




PostgreSQL 基于 bloom filter(布隆过滤器) 提供了一种索引方法 bloom。
bloom filter
1970年由 Burton Howard Bloom 提出。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率,删除元素比较困难。
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组(也称为签名 signature )中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在,还需要进一步检查才能确认。这就是布隆过滤器的基本思想。
下面是一个 bloom filter 的示例,将集合中的元素映射到一个位数组(bit array)的多个位上,示例中是3个位,对应的位设置为1。检查一个元素是否在集合中时,通过计算检查对应的位是否全是1,如果不是则可以确定元素不在集合中。如果所有位置全部是1,并不能确定元素一定在集合中,因为不同元素映射时会出现位重合的情况,因此需要进一步检查。通常位数组的长度越大,每个元素映射的位数越大,判断的精度相对越高,但空间占用也越大。
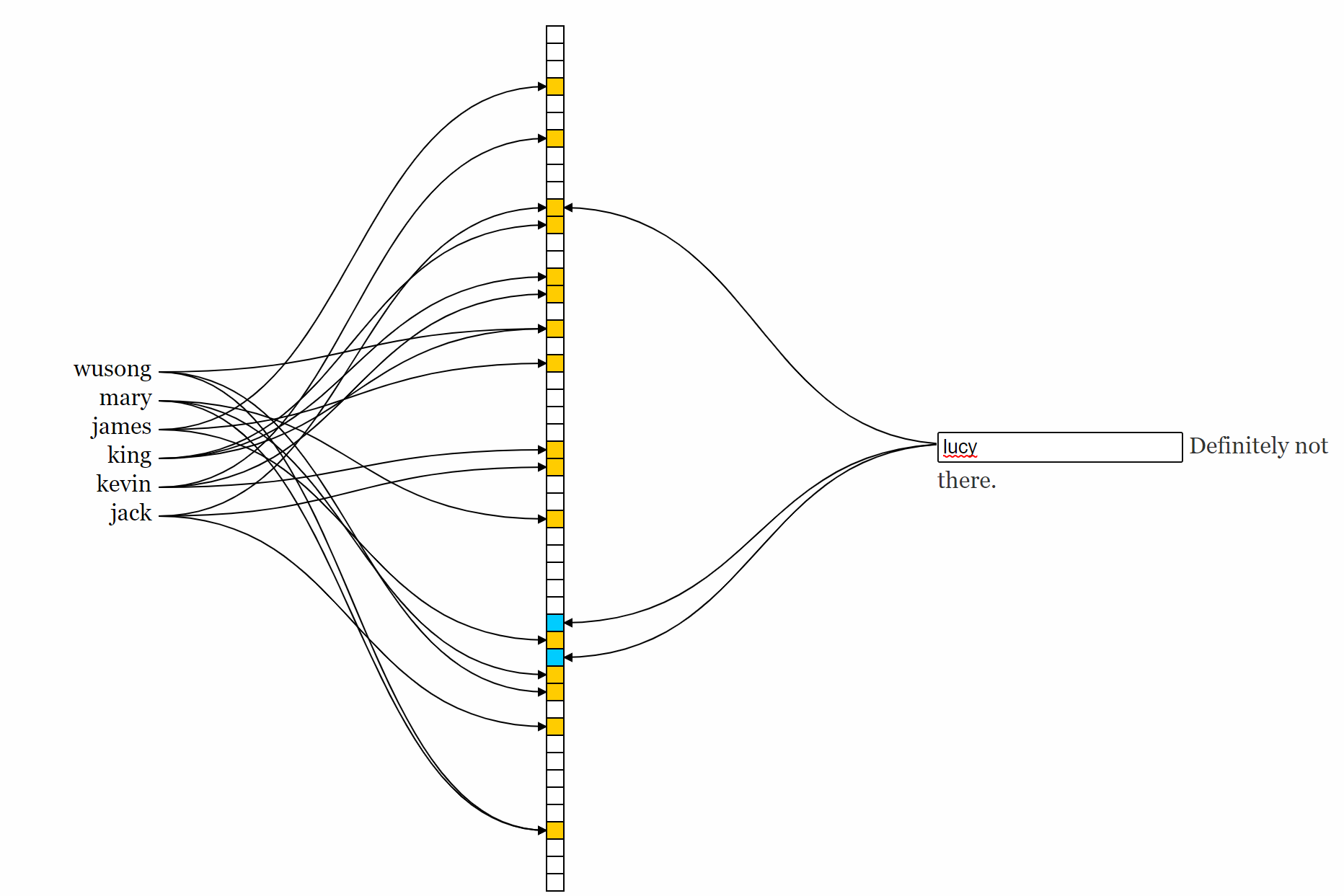
bloom 索引
bloom 索引在 PG 中是以插件的方式提供,在使用之前需要先执行:
CREATE EXTENSION bloom;
PG 中的 bloom filter 主要处理用于多列随机组合查询的场景。这种场景下传统的索引,如 btree 查找速度很快,但是可能需要建很多的 btree 索引,才能支持任意列的随机组合查询,索引本身的开销也比较大,而 bloom 索引可以很好地处理。
参数
length
Length 表示索引最终的签名的长度。输入的数字最终会向上取整到16的整数倍。默认值是80,最大值是4096。
col1 — col32
为每个索引列生成的位数。 每个参数的名称是指它控制的索引列的编号。默认值是2位,最大值为 4095。未实际使用的索引列的参数将被忽略。
CREATE INDEX bloomidx ON tbloom USING bloom (i1,i2,i3)
WITH (length=80, col1=2, col2=2, col3=4);
索引签名的长度是80位,i1和i2映射到2位,i3映射到4位。
使用限制:
- 支持的 operator class 只有 int4 和 text
- 目前操作符只支持 =
- 不支持 unique index
- 不支持索引 NULL 值
bloom 索引实现
bloom 索引 Page 有两种,
一种是 Meta-page,记录索引的元数据信息,如 bloom 索引使用多长的 bitmap,每一列用几位表示等
另一种是真正记录索引数据的 Page。这一点与 btree 索引比较类似。
索引 Page 格式
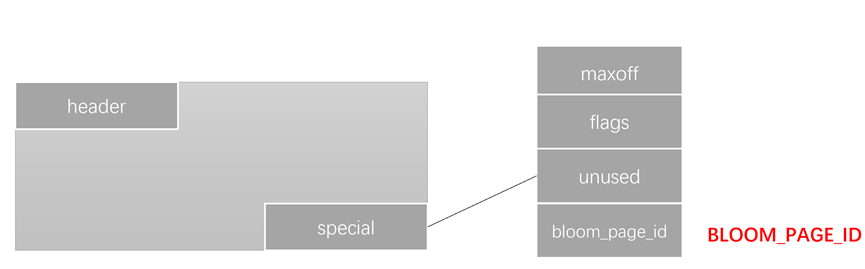
bloom 索引 Page 的格式如上图所示,其中
maxoff 记录索引 Page 内 index tuple 的数量
flags 记录索引的信息,如 Page 是否是 meta-page,以及 Page 是否被删除。
unused 未使用区域,占位用于对齐,并使 bloom_page_id 位于页面尾部
bloom_page_id 固定值,用于标识 Page 是一个 bloom index 的 Page
Mata-page 数据

notFullPage 是一个数组,记录的内容是 block number,表示当前哪些索引 Page 未写满。插入的时候可以向未写满的 Page 执行插入。
nStart 是 notFullPage 数组的下标,用于标识查找 notFullPage 的起始位置。
nEnd 是 notFullPage 数组的下标,用于标识查找 notFullPage 的结束位置。
opt 是 bloom 索引的 options,例如 bitmap 的长度,每一个索引列使用几位表示等。
Index Tuple
索引数据的格式如下,一个 Page 内存放多个 index tuple,index tuple 的数量记录在 special 区域的 maxoff 中。

其中,ctid 是 heap tuple 的 line pointer;
sign 是一行数据经过计算后的 bitmap,不同列在计算 bitmap 时列号会参与 bitmap 的计算,这样如果有两列的类型和取值相同,计算出的 bitmap 也会不同。
索引流程
构建索引
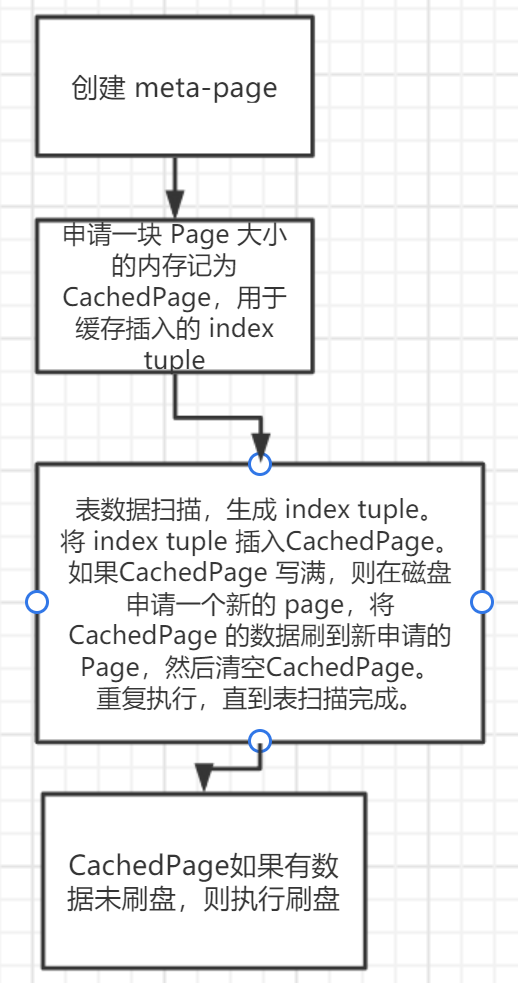
插入索引
- 组装 index tuple
- 读取 meta-page,获得 nStart, nEnd,和 notFullPage
- 如果 nEnd > nStart,读取 notFullPage[nStart],将 index tuple 插入对应的 page 中,如果成功插入,则流程结束。否则,重新从 meta-page 中读取 nStart,检查 notFullPage[nStart]是上次读到的 blockno,然后 nStart++。重复执行。
- nStart >= nEnd,表示 notFullPage 没有找到合适的位置插入,或者是第一次插入索引数据。申请一个新的 page ,将 index tuple 插入。设置 nStart = 0,nEnd = 1,notFullPage[nStart] 设置为新申请的 page 的 blkno。
索引查询
bloom 索引只支持 bitmap scan。
查找流程如下:
- 根据 scankey 计算出查找key 对应的 bitmap,记为 so->sign
- 扫描 index page,获取每一个 index tuple 的 sign,记为 itup->sign。通过 so->sign 和 itup->sign 确定 scankey 是否可能出现在对应的 index tuple 指向的 heap tuple,如果可能,将对应的 ctid 加入 TIDBitmap。
- 返回符合条件的 index tuple 的数量,以及 TIDBitmap。
参考文档:
https://en.wikipedia.org/wiki/Bloom_filter
https://www.postgresql.org/docs/current/bloom.html
https://www.jasondavies.com/bloomfilter/
