





1. 引言
我们生活在一个数据爆炸的时代,数据的巨量增长给我们的业务处理带来了压力,同时巨量的数据也给我们带来了十分可观的财富。Kafka作为大数据最核心的技术,作为一名测试人员,如果你不懂,那就真的“out”啦。今天让我们来揭开Kafka的神秘面纱。
2. Kafka应用场景
我们首先来看一下大数据智慧工厂中离线数据处理的实现流程:
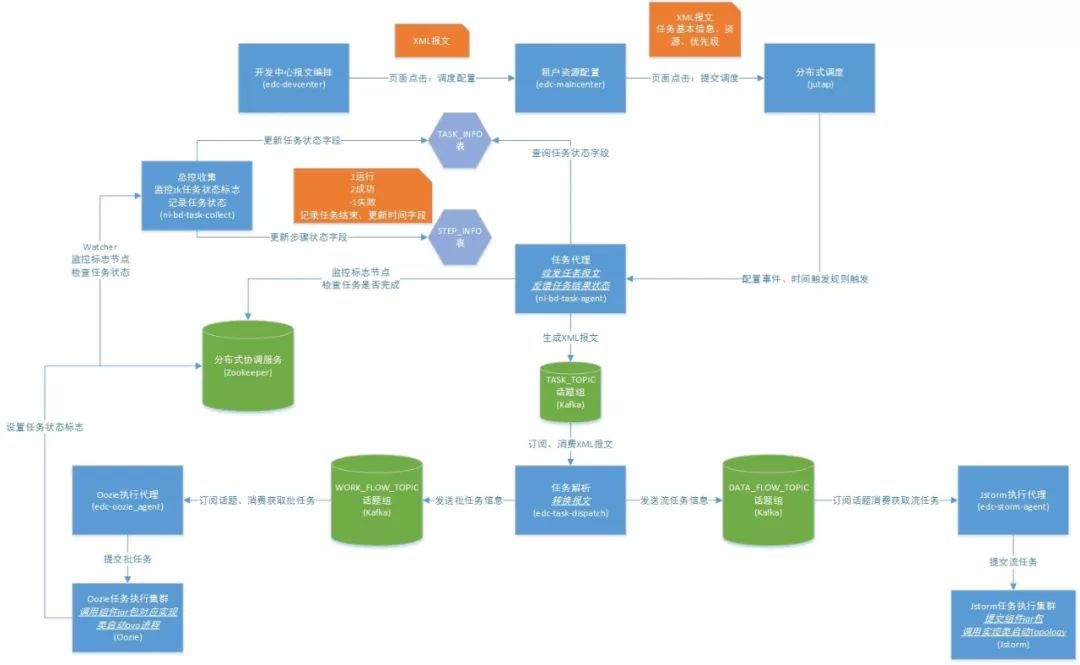
智慧工厂的离线数据处理以HADOOP框架支撑,Zookeeper(分布式应用程序协调服务)作为消息共享平台,KAFKA(分布式发布订阅消息系统)存储系统日志,JSTORM(实时消息处理系统)实时处理任务,再配合基于GANGLIA的运维中心,以达到高效的,稳定的,易维护的大数据处理平台。从以上流程图,我们可以看出Kafka的主要功能是收集各种服务的log,通过Kafka以统一接口服务的方式开放给各种consumer。除了日志收集,Kafka的应用场景还有消息系统、用户活动跟踪、运营指标、批任务和流程处理。
3. 初始Kafka
了解了Kafka的几个常见应用场景,接下来我们来看下什么是kafka?
Kafka的官方定义是:A distributed publish-subscribe messaging system。publish-subscribe是发布和订阅的意思,准确的说Kafka是一个消息订阅和发布的系统。
具体来说,Kafka 是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据。
Kafka 的总体数据流是这样的:
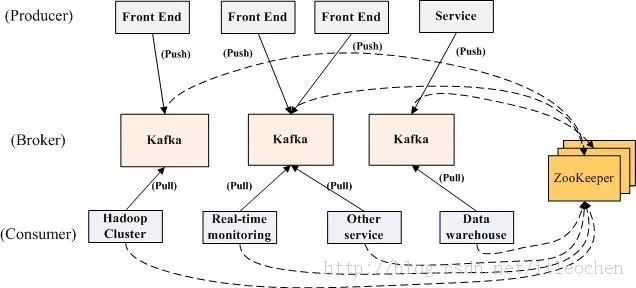
以上流程图看起来似复杂,总结起来很简单:生产者(Producer)将数据生产出来,丢给broker进行存储,消费者(Consumer)需要消费数据了,就从broker中去拿出数据来,然后完成一系列对数据的处理。
接下来介绍Kafka的两个重要组件:生产者和消费者。
3.1 生产者
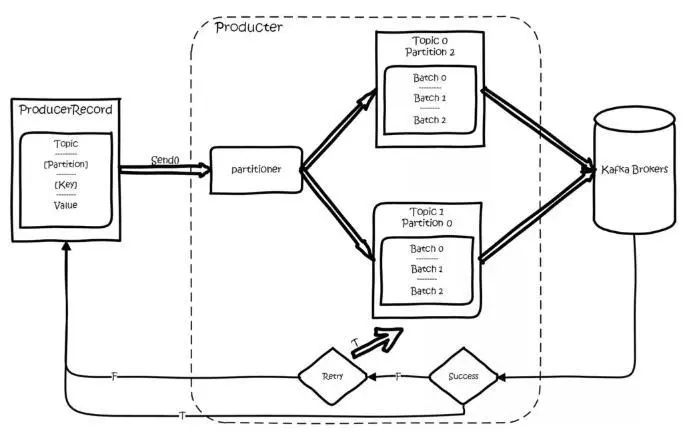
Kafka的生产者基本流程是这样的:
创建一条记录,记录中一定要指定对应的 Topic 和 Value,Key 和 Partition 可选。
先序列化,然后按照 Topic 和 Partition,放进对应的发送队列中。Kafka Produce 都是批量请求,会积攒一批,然后一起发送,不是调 send() 就立刻进行网络发包。
3.2 消费者
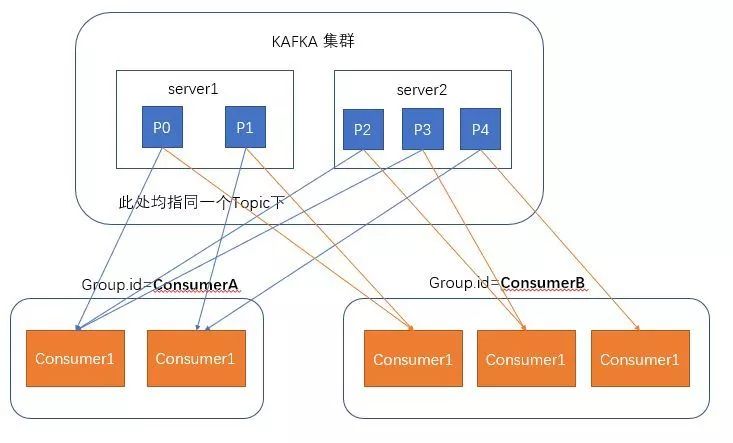
Kafka的消费者基本流程是这样的:
订阅 Topic 是以一个消费组来订阅的,一个消费组里面可以有多个消费者。同一个消费组中的两个消费者,不会同时消费一个 Partition。换句话来说,就是一个 Partition,只能被消费组里的一个消费者消费,但是可以同时被多个消费组消费。因此,如果消费组内的消费者如果比 Partition 多的话,那么就会有个别消费者一直空闲。
4. Kafka特性
Kafka作为大数据最核心的技术,其拥有以下关键的特性:
同时为发布和订阅提供高吞吐量
可进行持久化操作
分布式系统,易于向外扩展
消息被处理的状态是在consumer端维护,而不是由server端维护。当失败时能自动平衡
支持online和offline的场景
5. Kafka性能测试
通过以上介绍,相信大家对Kafka有个初步的了解,那如何证明Kafka是这么优秀呢?我们接下来做几个简单的性能测试来看下Kafka的性能。
5.1 测试环境
本次测试的环境信息由三台物理机组成,具体信息如下所示:

5.2 测试工具
Kafka-producer-perf-test.sh 该脚本被设计用于测试Producer的性能,主要输出4项指标:总共发送消息量、每秒发送消息量、发送消息总数、每秒发送消息数。
Kafka-consumer-perf-test.sh该脚本用于测试Consumer的性能,主要输出指标为:开始时间、结束时间、消费消息总大小、每秒消费大小、消费消息总条数、每秒消费条数。
6. 生产者测试
生产者测试,分别从消息长度、分区数、副本数等维度来进行。
6.1 生产者-消息长度
创建一个拥有6个分区、1个副本的Topic,分别测试消息长度为100,120,140,150,200,400字节时的集群总吞吐量。测试脚本如下:
# 创建主题
[edc_dc_dev@edc185 bin]$ ./kafka-topics.sh --create --zookeeper 10.1.4.185:2183,10.1.4.186:2183,10.1.8.149:2183/udap/kafka --topic test_producer_perf --partitions 6 --replication-factor 1
./kafka-producer-perf-test.sh --topic test_producer_perf --num-records 10000 --throughput 10000 --record-size 120 --producer-props bootstrap.servers=10.1.4.185:9092,10.1.4.186:9092,10.1.4.149:./kafka-producer-perf-test.sh --topic test_producer_perf --num-records 10000 --throughput 10000 --record-size 100 --producer-props bootstrap.servers=10.1.4.185:9092,10.1.4.186:9092,10.1.4.149:9092
9092
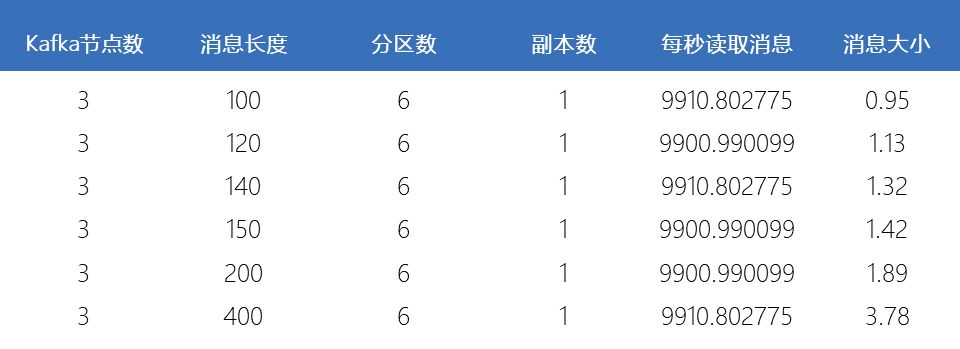
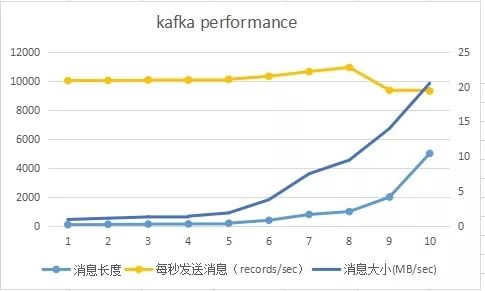
滑动查看 测试结果
由上图可见,消息越长,每秒所能发送的消息数越少,而每秒所能发送的消息的量(MB)越大。另外,每条消息除了Payload外,还包含其它Metadata,所以每秒所发送的消息量比每秒发送的消息数乘以100字节大,而Payload越大,这些Metadata占比越小,同时发送时的批量发送的消息体积越大,越容易得到更高的每秒消息量(MB/s)。
6.2 生产者-分区数
(1)分别创建1-5个分区、1个副本的主题
(2)分别测试1到5个Partition时的吞吐量
#创建Topic
./kafka-topics.sh --create --zookeeper 10.1.4.185:2183,10.1.4.186:2183,10.1.8.149:2183/udap/kafka --topic test_producer_perf_p1 --partitions 1 --replication-factor 1
./kafka-producer-perf-test.sh --topic test_producer_perf_p1 --num-records 1000000 --throughput 1000000 --record-size 100 --producer-props bootstrap.servers=10.1.4.185:9092,10.1.4.186:9092,10.1.4.149:9092
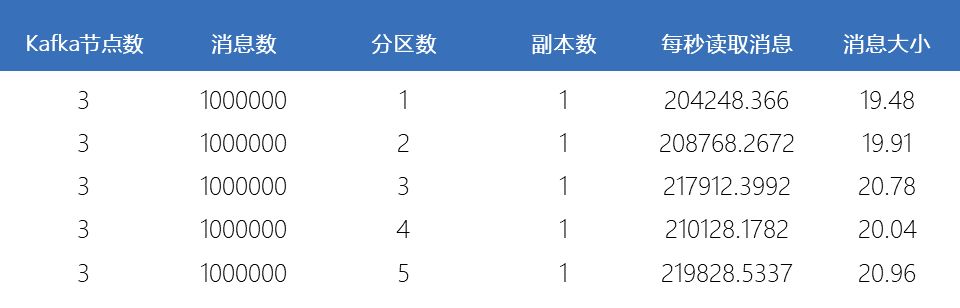
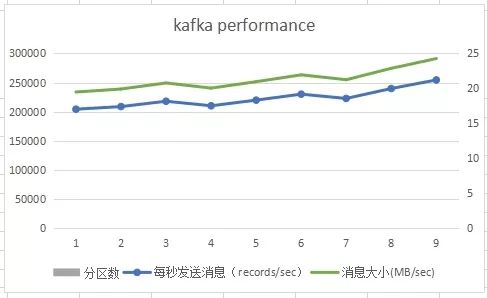
滑动查看 测试结果
由上图可知,当Partition数量小于Broker个数(3个)时,Partition数量越大,吞吐率越高,且呈线性提升。Partition数量小于等于3个时,越多的Partition代表越多的Broker为该Topic服务。不同Broker上的数据并行插入,这就解释了当Partition数量小于等于3个(Broker数量)时,吞吐率随Partition数量的增加线性提升。
6.3 生产者-副本数
(1)分别创建拥有1-3个副本、6个分区的主题;
(2)分别测试1到3个副本时,集群的吞吐率;
#创建Topic
./kafka-topics.sh --create --zookeeper 10.1.4.185:2183,10.1.4.186:2183,10.1.8.149:2183/udap/kafka --topic test_producer_perf_r1 --partitions 1 --replication-factor 1
./kafka-producer-perf-test.sh --topic test_producer_perf_r1 --num-records 1000000 --throughput 1000000 --record-size 500 --producer-props bootstrap.servers=10.1.4.185:9092,10.1.4.186:9092,10.1.4.149:9092
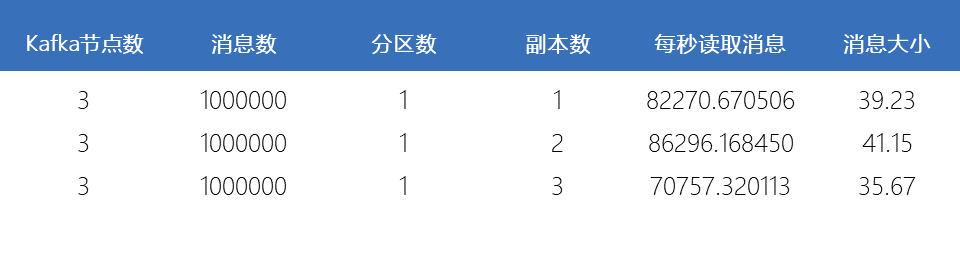
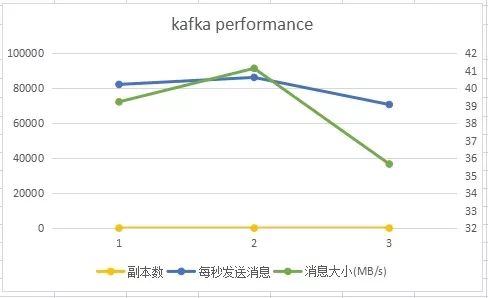
滑动查看 测试结果
由上图可知,随着Replica数量的增加,吞吐率应随之下降。但由上图可知吞吐率的下降并非线性下降,分析得出因为多个Follower的数据复制是并行进行的,而非串行进行;再结合之前测试结果分析得出因为单个吞吐率并未达到应有的吞吐率。
7. 消费者测试
消费者测试,可以从线程数、分区数、副本数等维度来进行测试。
7.1 消费者-线程数
创建一个拥有6个分区、1个备份的Topic,用不同的线程数读取相同的数据量,查看性能变化。测试脚本如下:
# 创建主题
[edc_dc_dev@edc185 bin]$ ./kafka-topics.sh --create --zookeeper 10.1.4.185:2183,10.1.4.186:2183,10.1.8.149:2183/udap/kafka --topic test_consumer_perf --partitions 6 --replication-factor 1
#生产数据
./kafka-producer-perf-test.sh --topic test_consumer_perf --num-records 1000000 --throughput 1000000 --record-size 100 --producer-props bootstrap.servers=10.1.4.185:9092,10.1.4.186:9092,10.1.4.149:9092
#消费
[edc_dc_dev@edc185 bin]$ ./kafka-consumer-perf-test.sh --broker-list 10.1.4.185:9092,10.1.4.186:9092,10.1.4.149:9092 --messages 5000000 --topic test_consumer_perf --group g1 --threads 1
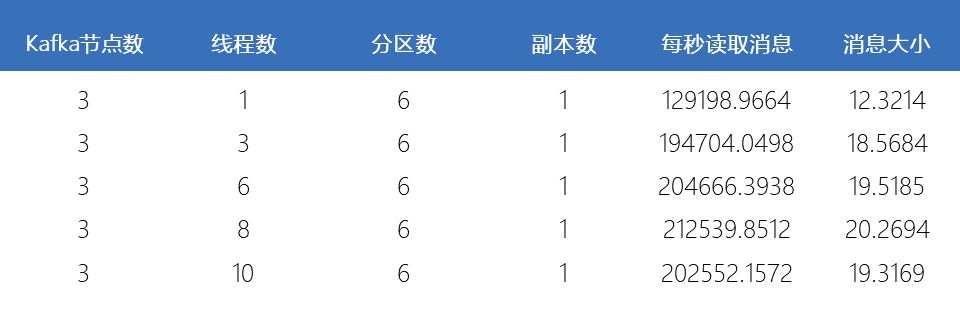
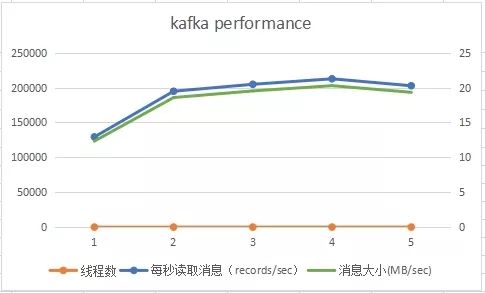
滑动查看 测试结果
随着线程数的增加,每秒读取的消息记录会逐渐增加。在线程数与消费主题的分区相等时,吞吐量达到最佳值。随后,再增加线程数,新增的线程数将会处于空闲状态,对提升消费者程序的吞吐量没有帮助。
7.2 消费者-分区数
我们首先来看一下大数据智慧工厂中离线数据处理的实现流程:
# 创建一个拥有12个分区的主题
[edc_dc_dev@edc185 bin]$ ./kafka-topics.sh --create --zookeeper 10.1.4.185:2183,10.1.4.186:2183,10.1.8.149:2183/udap/kafka --topic test_consumer_perf_p12 --partitions 12 --replication-factor 1
#生产
./kafka-producer-perf-test.sh --topic test_consumer_perf_p12 --num-records 1000000 --throughput 1000000 --record-size 100 --producer-props bootstrap.servers=10.1.4.185:9092,10.1.4.186:9092,10.1.4.149:9092
# 用一个线程读取数据到拥有6个分区的主题中
[edc_dc_dev@edc185 bin]$ ./kafka-consumer-perf-test.sh --broker-list 10.1.4.185:9092,10.1.4.186:9092,10.1.4.149:9092 --messages 5000000 --topic test_consumer_perf --group g1 --threads 1
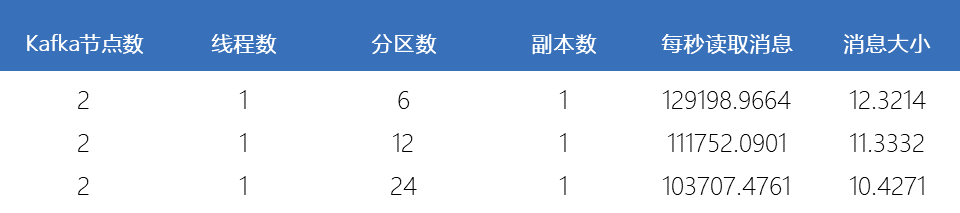
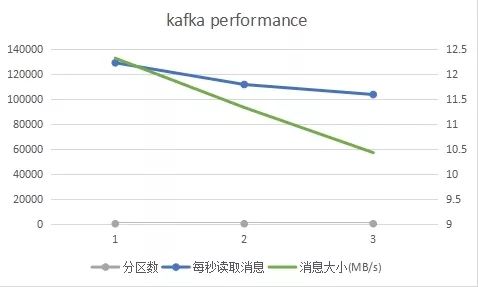
滑动查看 测试结果
由上图可知,当分区数增加时,如果线程数保持不变,则消费者程序的吞吐量性能会下降。
7.3 消费者-副本数
新建Topic,改变Topic的副本数,读取相同数量的消息记录,查看性能变化。
# 创建一个有用两个副本、6个分区的主题
[edc_dc_dev@edc185 bin]$ ./kafka-topics.sh --create --zookeeper 10.1.4.185:2183,10.1.4.186:2183,10.1.8.149:2183/udap/kafka --topic test_consumer_perf_r2 --partitions 6 --replication-factor 2
#生产
./kafka-producer-perf-test.sh --topic test_consumer_perf_r2 --num-records 1000000 --throughput 1000000 --record-size 100 --producer-props bootstrap.servers=10.1.4.185:9092,10.1.4.186:9092,10.1.4.149:9092
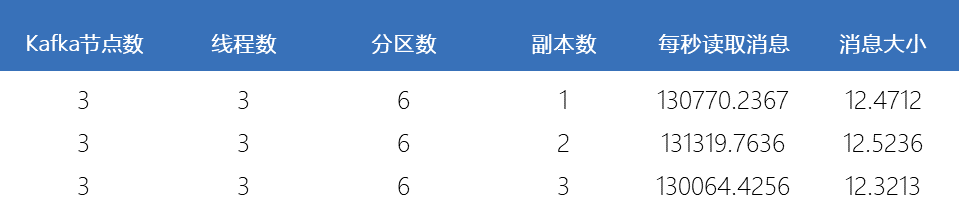
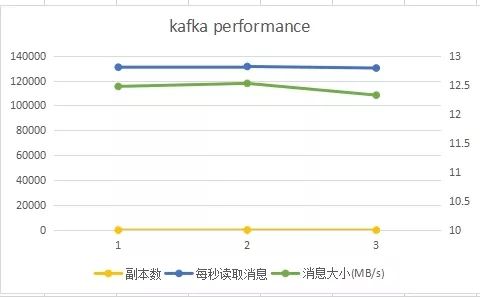
滑动查看 测试结果
由上图可知,副本数对消费者程序的吞吐量影响较小,消费者程序是从Topic的每个分区的Leader上读取数据的,而与副本数无关。
8. 结语
以上初步介绍了Kafka的基础知识以及重点特性,并结合智慧工厂离线数据处理场景分享了Kafka的几种常见应用场景,简要使用工具通过压力测试了解了Kafka的部分关键性能指标,相信大家对Kafka有了初步的了解,当然Kafka的应用以及功能远不止于此,感兴趣的同学可以通过网络各种学习材料,结合项目实践更进一步了解Kafka的强大之处。我有砖,你有玉么?欢迎大家共同分享见解。
- THE END -

新大陆软件评测中心
地址:福州市经济开发区儒江大道1号新大陆科技园B楼3层
邮箱:nlsetc@newland.com.cn
电话:0591-8397 9159
专业测试,成就卓越
