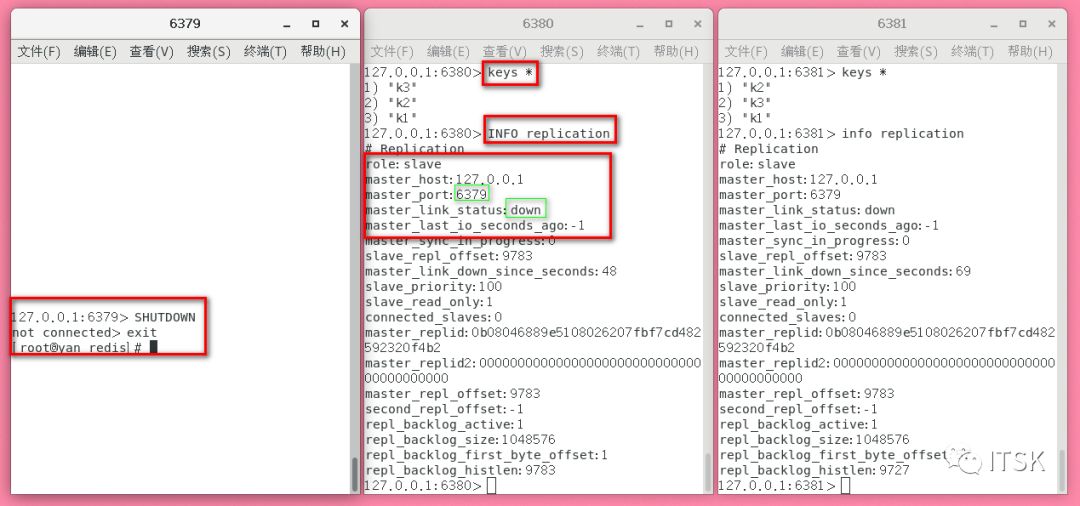
但是我们思考,如果要是在master和两个slave都进行set同一个值,结果会是如何呢,我们要始终围绕主从复制的原理去分析,如果让我们自己设计会怎么设计呢?

# Since Redis 2.6 by default replicas are read-only.## Note: read only replicas are not designed to be exposed to untrusted clients# on the internet. It's just a protection layer against misuse of the instance.# Still a read only replica exports by default all the administrative commands# such as CONFIG, DEBUG, and so forth. To a limited extent you can improve# security of read only replicas using 'rename-command' to shadow all the# administrative / dangerous commands.# 作为从服务器,默认情况下是只读的(yes),可以修改成NO,用于写(不建议)replica-read-only yes
# 配置slave复制对应的master# replicaof <masterip> <masterport>
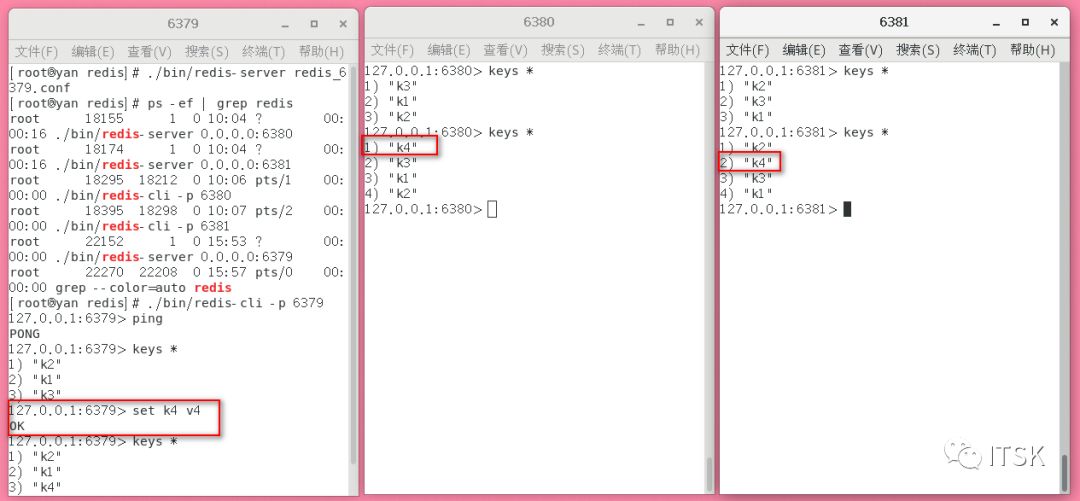
以上就是我们常用的一主两从,理论上也可以一主多从,但是这样会导致中心化太严重了,多个slave从一个master取数据,怎么解决去中心化问题呢,我们可能会想,可不可以master对一个slave,然后slave继续连接其他slave呢?只要敢想就有对应的策略实现 ,这种效果就类似薪火相传,我们就给它取名叫薪火相传
,这种效果就类似薪火相传,我们就给它取名叫薪火相传
我们配置6380的master指向6379,6381的master指向6380:
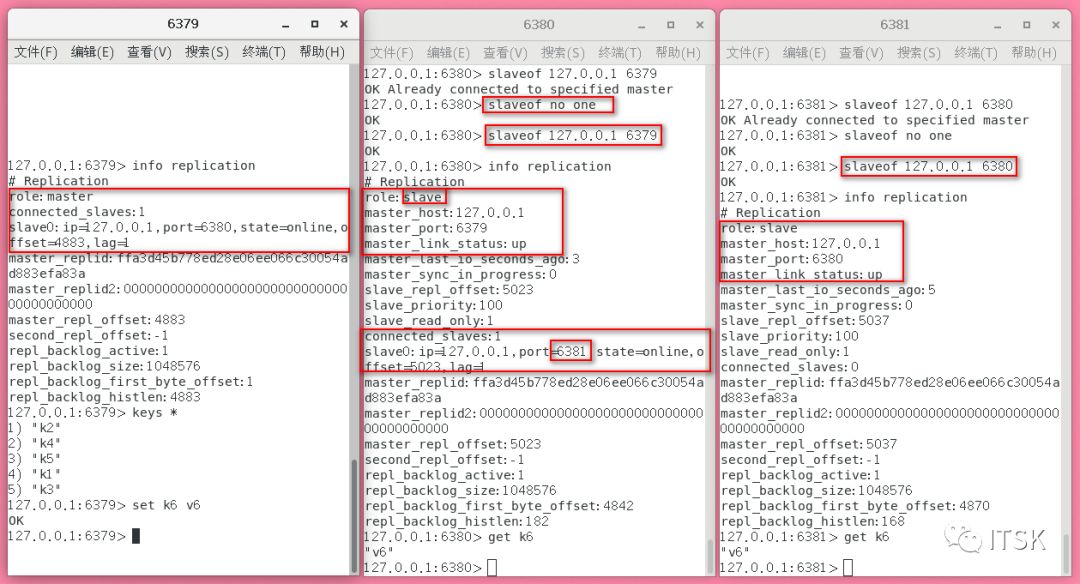
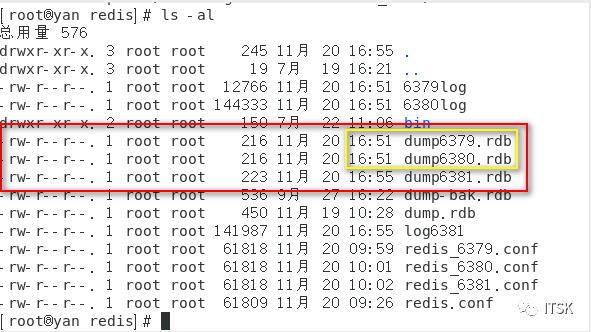
我们可以看到6381的备份rdb文件迟于6379和6380的。
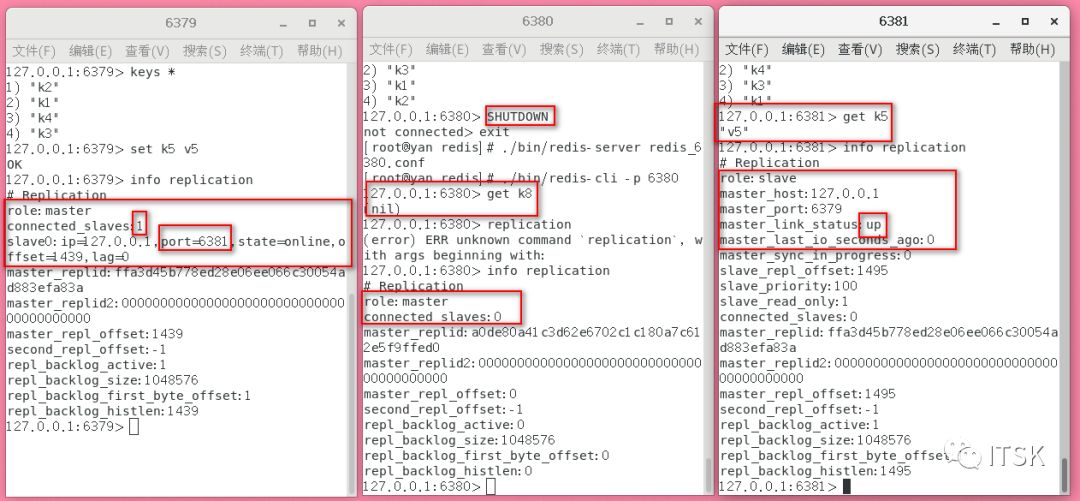
薪火相传实现了去中心化,但带会带来从库复制数据延迟的问题。
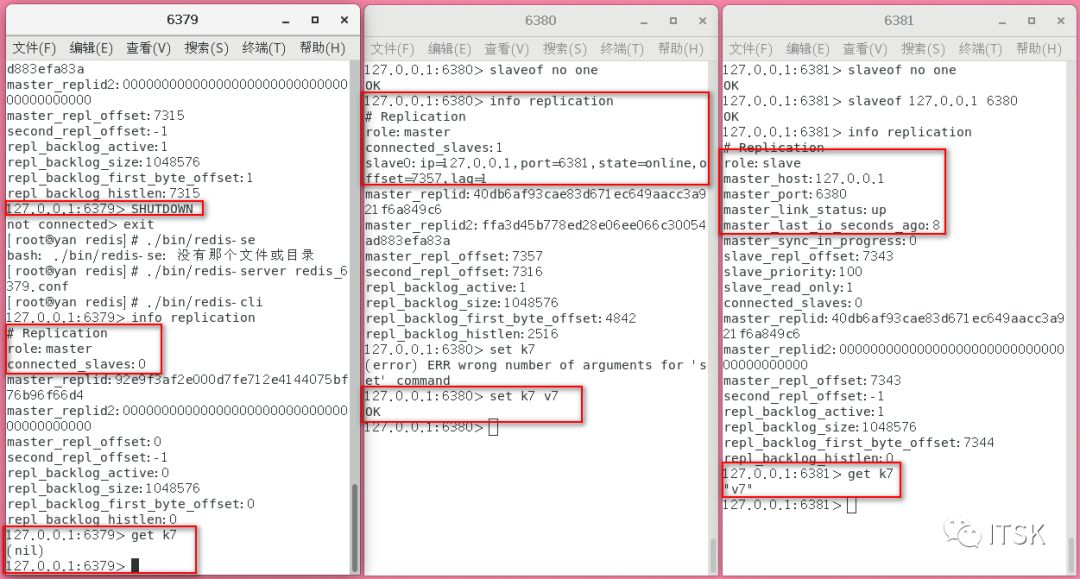
当6379master宕机以后手动设置6381为6380的slave,即此时6380为master,当6379恢复后会怎样呢?可以看到原先的主从关系断裂,6379此时作为一个独立redis,即反客为主。接下来,我们总结一下主从复制的原理。
1、主存复制原理:
① 首先slave连接master,发送SYNC命令(slaveof ...);
②master接收到SYNC命名后,fork一个后台进程执行BGSAVE命令生成RDB文件,此时不会影响前端继续接收用户操作命令,并使用缓冲区记录此后执行的所有用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步 ;
③ 全量复制:而slave服务在接收到数据库文件数据后,丢弃所有旧数据,载入收到的快照;
④ 增量复制:master继续将新的所有收集到的缓冲区中的修改命令依次传给slave,完成同步;
⑤ 但是只要是重新连接master,一次完全同步(全量复制)将被自动执行;
2、主从复制优缺点:
优点:
① 可以实现读写分离,分载master的读压力;
②slave可以接受其它slaves的连接和同步请求,这样可以有效的分载master的同步压力,可以解决中心化问题;
③master server是以非阻塞的方式为slaves提供服务,(通过fork的一个后台进程执行的)所以在master-slave同步期间,客户端仍然可以提交查询或修改请求;
④slave server同样是以非阻塞的方式完成数据同步,在同步期间,如果有客户端提交查询请求,redis则返回同步之前的数据;
缺点:
①redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复;
②主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性;
③redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂;
④由于所有的写操作都是先在master上操作,然后同步更新到slave上,所以从master同步到slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,slave机器数量的增加也会使这个问题更加严重。
哨兵模式
1、什么是哨兵模式?
其实是反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库,但是不同的是宕机后的主机恢复以后的情况。
① 先建立主从关系,这里将6380和6381的master指向6379:
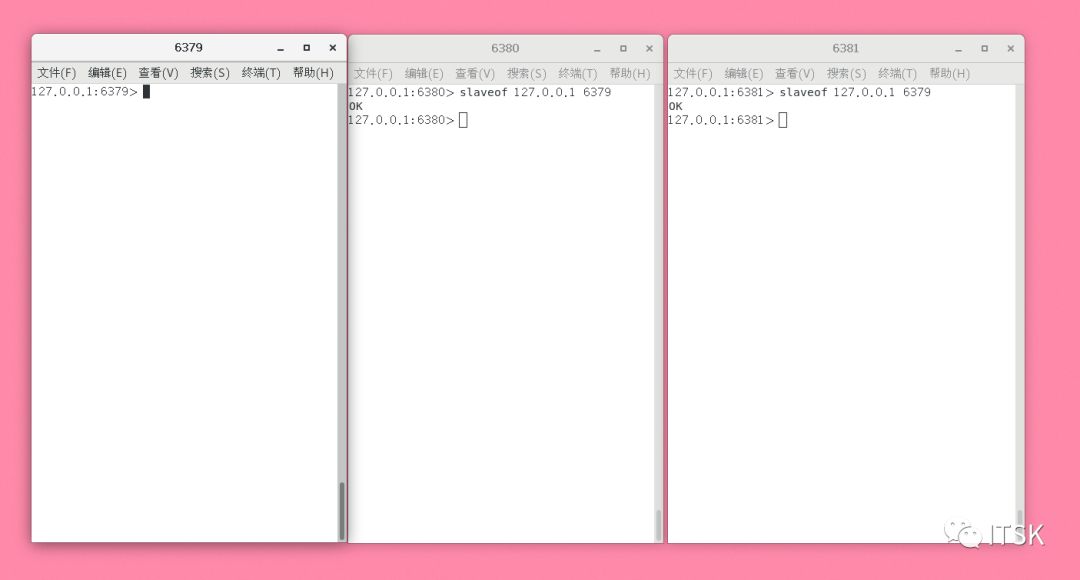
③ 配置文件sentinel.conf文件配置哨兵的内容:
sentinel monitor 被监控master主机名字(自己起名字) 主机IP 端口 1
最后一个数字1,表示主机挂掉后salve投票看让谁接替成为主机,指定的得票数多少后成为主机;
③ 启动哨兵:
redis-sentinel /XX/sentinel.conf
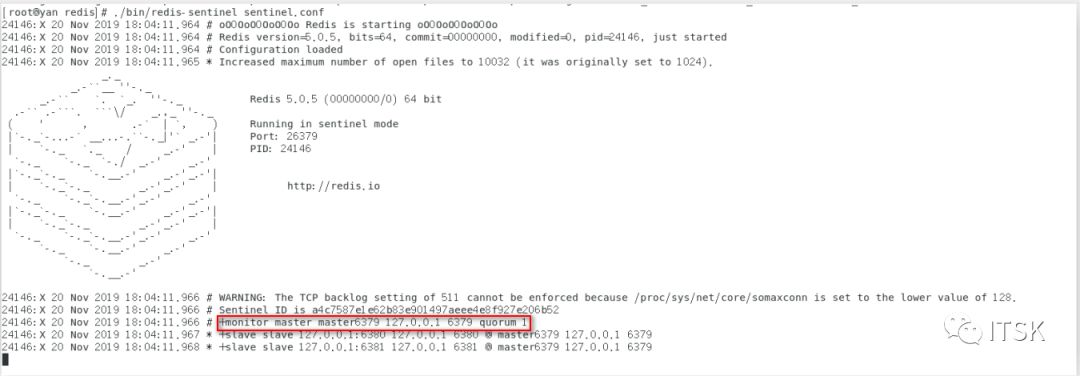
④ 主机master宕机后,我们再看哨兵的运行情况:
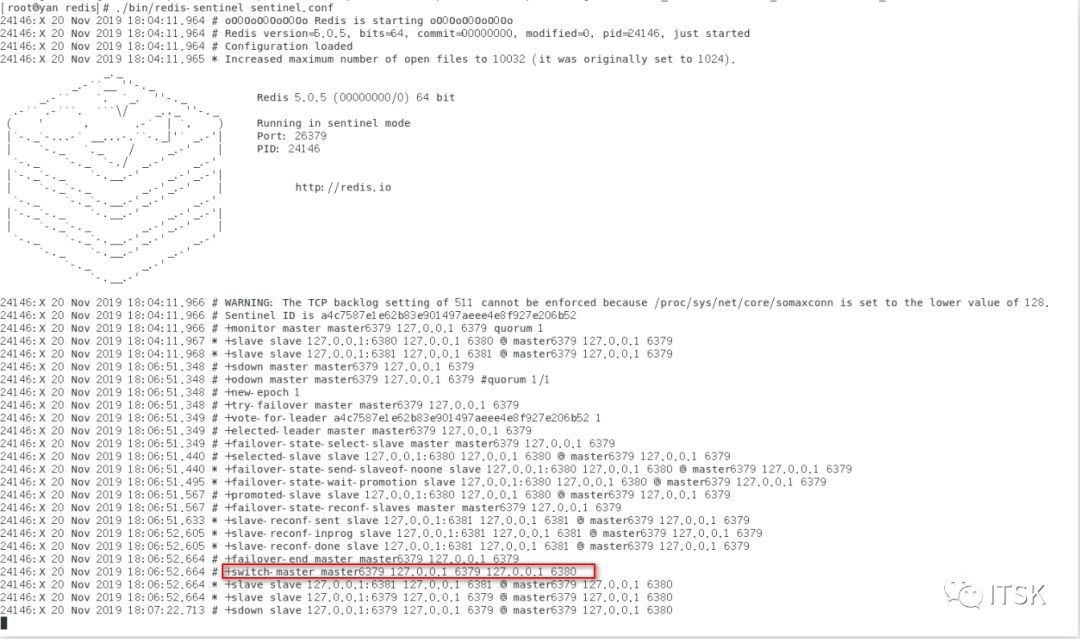
一直在进行投票选举,如上图最终选举出新的master为6380,我们info replication6380、6381的复制信息如下:
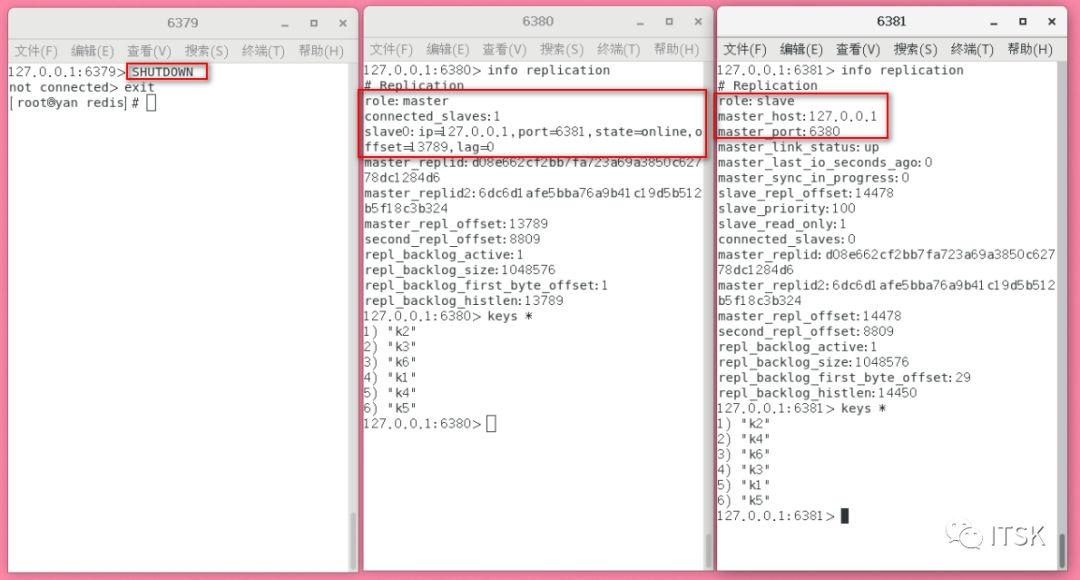
看到6380为新的master,6381为6380的一个slave,可能我们这个时候会比较关心当原master6379恢复以后会怎么样呢?和6380/6381断裂关心呢还是也作为6380的一个slave了呢?其实聪明的同学已经看到上面哨兵选举过程图了,从最终的选举结果我们也可以看到答案:
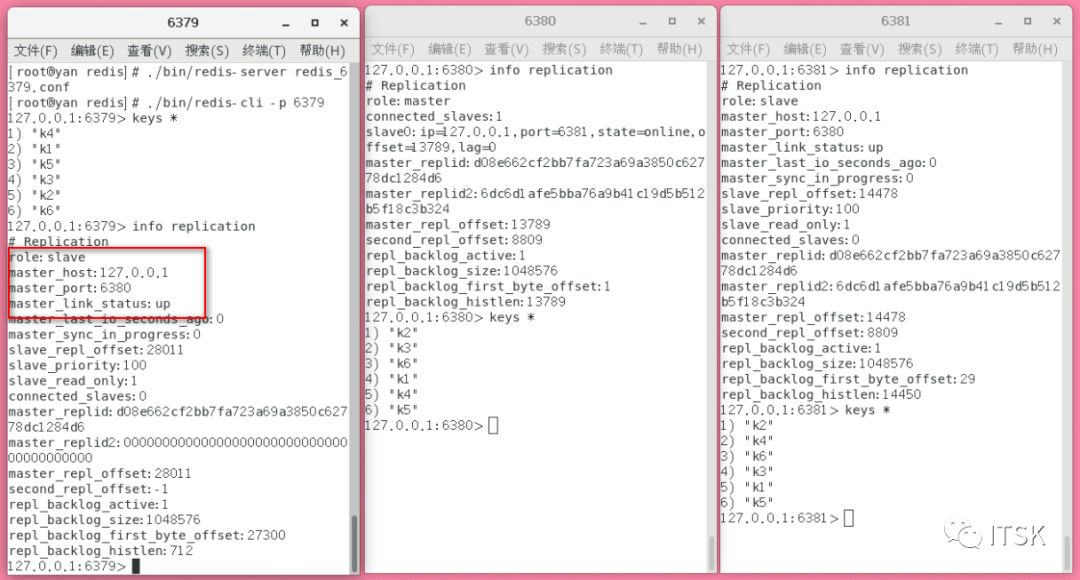
可以看到原先master6379现在也成为了6380的slave。
哨兵工作原理:
1、哨兵工作方式:
①每个Sentinel进程以每秒钟一次的频率向整个集群中的master主服务器,slave从服务器以及其他Sentinel(哨兵)进程发送一个PING命令。
②如果一个实例距离最后一次有效回复PING命令的时间超过down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN);
③如果一个master主服务器被标记为主观下线(SDOWN),则正在监视这个master主服务器的所有Sentinel(哨兵)进程要以每秒一次的频率确认master主服务器的确进入了主观下线状态;
④当有足够数量的Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认master主服务器进入了主观下线状态(SDOWN), 则master主服务器会被标记为客观下线(ODOWN);
⑤ 在一般情况下,每个 Sentinel(哨兵)进程会以每10秒一次的频率向集群中的所有master主服务器、slave从服务器发送 INFO 命令;
⑥当master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的master主服务器的所有slave从服务器发送 INFO 命令的频率会从10 秒一次改为每秒一次;
⑦若没有足够数量的Sentinel(哨兵)进程同意master主服务器下线, master主服务器的客观下线状态就会被移除。若master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,master主服务器的主观下线状态就会被移除。
2、哨兵模式的优缺点:
优点:
①哨兵模式是也是基于主从模式的,所有主从的优点,哨兵模式都具有;
②主从可以自动切换,系统更健壮,可用性更高;
缺点:
①redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂;
好了,redis的复制就总结到这里,在理解的基础上还得亲自操作观察分析,所以文章中截了大量操作的图片,方便大家查看运行效果,如果大家有什么新的发现,非常欢迎评论区留言哦
欢迎关注ITSK,每天进步一点点,我们追求在交流中收获成长和快乐


