vacuum主要用于
- 清除死元组并对每个活元组进行碎片整理
- 删除指向死元组的索引元组
- 冻结旧原组的txid
- 更新统计信息以及空闲空间、可见性地图
vacuum处理流程
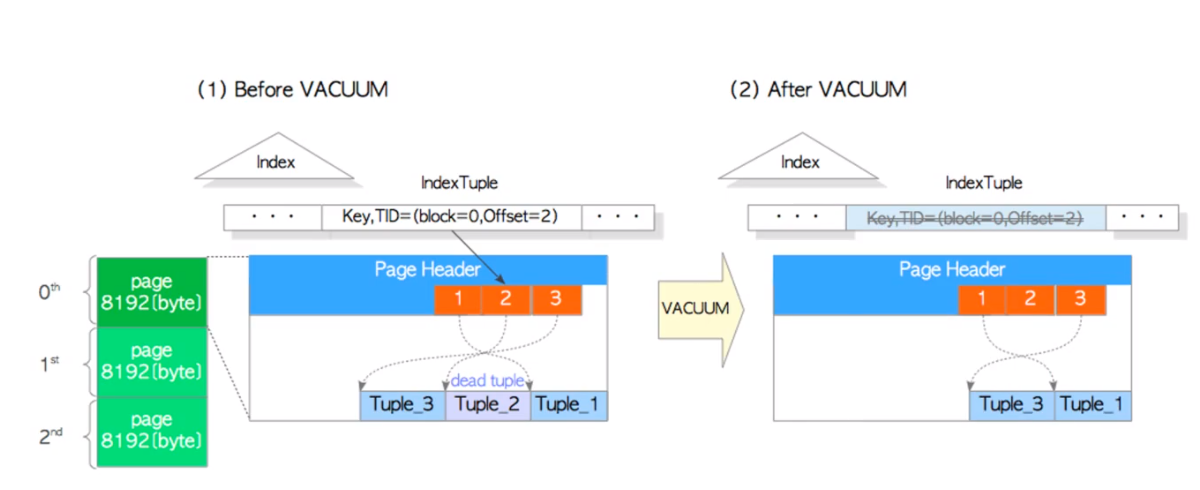
可见性地图
提高vacuum效率,可见性地图用于标记哪些被删除行的数据库的id,用于vacuum参考
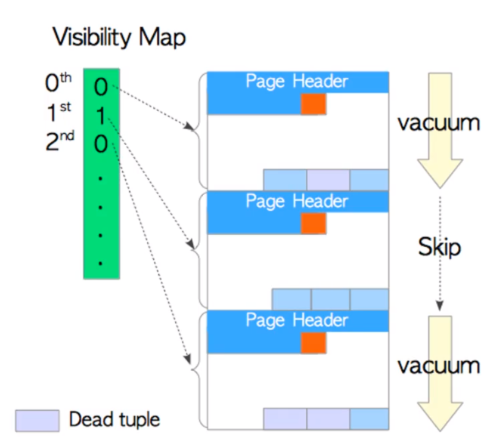
full vacuum 操作
当前3个块中每个块只剩下1行数据,如果只是单纯做vacuum操作,那么只是将死元组信息给清除,当做全表扫描时,需要进行多次I/O才能获取到数据
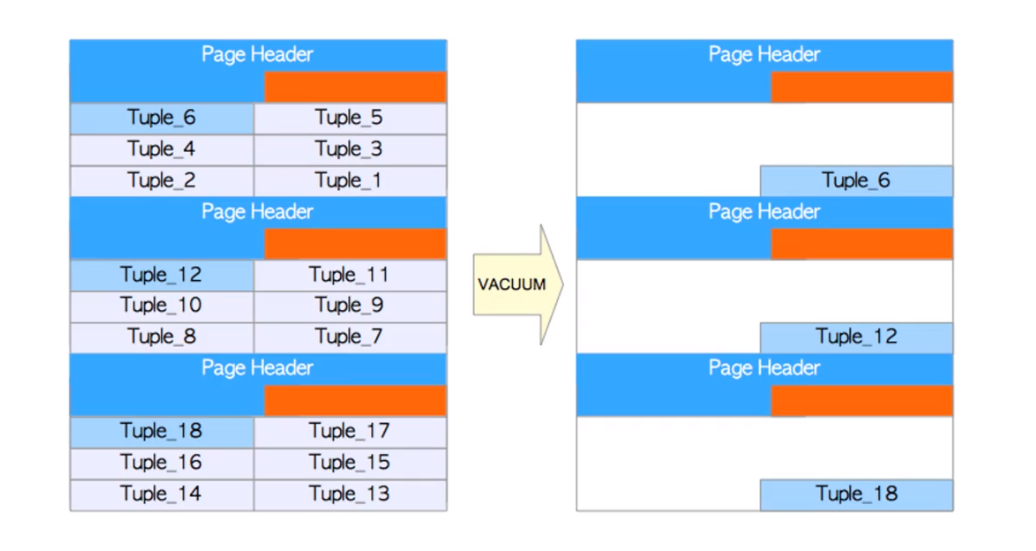
而full vacuum操作会对其创建1个新的数据文件,将原有3个块中行迁移到一个新的数据块中,而后释放旧的数据块
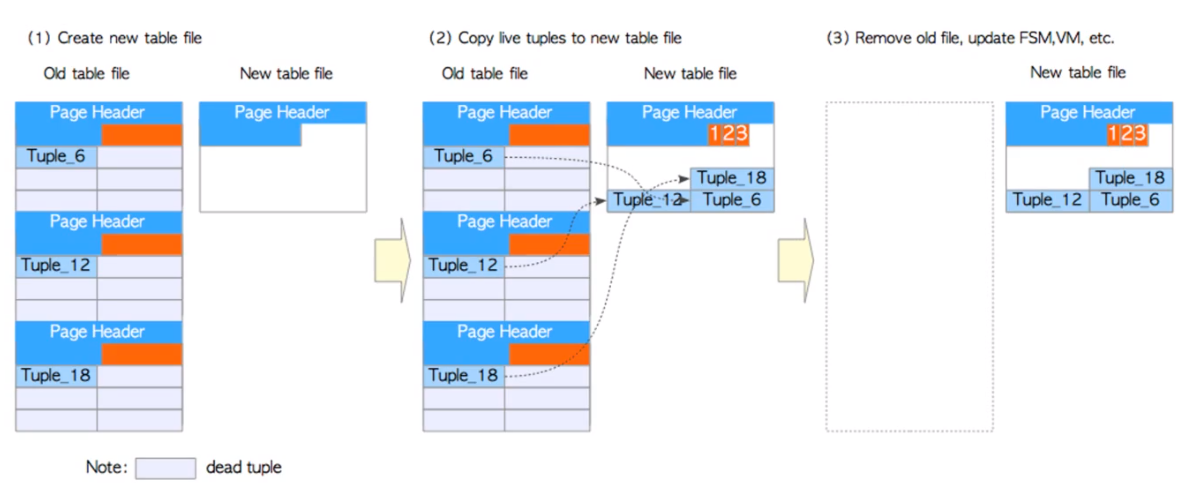
如何正确使用FULL VACUUM操作
create table a(id int,info text,time timestamp);
insert into a select generate_series(1,100000),md5(random()::text),clock_timestamp();
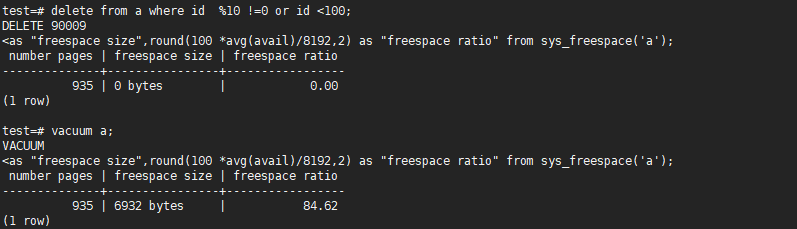
select count(*) as "number pages",sys_size_pretty(cast(avg(avail) as bigint)) as "freespace size",round(100 *avg(avail)/8192,2) as "freespace ratio" from sys_freespace('a');

delete from a where id %10 !=0 or id <100;

auto vacuum
vacuum操作每分钟执行一次,由参数autovacuum_naptime控制。默认调用3个进行进行工作,由参数autovacuum_max_workers控制
autovacuum_vacuum_scale_factor * number of tuple +autovacuum_vacuum_threshold
autovacuum analyze触发条件:自上次以来插入、更新、删除总数超过此阈值的任何表
autovacuum_analyze_scale_factor * number of tuple +autovacuum_analyze_threshold
autovacuum操作会导致短期内产生大量的I/O,可设置一些参数来减少对I/O的影响
autovacuum_vacuum_cost_limit:autovacuum可达到的总成本上线。默认-1不做限制,如果是SSD硬盘可以把该值设置为5000-10000,如果是一般带缓存的硬件Raid卡输出的机械硬盘,则设置为1000~2000比较合适。过大会导致I/O瓶颈
autovacuum_vacuum_cost_delay:当一个清理工作达到autovacuum_vacuum_cost_limit上线时,autovacuum将休眠毫秒。默认2ms
vacuum_cost_page_hit:读取已经存在共享缓冲区中且不需要磁盘读取页的成本,默认 1
vacuum_cost_page_miss:获取不在共享缓冲区中页的成本,默认10
vacuum_cost_page_dirty:在每一页发现死元组时写入该页的成本,默认20
autovacuum_max_workers=3
autovacuum_naptime=1min
在无延迟的情况下,在做autovacuum时1s的工作量时多少 。假设autovacuum_vacuum_cost_limit=200、autovacuum_vacuum_cost_delay=2ms、vacuum_cost_page_hit=1、vacuum_cost_page_miss=10、vacuum_cost_page_dirty=201000ms = 500 * autovacuum_vacuum_cost_delay由于在共享内存每次读取的成本为1,因此每个唤醒中可以读取200个页面。在500个唤醒中可以读取500 * 200个页面如果在共享内存中找到具有死元组的页,并且autovacuum代价延迟为20ms,则在每一轮读取((200/vacuum_cost_page_hit)* 8)KB考虑到块大小为8192字节,autovacuum在共享内存中最多可以读取(500 * 200 * 8kb)=781.3mb/s若块不在共享内存中,需从磁盘读取时,则autovacuum可以读取500 * (200/vacuum_cost_page_miss) * 8)KB =78.1mb/s为了从页/块中删除死元组,则autovacuum每秒最多写500 * (200/vacuum_cost_page_dirty) * 8)KB =39mb/s
死元组可通过视图sys_stat_user_tables或创建扩展kbstattuple查看
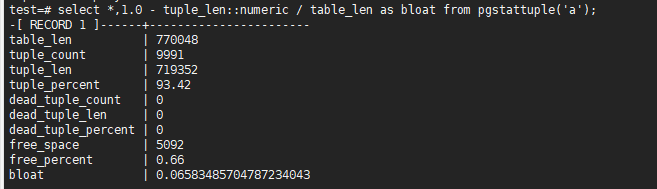
select *,1.0 - tuple_len::numeric / table_len as bloat from pgstattuple('a');