




前言
一般我们遇到 SQL 性能问题,手段比较有限,诸如分析执行计划 (PEV),改写 SQL,加索引等等,这些也要求一定的经验与功力。
其次作为 DBA,开发也会经常挑战我们,单个 SQL 会消耗多少内存?多少 CPU?不借助额外插件(比如 pg_stat_kcache)的话,我们是无法知晓的。正好最近也一直在捣鼓 SQL 优化相关的事情,今天在学习过程中,又发现了一个十分有价值的 SQL 性能分析工具——ExplainFull,按照当下手机厂商时髦的叫法,不如就取名为 Explain Plus 吧。
DSEF
地址在 https://github.com/ardentperf/dsef/,DSEF 的全称是 DiffStats and ExplainFull
DiffStats and ExplainFull can generate detailed reports which are useful for troubleshooting performance of a SQL statement, and especially for working with third parties who are helping in the process. It reduces the amount of back-and-forth requests for information by capturing a great deal of commonly useful data about the performance of a SQL statement.
DiffStats 和ExplainFull 可以生成详细的报告,这些报告对于解决SQL 语句的性能问题非常有用。
安装很简单,1分钟搞定,因为是几个纯文本函数,所以 psql -f 直接导入至数据库中即可。
curl -O https://raw.githubusercontent.com/ardentperf/dsef/main/sql/dsef.sql
psql <dsef.sql
当然你也可以以插件的形式进行安装,此处不再演示。目前 DSEF 暂不支持在备库或者只读库中使用。
另外,如果还有 pg_proctab 插件的话,还可以收集操作系统级别的统计信息,比如 CPU/内存/磁盘等等,和 EDB 的 system_stats 插件类似。
postgres=# \dx+ pg_proctab
Objects in extension "pg_proctab"
Object description
-------------------------
function pg_cputime()
function pg_diskusage()
function pg_loadavg()
function pg_memusage()
function pg_proctab()
(5 rows)
DSEF 还支持收集系统级和会话级的等待事件详情,不过可惜的是,目前只在 Aurora 上支持
If pg_proctab is available, DSEF will use it to include all available Operating System statistics in its report. On Aurora, DSEF will include wait event statistics at both the system and session level in its report. With appropriate privileges, DSEF can be installed as an extension on self-hosted PostgreSQL and on RDS PosgreSQL 14.5+
小试牛刀
介绍完了之后,让我们实操一下,使用形式很简单,只需要 select * from explain_analyze_full + 实际的查询语句即可,此处我构造了一个两表关联的查询语句,由于内容过长,让我们分开来看
postgres=# select * from explain_analyze_full('SELECT
Students.StudentID,
Students.FirstName,
Students.LastName,
Enrollments.CourseName,
Enrollments.Grade
FROM
Students
INNER JOIN
Enrollments ON Students.StudentID = Enrollments.StudentID
ORDER BY
Students.StudentID, Enrollments.CourseName
LIMIT 10;');
NOTICE: INFO: EXPLAIN (ANALYZE,VERBOSE,COSTS,BUFFERS,FORMAT TEXT,TIMING,SETTINGS,WAL) SELECT
Students.StudentID,
Students.FirstName,
Students.LastName,
Enrollments.CourseName,
Enrollments.Grade
FROM
Students
INNER JOIN
Enrollments ON Students.StudentID = Enrollments.StudentID
ORDER BY
Students.StudentID, Enrollments.CourseName
LIMIT 10;
NOTICE: INFO: query execution complete; now resetting client_min_messages
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
__________ DSEF for PostgreSQL (DiffStats & ExplainFull) Version: 2024.4.9 __________
clock_timestamp: 2024-05-08 11:53:37.743692+08
pg_version: PostgreSQL 16.1 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44), 64-bit
EXPLAIN (ANALYZE,VERBOSE,COSTS,BUFFERS,FORMAT TEXT,TIMING,SETTINGS,WAL) SELECT +
Students.StudentID, +
Students.FirstName, +
Students.LastName, +
Enrollments.CourseName, +
Enrollments.Grade +
FROM +
Students +
INNER JOIN +
Enrollments ON Students.StudentID = Enrollments.StudentID +
ORDER BY +
Students.StudentID, Enrollments.CourseName +
LIMIT 10;
Limit (cost=2.20..8.43 rows=10 width=59) (actual time=0.145..0.149 rows=10 loops=1)
Output: students.studentid, students.firstname, students.lastname, enrollments.coursename, enrollments.grade
Buffers: shared hit=18
-> Incremental Sort (cost=2.20..62248.26 rows=100000 width=59) (actual time=0.143..0.145 rows=10 loops=1)
Output: students.studentid, students.firstname, students.lastname, enrollments.coursename, enrollments.grade
Sort Key: students.studentid, enrollments.coursename
Presorted Key: students.studentid
Full-sort Groups: 1 Sort Method: quicksort Average Memory: 26kB Peak Memory: 26kB
Buffers: shared hit=18
-> Merge Join (cost=1.62..57748.26 rows=100000 width=59) (actual time=0.043..0.126 rows=11 loops=1)
Output: students.studentid, students.firstname, students.lastname, enrollments.coursename, enrollments.grade
Merge Cond: (students.studentid = enrollments.studentid)
Buffers: shared hit=18
-> Index Scan using students_pkey on public.students (cost=0.42..36292.43 rows=1000000 width=47) (actual time=0.020..0.056 rows=112 loops=1)
Output: students.studentid, students.firstname, students.lastname, students.birthdate
Buffers: shared hit=5
-> Index Scan using idx_enrollments_student on public.enrollments (cost=0.29..17708.20 rows=100000 width=16) (actual time=0.016..0.035 rows=11 loops=1)
Output: enrollments.enrollmentid, enrollments.studentid, enrollments.coursename, enrollments.grade
Buffers: shared hit=13
Settings: temp_buffers = '128MB', work_mem = '16MB', max_parallel_workers_per_gather = '4', max_parallel_workers = '4'
Query Identifier: 1238912577162965004
Planning:
Buffers: shared hit=58
Planning Time: 0.613 ms
Execution Time: 0.187 ms
前面的内容相当于帮你加上了 EXPLAIN (ANALYZE,VERBOSE,COSTS,BUFFERS,FORMAT TEXT,TIMING,SETTINGS,WAL) ,并且很贴心地给你打印出来了 Query Identifier。后面的内容就比较有价值了,还会将一些关键性的数据,比如 pg_class.reltuples、relpages,MCV、直方图、空值比例等等都打印出来,其次还会将利用到的索引状态,比如元组数,是否是唯一索引等等,都打印出来,有了 MCV,我们就可以快速判断出这个 SQL 是否可以直接利用 MCV + MCF 计算出选择率。
Table public.enrollments: pages 637, tuples 100000, allvisible 637, kind r
enrollmentid integer: stattarget -1, notnull true, null_frac 0, avg_width 4, n_dist -1, corr 1, hist[101] {1000001,1000973,1001946...1098029,1098960,1099998}
studentid integer: stattarget -1, notnull false, null_frac 0, avg_width 4, n_dist -0.92434, corr -0.0069810874, hist[101] {2,9586,20007,30105,4038...97,980109,990165,999934}
coursename character varying(100): stattarget -1, notnull false, null_frac 0, avg_width 9, n_dist 4, corr 0.2873922, hist[] NULL
mcv {Biology,Chemistry,Physi...try,Physics,Mathematics}, mcf {0.37656668,0.2496,0.247....2496,0.2476,0.12623334}
grade character(2): stattarget -1, notnull false, null_frac 0, avg_width 3, n_dist 6, corr 0.17525461, hist[] NULL
mcv {"D ","E ","B ","C ","F ...E ","B ","C ","F ","A "}, mcf {0.20266667,0.1996,0.198....19896667,0.1007,0.0991}
Index enrollments_pkey btree (enrollmentid): pages 3018, tuples 100000, nkeyatts 1, isunique true, nullsnotdist false, isclustered false, isvalid true
Index idx_enrollments_course btree (coursename): pages 872, tuples 100000, nkeyatts 1, isunique false, nullsnotdist false, isclustered false, isvalid true
Index idx_enrollments_student btree (studentid): pages 3415, tuples 100000, nkeyatts 1, isunique false, nullsnotdist false, isclustered false, isvalid true
Table public.students: pages 10309, tuples 1e+06, allvisible 10309, kind r
studentid integer: stattarget -1, notnull true, null_frac 0, avg_width 4, n_dist -1, corr 1, hist[101] {48,10711,19639,29541,39...04,979193,989214,999983}
firstname character varying(50): stattarget -1, notnull false, null_frac 0, avg_width 22, n_dist -1, corr 0.81690574, hist[101] {StudentFirstName100010,...,StudentFirstName999983}
lastname character varying(50): stattarget -1, notnull false, null_frac 0, avg_width 21, n_dist -1, corr 0.81690574, hist[101] {StudentLastName100010,S...4,StudentLastName999983}
birthdate date: stattarget -1, notnull false, null_frac 0, avg_width 4, n_dist 365, corr 0.012707572, hist[101] {2000-01-01,2000-01-04,2...3,2000-12-27,2000-12-30}
mcv {2000-08-04,2000-09-04,2...4,2000-11-23,2000-09-03}, mcf {0.0036,0.0036,0.0035,0....036,0.0035,0.0034666667}
Index students_pkey btree (studentid): pages 2745, tuples 1e+06, nkeyatts 1, isunique true, nullsnotdist false, isclustered false, isvalid true
Index idx_students_name btree (firstname, lastname): pages 13675, tuples 1e+06, nkeyatts 2, isunique false, nullsnotdist false, isclustered false, isvalid true
其次是一些系统级的参数
name | setting | unit | source
--------------------------+---------+------+--------
deadlock_timeout | 1 | ms | session
debug_pretty_print | on | | default
debug_print_parse | off | | default
debug_print_plan | off | | default
debug_print_rewritten | off | | default
default_statistics_target | 100 | | default
log_executor_stats | off | | default
log_lock_waits | on | | session
log_min_messages | panic | | session
log_parser_stats | off | | default
log_planner_stats | off | | default
log_temp_files | 0 | kB | session
track_counts | on | | session
track_functions | all | | session
track_io_timing | on | | session
track_wal_io_timing | on | | session
CURRENT_USER = postgres (IS superuser, DOES bypass RLS)
(77 rows)
功能到这就结束了吗?NONONO,DSEF 还支持比较同一个 SQL 不同执行计划间资源消耗情况,比如我想对比走索引和不走索引之间的性能差异和资源消耗情况,我该怎么做?借助 ds_capture() 即可
select ds_start();
select * from explain_analyze_full($$ select * from customers c,customers2 c2 where c.id=c2.id limit 1000 $$);
select * from ds_capture();
set enable_indexscan=off;
select * from explain_analyze_full($$ select * from customers c,customers2 c2 where c.id=c2.id limit 1000 $$);
select pg_sleep(0.05); select * from ds_report_diff();
看个例子 (内容过多,我这里就贴了部分)
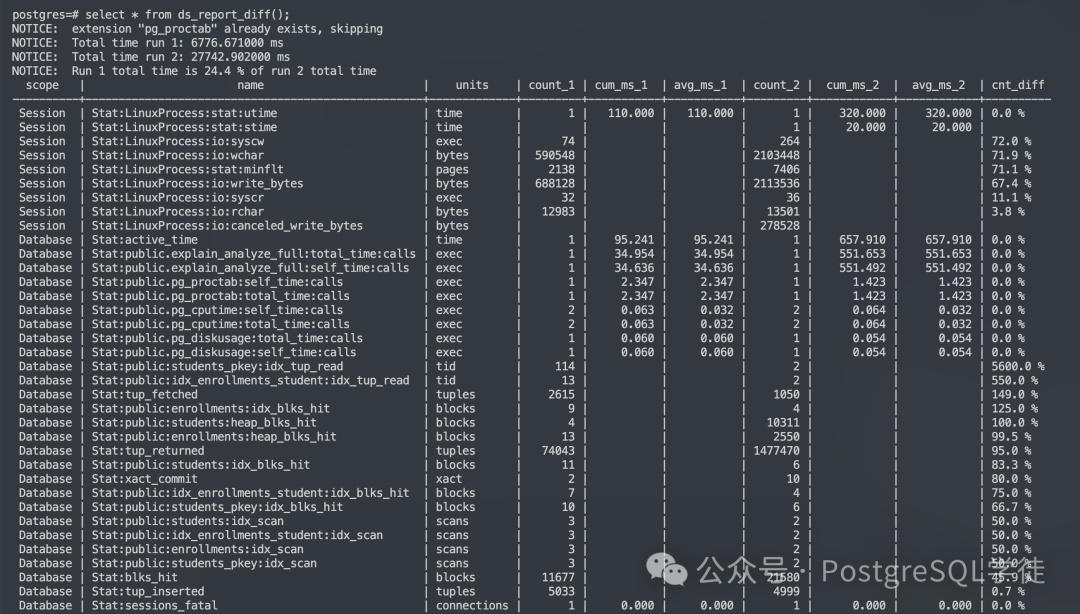
可以看到,前后两次的 cnt_diff 都列举了出来,比如 IO 增加了 72%,总时间的差异等等。关于这些性能指标的解读,可以参照 pg_proctab: Accessing System Stats in PostgreSQL,无疑,有了 DSEF,可以大大方便我们对比分析不同的访问路径,而不仅仅只是从一个 Execution time 来对比,给作者打 call!

小结
赶紧用起来吧!SQL 性能诊断利器+1。下一期与各位分享等待事件的诊断利器。
参考
https://github.com/ardentperf/dsef/
