




数据特征 同样也是医院面临的问题
(1)数据异构
多平台,多种接口,数据类型没有一个标准,只能是点对点的对接大量数据,内容冗杂,过程繁复,速度缓慢。
(2) 主题分散性
就诊信息分布在不同的平台上,不能够形成以患者为中心的所有电子化就诊信息集成,不能提供完整、全面、准确、及时的患者临床信息。
(3)数据量大
在大数据背景下,行业应用的数据量通常都以亿级别计算,存储通常在TB/PB级别甚至更多。
解决问题 剖析医院数据使用困境
(1) 实现以患者为中心的医疗信息采集、清洗、存储、加载和决策辅助。构建医疗信息咨询、检索、展示和医疗决策支持平台。
(2) 基于数据中心的全量数据,构建应用主题库,为医院临床辅助、精细化运营管理、科研管理提供强有力的数据支撑。
(3) 实现亿级别数据量查询、统计、分析秒处理展示。
产品介绍
产品概述
ETL(Extraction-Transformation-Loading)是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据, ETL是BI(商业智能)项目重要的一个环节。
产品框架
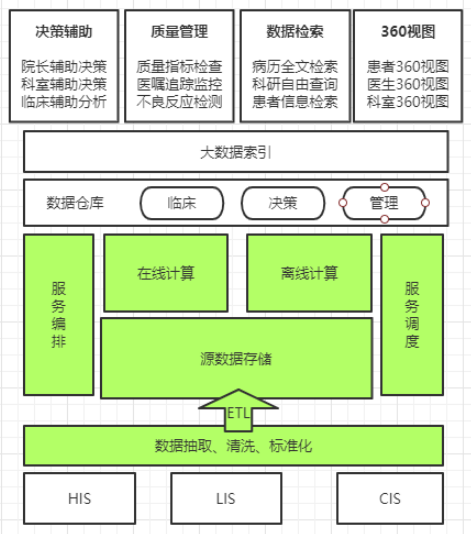
数据集中:全量数据、数据清洗、数据适配、数据存储
数据标准化:主数据、词汇字典、数据映射
实施服务:多量数据在线、多种接口形式、快速查询、降低业务负载
安全审计:数据审计、数据盘点、权限认证、隐私处理
运维监控:群集监控、故障排除、扩容扩展、应急处理
(1)全量历史结构化数据采集
通过图形化的数据采集核对工具,对历史数据进行采集、清洗和存储。同时支持监测采集数据和原系统数据对比,保证数据条目的一致性、时效性。
(2)结构化流数据清洗治理
数据质量治理、数据清洗、数据关系串联、数据重组
待图
(3)结构化数据实时接入
采用Flume技术,完成医院实时数据的转换接入
待图
(3)非结构化数据实时接入
采用Flume技术,完成医院实时数据的转换接入
待图
(5)数据标准体系
集中管理主数据、数据元标准化定义、自动同步基础数据
(6)数据安全体系
数据安全审计、数据盘点核对、数据脱敏处理、集群运维监控
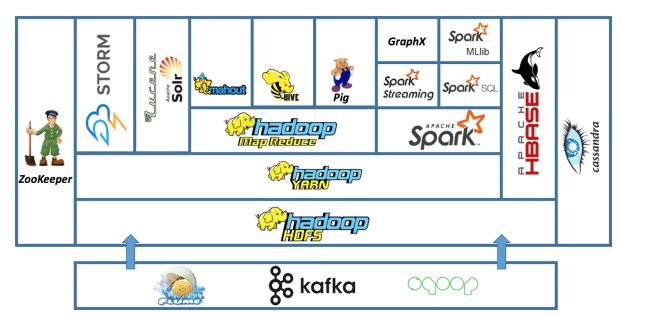
(7)大数据生态系统
Hadoop生态系统中集成了大量的工具和组件来满足不同计算和存储需求,比如HDFS分布式文件系统、HBase列式数据库、Hive数据仓库、Kafka服务编排、MapReduce服务调度、impala类SQL数据仓库等,可以方便地进行数据存储和分析计算
(8)对外开放数据服务
通过丰富的对外服务方式,提供实时的信息查询,降低业务系统压力,保证数据全生命周期的完整性和关联性,支持第三方智能化应用等嫁接服务
产品优势(图)
(1)多种数据源
支持多种数据源,一键接入,无需繁琐配置。
(2)零代码
简单易用的用户体验,零代码建立传输任务,降低企业用户使用门槛。
(3)大规模开发
支持大规模数据集成,(待修改)。
(4)实时融合
实时的数据融合与集成,不让延迟成为瓶颈,保证数据的时效性。
(5)开箱即用
简单快速的安装流程,高效部署生产环境,即装即用。
(6)错误队列预警
完善的纠错机制与系统状态监控,迅速预警数据问题。
(7)多种目的地
支持多种数据目的地,轻松同步,高效利用数据。
(8)全程质量管控
高质量体系保障数据传输的安全性与准确性,真正实现数据无忧。
(9)极速处理
对数据仓库大规模数据查询的优化,数据处理时,可以以极快的速度处理存储在HDFS中的数据。
技术优势(图)
(1)具体实时计算分析能力
(2)通过并行任务调度提高计算速度
(3)高性价比,使用低成本存储和服务器构建
(4)高吞吐量,支持高吞吐量访问,消除访问瓶颈
(5)高扩展性,无需停机动态扩容,同时支持横向扩展
(6)高可靠性,支持数据自动检测并保存多份副本,支持任务重新分配
(7)高效性,各数据节点支持动态平衡,保证高速的处理速度
