




PostgreSQL和openGauss数据库优化器在merge join关联查询的SQL优化改写
看腻了文章就来听听视频讲解吧:https://www.bilibili.com/video/BV1oH4y137P7/
| 数据库类型 | 数据库版本 |
|---|---|
| PostgreSQL | 16.2 |
| openGauss | 6.0 |
创建测试表和数据
drop table IF EXISTS t_test_1;
drop table IF EXISTS t_test_2;
create table t_test_1 (id int, info text);
insert into t_test_1 select generate_series(1,10000000),'testdb';
create table t_test_2 as select * from t_test_1;
create index idx_t_test_1_id on t_test_1(id);
create index idx_t_test_2_id on t_test_2(id);
vacuum analyze t_test_1;
vacuum analyze t_test_2;
查询SQL
-- Merge Join
explain (analyze,buffers) select count(*) from t_test_1 t1 join t_test_2 t2 on (t1.id=t2.id) where t1.id between 5000000 and 5700000;
-- 等价写法
explain (analyze,buffers) select count(*) from t_test_1 t1 join t_test_2 t2 on (t1.id=t2.id) where t1.id between 5000000 and 5700000 and t2.id between 5000000 and 5700000;
PostgreSQL 查询计划
测试 PostgreSQL 数据库版本为:16.2
-- 关闭并行,方便查看执行计划
set max_parallel_workers = 0;
set max_parallel_workers_per_gather = 0;
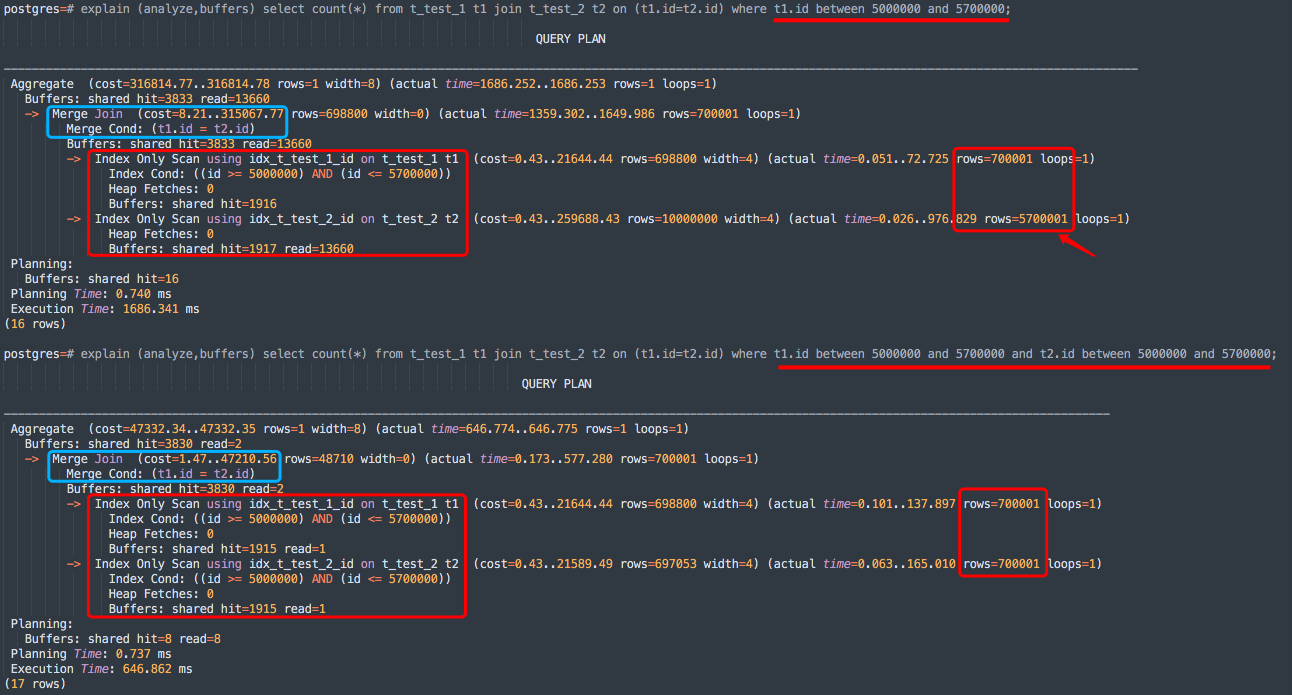
从执行计划实际扫描的行数「 rows 」,可以看到 MergeJoin 会从索引开头全部扫描,直到超过匹配范围,即 t1 表根据where条件的between过滤走的索引扫描获取数据,t2 表从索引开头全部扫描到匹配范围。
openGauss 查询计划
测试 openGauss 数据库版本为:6.0

相比 PostgreSQL 的优化器,openGauss在这种场景的处理上相对智能点
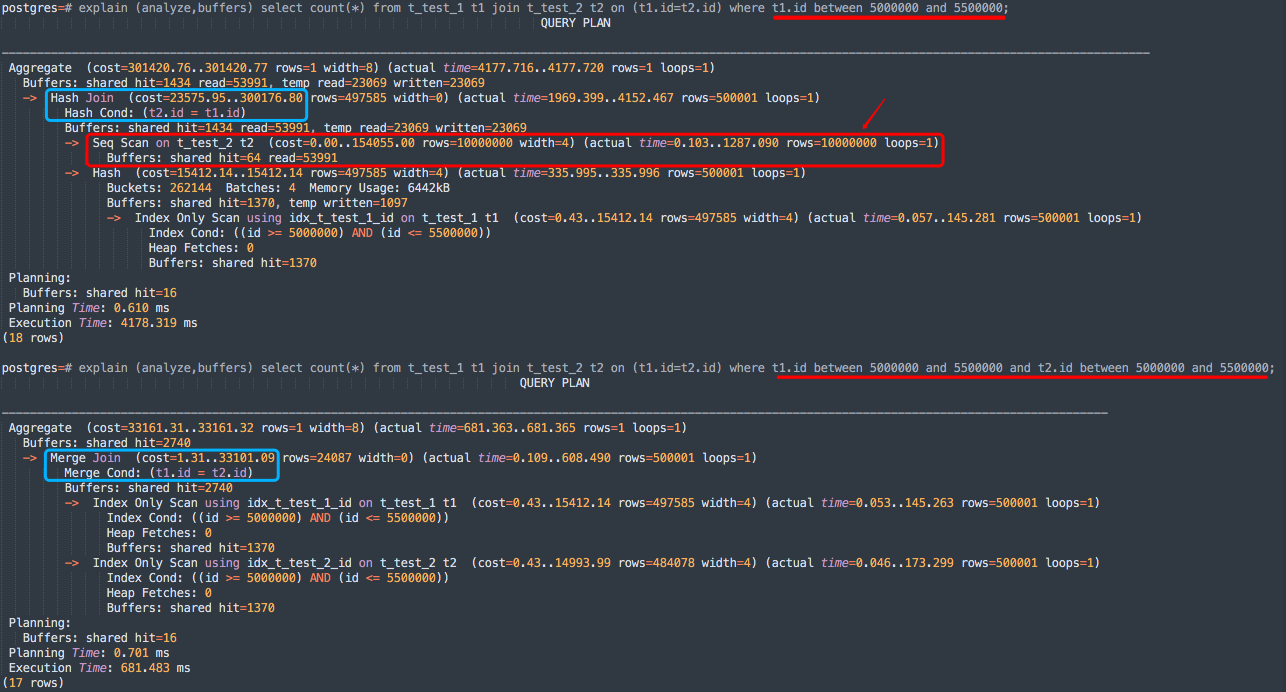
拓展对比
PostgreSQL数据库调整where过滤条件行数后的执行计划:
-- Hash Join
explain (analyze,buffers) select count(*) from t_test_1 t1 join t_test_2 t2 on (t1.id=t2.id) where t1.id between 5000000 and 5500000;
-- 等价改写
explain (analyze,buffers) select count(*) from t_test_1 t1 join t_test_2 t2 on (t1.id=t2.id) where t1.id between 5000000 and 5500000 and t2.id between 5000000 and 5500000;
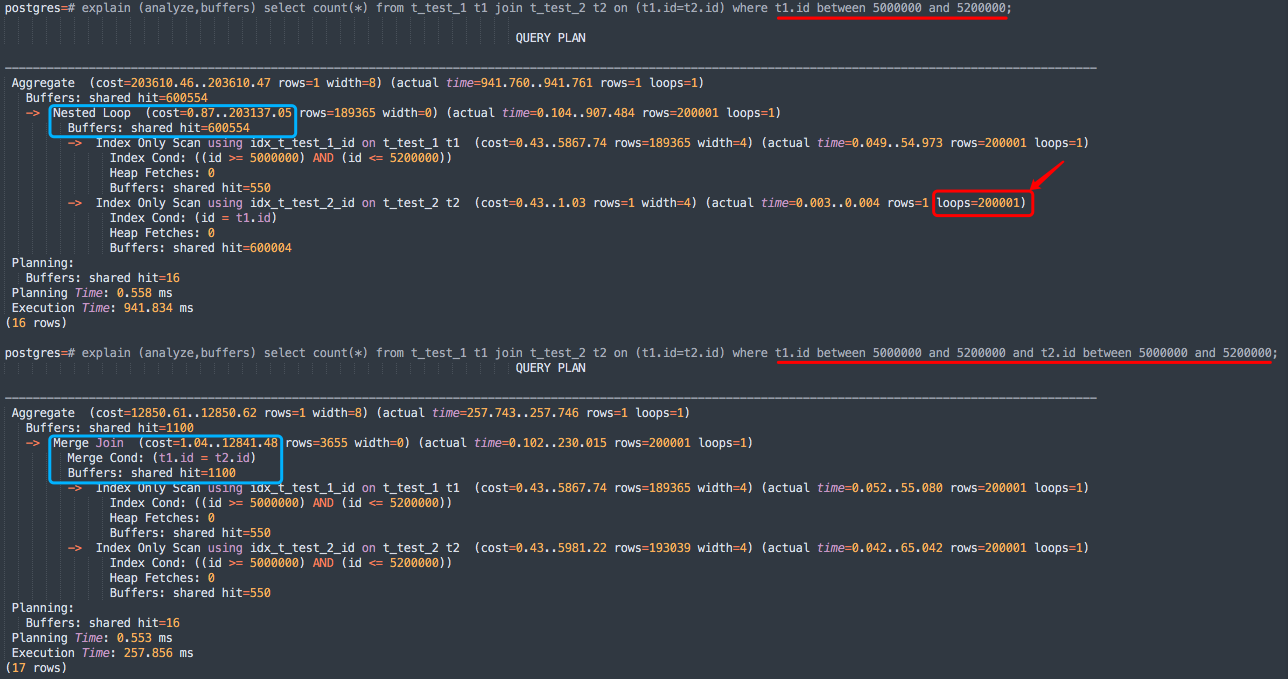
-- Nested Loop
explain (analyze,buffers) select count(*) from t_test_1 t1 join t_test_2 t2 on (t1.id=t2.id) where t1.id between 5000000 and 5200000;
-- 等价改写
explain (analyze,buffers) select count(*) from t_test_1 t1 join t_test_2 t2 on (t1.id=t2.id) where t1.id between 5000000 and 5200000 and t2.id between 5000000 and 5200000;
openGauss数据库调整where过滤条件行数后的执行计划:
-- PG Hash Join
explain (analyze,buffers) select count(*) from t_test_1 t1 join t_test_2 t2 on (t1.id=t2.id) where t1.id between 5000000 and 5500000;
-- PG Nested Loop
explain (analyze,buffers) select count(*) from t_test_1 t1 join t_test_2 t2 on (t1.id=t2.id) where t1.id between 5000000 and 5200000;
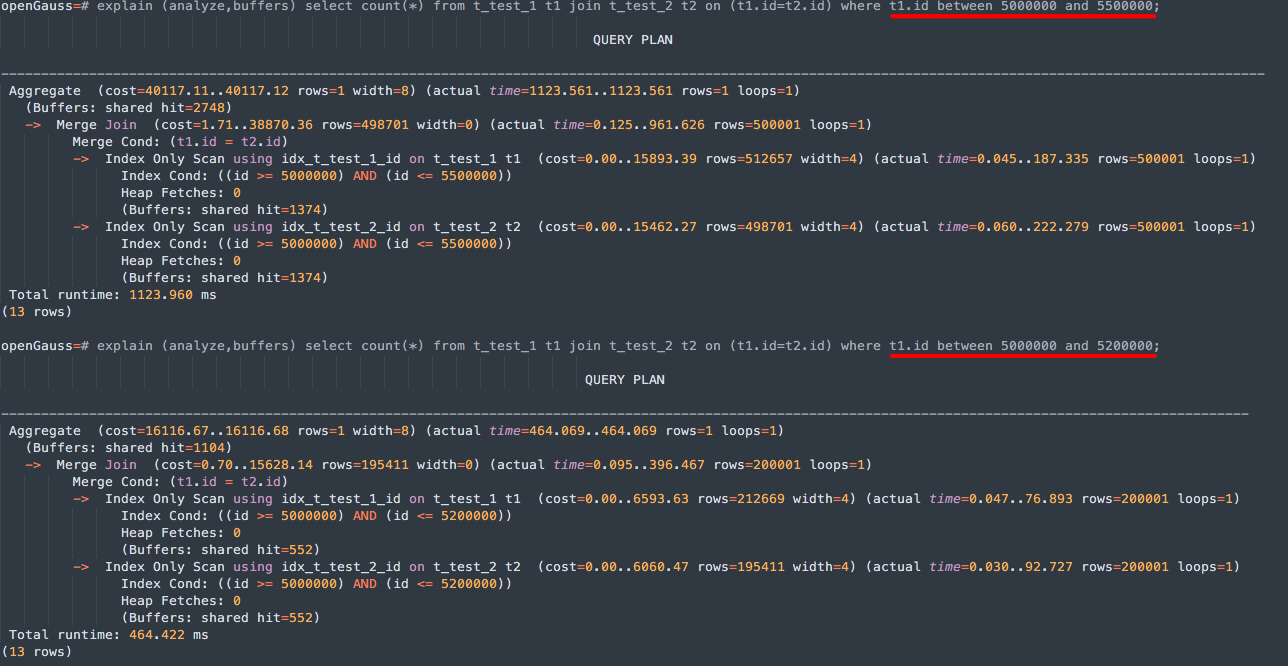
随着where条件过滤数量的变化,PostgreSQL执行计划选择的方式会跟着有所变化,openGauss都是选择merge join的执行计划,按照merge join针对数据有序的场景到也算是正常
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
