




一、前言
最近网上冲浪的时候,翻着翻着翻到一篇有趣的文章,估摸着应该是盖老师写的。文中有个测试例子引起了我的兴趣,原文如下:
借用一下文中的例子如下所示:
/* table1 */
create table enmotech (id number,name varchar2(20));
insert into enmotech values(1,'Eygle');
/* table2 */
create table enmotest (id number);
insert into enmotest values(1);
/* 问:在enmotest 表中,不存在 name 字段,当前查询能否正常执行?*/
select * from enmotech where name in (select name from enmotest);思考一下能否正确执行,如果能,那么输出结果是什么?
二、是否能正常执行呢?
不想动脑子的情况下,能不能执行,测试一下,不就知道了吗?再借用下文中的测试结果
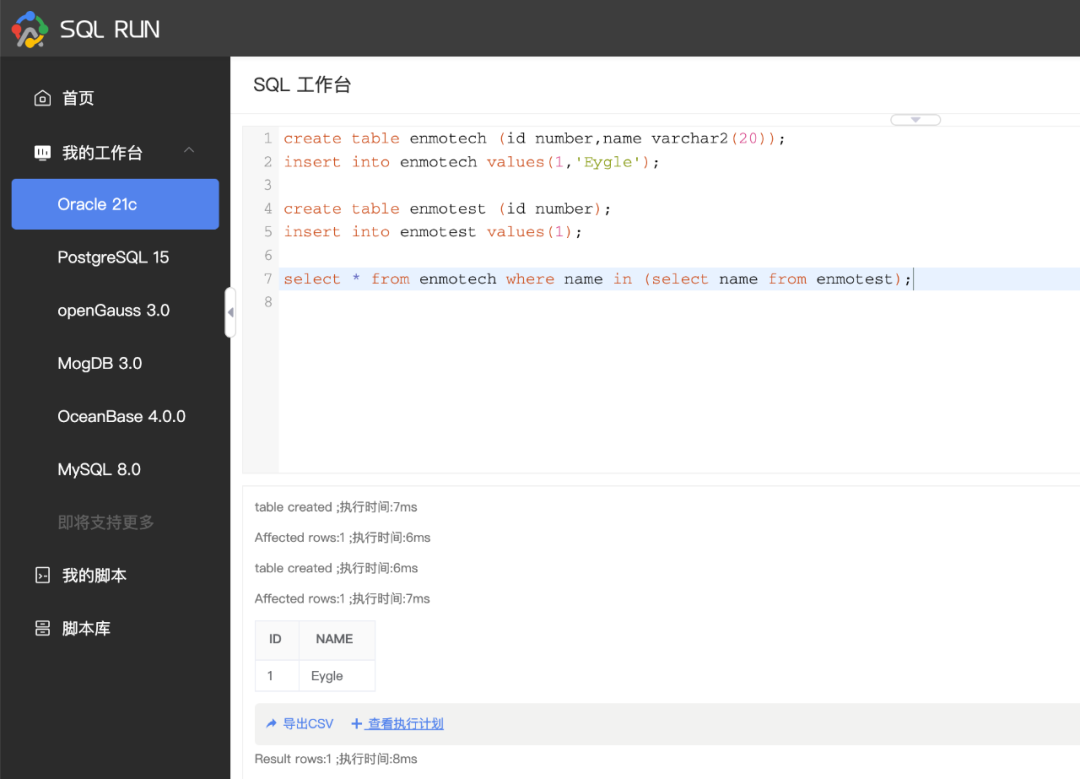
在Oracle的执行结果如下:
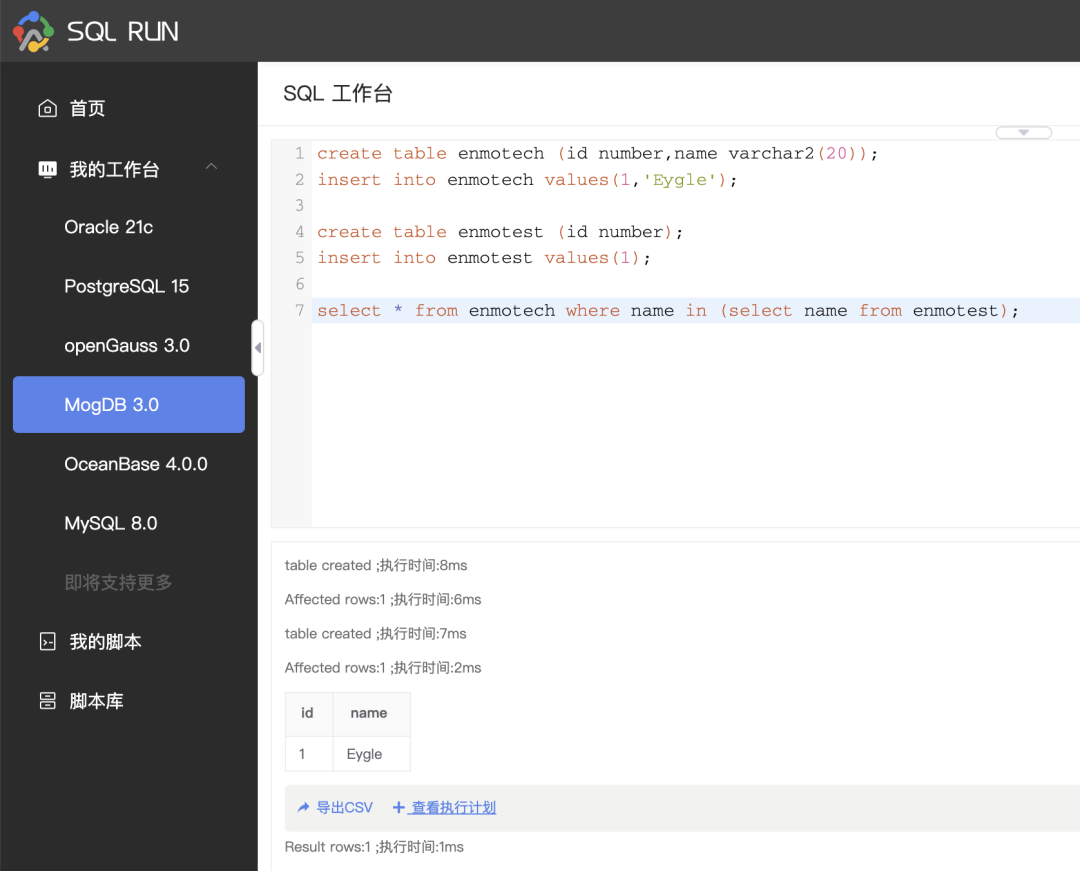
在MogDB的执行结果如下:
再顺带补充两个测试结果
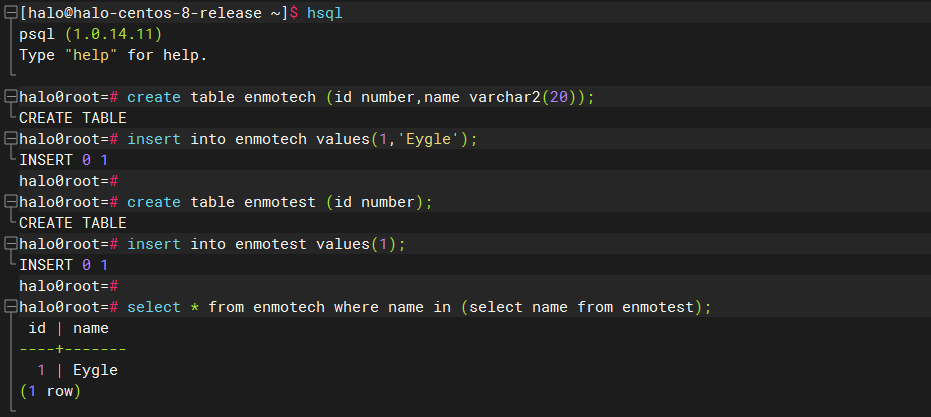
在羲和(Halo)数据库的执行结果如下:
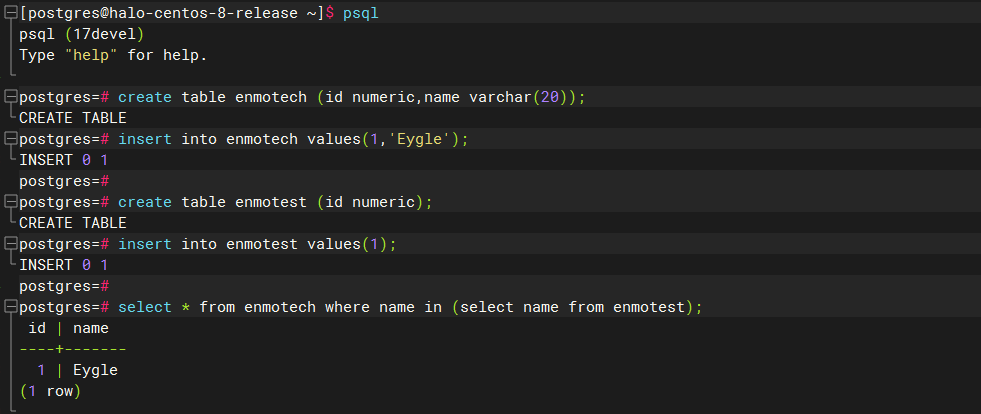
在PostgreSQL的运行结果如下:
可以看到的是,四款数据库都能正常运行此SQL语句,不知道是否如你所想。接下来要问问为什么呢?
三、为什么能正常执行呢?
到动脑子的环节了,盖老师用了10053跟踪事件,解释了Oracle为什么会这样子。
接下来我将通过查看执行计划和阅读PostgreSQL内核源码(17版本)的方式,带大家理解为什么会这样。
3.1、查看执行计划
使用PG的explain查看一下执行计划,执行计划如下所示:
postgres=# explain verbose select * from enmotech where name in (select name from enmotest);
QUERY PLAN
----------------------------------------------------------------------------
Seq Scan on public.enmotech (cost=0.00..9333.62 rows=345 width=90)
Output: enmotech.id, enmotech.name
Filter: (SubPlan 1)
SubPlan 1
-> Seq Scan on public.enmotest (cost=0.00..23.60 rows=1360 width=58)
Output: enmotech.name
(6 rows)可以很显眼的看到存在一个SubPlan,这个SubPlan虽然是顺序扫描表enmotest,但是实际上的输出是表enmotech的name字段。
而这个SubPlan也其实就是处理select name from enmotest 这一部分
所以原本的那整条语句就等价于
select * from enmotech where name in (select enmotech.name from enmotest);运行一下,查看执行结果

可以看到的是结果输出一致。
3.2、阅读源码分析
估计有的对数据库,对SQL生命周期比较了解的朋友看到这其实已经反应过来了。
不过可能还有些朋友还是有些不能理解,或者是自己给自己绕晕了,心想或是在吐槽 数据库你到底在干什么呀!为什么这也能跑!
接下来就带大家深入PostgreSQL内核,了解到底为什么。在阅读内核代码前,为了更好的理解和更加高效的查看内核源码。我们需要对SQL的生命周期,有一点了解。
协议阶段:比如说PostgreSQL的Frontend/Backend Protocol、Oracle的TNS协议、Sybase、Sqlserver的TDS协议等等 解析器阶段:此处以PostgreSQL为例的话 1、词法语法分析阶段: 对输入的字符串进行词法语法分析,检查是否符合词法语法规则的输入,一切顺利的话,最终生成抽象语法树(AST) 2、语义分析阶段: 根据解析树结合系统表的元数据进行语义分析,一切顺利的话,最终生成查询树 3、查询重写阶段:一般是针对视图,此处不讨论 优化器阶段:基于查询树创建一个“最佳”的执行计划 执行器阶段:执行优化器输出的执行计划
结合上述的描述,SQL能正常执行也就意味着这些个阶段都没有任何问题。而对于我们而言,想要了解这样子SQL为什么能跑,也就是要去瞅瞅语义分析阶段,PostgreSQL数据库为什么认为这样子没有问题即可,PostgreSQL数据库内核到底在做什么。
接下来我们快进一下,跳到几个相关函数处,调用堆栈如下:
transformColumnRef(ParseState * pstate, ColumnRef * cref)
transformExprRecurse(ParseState * pstate, Node * expr)
transformExpr(ParseState * pstate, Node * expr, ParseExprKind exprKind)
transformTargetEntry(ParseState * pstate, Node * node, Node * expr, ParseExprKind exprKind, char * colname, _Bool resjunk)
transformTargetList(ParseState * pstate, List * targetlist, ParseExprKind exprKind)
transformSelectStmt(ParseState * pstate, SelectStmt * stmt)
transformStmt(ParseState * pstate, Node * parseTree)
parse_sub_analyze(Node * parseTree, ParseState * parentParseState, CommonTableExpr * parentCTE, _Bool locked_from_parent, _Bool resolve_unknowns)
transformSubLink(ParseState * pstate, SubLink * sublink)
transformExprRecurse(ParseState * pstate, Node * expr)
transformExpr(ParseState * pstate, Node * expr, ParseExprKind exprKind)
transformWhereClause(ParseState * pstate, Node * clause, ParseExprKind exprKind, const char * constructName)
transformSelectStmt(ParseState * pstate, SelectStmt * stmt)
transformStmt(ParseState * pstate, Node * parseTree)
transformOptionalSelectInto(ParseState * pstate, Node * parseTree)
transformTopLevelStmt(ParseState * pstate, RawStmt * parseTree)
parse_analyze_fixedparams(RawStmt * parseTree, const char * sourceText, const Oid * paramTypes, int numParams, QueryEnvironment * queryEnv)
pg_analyze_and_rewrite_fixedparams(RawStmt * parsetree, const char * query_string, const Oid * paramTypes, int numParams, QueryEnvironment * queryEnv)
exec_simple_query(const char * query_string)
PostgresMain(const char * dbname, const char * username)
BackendRun(Port * port)
BackendStartup(Port * port)
ServerLoop()
PostmasterMain(int argc, char ** argv)
main(int argc, char ** argv) 3.2.1、transformColumnRef函数
这个函数其实很长,此处截取一段我们需要注意的地方,
其实这块注释说的很清楚了,就是会去判断想使用的这个列是不是可以用,是不是一个合法的列。
而此时正在进行处理的就是子查询的name字段,由于name字段没有带上限定名,
所以按照以下进行处理,所以我们需要关心colNameToVar函数
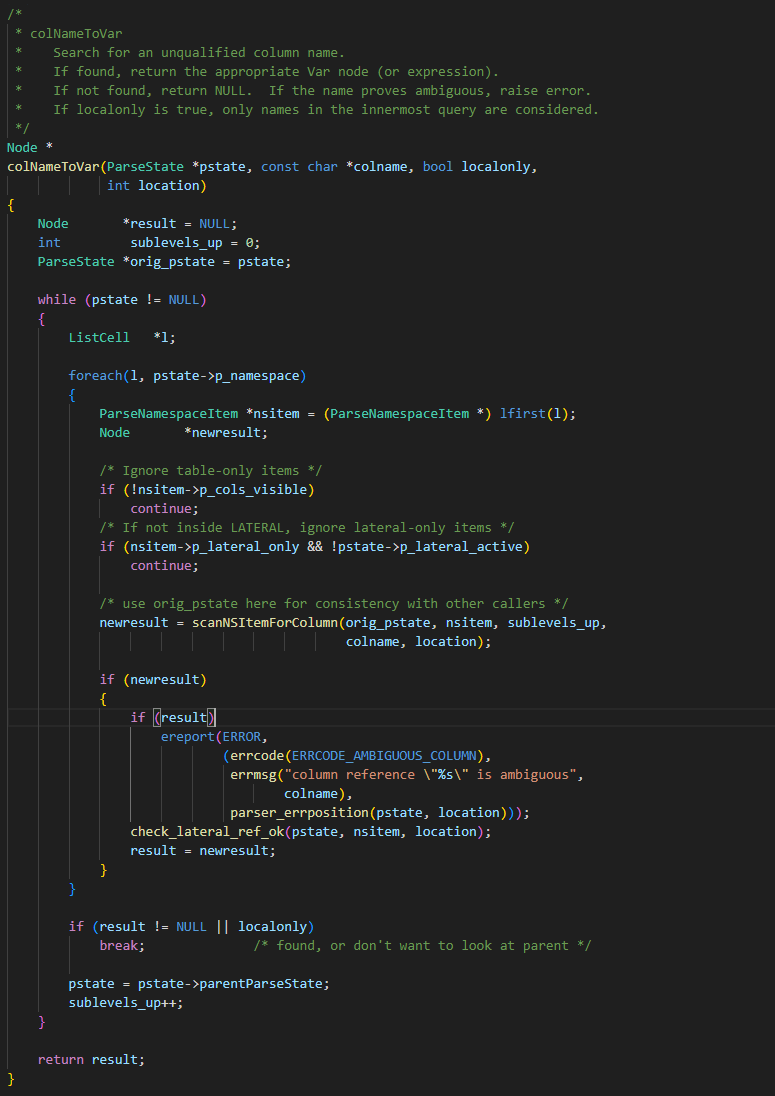
3.2.2、colNameToVar函数
这个函数我们可以看到一些有用的信息,它是一层一层去处理的,如果当前这一层没有成功匹配,那么他就会将自己提升至上一层,再次进行匹配。
那么到底是如何匹配的呢,又是在匹配啥呢?那还得往下扒拉扒拉。
3.2.3、scanRTEForColumn函数
原本应该写scanNSItemForColumn函数,但是scanNSItemForColumn函数内部调用的scanRTEForColumn这个才是关键,
所以此处我们直接看这个scanRTEForColumn函数好了。函数内容如下所示:
/*
* scanRTEForColumn
* Search the column names of a single RTE for the given name.
* If found, return the attnum (possibly negative, for a system column);
* else return InvalidAttrNumber.
* If the name proves ambiguous within this RTE, raise error.
*
* Actually, we only search the names listed in "eref". This can be either
* rte->eref, in which case we are indeed searching all the column names,
* or for a join it can be rte->join_using_alias, in which case we are only
* considering the common column names (which are the first N columns of the
* join, so everything works).
*
* pstate and location are passed only for error-reporting purposes.
*
* Side effect: if fuzzystate is non-NULL, check non-system columns
* for an approximate match and update fuzzystate accordingly.
*
* Note: this is factored out of scanNSItemForColumn because error message
* creation may want to check RTEs that are not in the namespace. To support
* that usage, minimize the number of validity checks performed here. It's
* okay to complain about ambiguous-name cases, though, since if we are
* working to complain about an invalid name, we've already eliminated that.
*/
static int
scanRTEForColumn(ParseState *pstate, RangeTblEntry *rte,
Alias *eref,
const char *colname, int location,
int fuzzy_rte_penalty,
FuzzyAttrMatchState *fuzzystate)
{
int result = InvalidAttrNumber;
int attnum = 0;
ListCell *c;
/*
* Scan the user column names (or aliases) for a match. Complain if
* multiple matches.
*
* Note: eref->colnames may include entries for dropped columns, but those
* will be empty strings that cannot match any legal SQL identifier, so we
* don't bother to test for that case here.
*
* Should this somehow go wrong and we try to access a dropped column,
* we'll still catch it by virtue of the check in scanNSItemForColumn().
* Callers interested in finding match with shortest distance need to
* defend against this directly, though.
*/
foreach(c, eref->colnames)
{
const char *attcolname = strVal(lfirst(c));
attnum++;
if (strcmp(attcolname, colname) == 0)
{
if (result)
ereport(ERROR,
(errcode(ERRCODE_AMBIGUOUS_COLUMN),
errmsg("column reference \"%s\" is ambiguous",
colname),
parser_errposition(pstate, location)));
result = attnum;
}
/* Update fuzzy match state, if provided. */
if (fuzzystate != NULL)
updateFuzzyAttrMatchState(fuzzy_rte_penalty, fuzzystate,
rte, attcolname, colname, attnum);
}
/*
* If we have a unique match, return it. Note that this allows a user
* alias to override a system column name (such as OID) without error.
*/
if (result)
return result;
/*
* If the RTE represents a real relation, consider system column names.
* Composites are only used for pseudo-relations like ON CONFLICT's
* excluded.
*/
if (rte->rtekind == RTE_RELATION &&
rte->relkind != RELKIND_COMPOSITE_TYPE)
{
/* quick check to see if name could be a system column */
attnum = specialAttNum(colname);
if (attnum != InvalidAttrNumber)
{
/* now check to see if column actually is defined */
if (SearchSysCacheExists2(ATTNUM,
ObjectIdGetDatum(rte->relid),
Int16GetDatum(attnum)))
result = attnum;
}
}
return result;
}这个函数其实很好理解,注释也说得蛮清楚的。到底是如何进行匹配的呢?就是优先匹配表中的列,如果匹配上了返回列的下标值。如果没有匹配上,则会考虑匹配隐含的特殊系统列。
这里插一嘴特殊系统列就是ctid、xmin、cmin、xmax、cmax、tableoid 这六个。看完这些个函数,其实逻辑就捋的差不多了。
对于PostgreSQL而言,在语义分析阶段,它对列的处理就是
1、优先匹配当前查询所用到的表中的字段,如果没有匹配上,进行第二步的匹配。
2、匹配隐含的6个系统列ctid、xmin、cmin、xmax、cmax、tableoid
如果还是没有匹配上,如果当前查询有多张表,则再次进行第一步操作,直至当前查询的所以的表均进行匹配过后,
依旧还是没有匹配成功,则进行第三步操作。
3、如果存在上一层,比如说当前自身的子查询,则提升至父查询的层次,再次进行第一、二步,直至最顶层结束。
四、总结
引用一下盖老师的总结:
对于子查询来说,父查询的所有字典信息可见,所以解析转换中,子查询的 NAME 自然就被解析为 ENMOTECH.NAME ,这样比较结果恒为真,就返还了父查询中所有的记录(此时如果父查询表中也不存在这个字段则会抛出异常):
这个题目的真正警示在于,如果开发人员凑巧写错了条件,而这个SQL的执行不会出现异常,只是结果不符合预期,我们需要提前识别这个误操作。
所以到此你应该了解了为什么这个SQL能运行,还有这个name字段在PostgreSQL中是怎么被处理掉的。 所以最后在思考一下,怎么样写出更好更如你心意的SQL语句。
五、声明
若文中存在错误或不当之处,敬请指出,以便我进行修正和完善。希望这篇文章能够帮助到各位。
文章转载请联系,谢谢合作。
