




大型语言模型(LLM)的革命已经将向量数据库从鲜为人知的搜索技术转变为人工智能成功所必需的产品。但是,你应该寻找哪些向量数据库的特性,以及哪些供应商正在创新?Forrester的分析师最近深入研究了这一领域,并在《2024年第二季度向量数据库格局》报告中提供了答案。
向量数据库的兴起
大型语言模型(LLM)的革命将向量数据库从鲜为人知的搜索技术转变为AI成功不可或缺的产品。向量数据库旨在管理和处理一种称为向量嵌入的数据类型,这是一种对单词、文档、图像甚至声音的数值表示。向量数据库在多维空间中索引和存储这些嵌入,使用户或应用程序能够检索这些嵌入及其相似的其它嵌入。这种相似性搜索功能比简单的关键词匹配提供了更好的搜索结果,促成了所谓的“AI搜索引擎”的创建。
ChatGPT与向量数据库
2022年底,ChatGPT推出LLM后,向量数据库迅速发现了新的用途。通过将一组源文档作为向量数据库中的嵌入存储,并在运行时调用数据库通过相似性搜索提供这些文档的信息,作为提示工程或检索增强生成(RAG)过程的一部分,GenAI用户发现他们可以显著提高由ChatGPT等LLM支持的聊天机器人、副驾驶和其他AI交互形式生成的响应质量。
向量数据库市场的增长
在ChatGPT之前,只有少数几个“原生”向量数据库存在,如Pinecone、Milvus和Zilliz。但几乎一夜之间,许多现有的数据库供应商也调整了他们的产品,使其能够存储、索引和处理向量数据,包括Elastic、DataStax、Couchbase、MongoDB,甚至是Teradata。对于已经是多模态的NoSQL和关系数据库来说,添加向量数据类型是理所当然的。
Forrester的分析
随着向量数据库市场的爆炸性增长,也给用户在选择采用向量数据库的最佳方法时带来了一些困惑。Forrester,这家位于马萨诸塞州剑桥的长期IT分析集团,在“2024年第二季度向量数据库格局”报告中,由分析师Noel Yuhanna及其同事深入研究了不断增长的向量数据库市场,并从24家供应商那里剖析了向量数据库的能力。
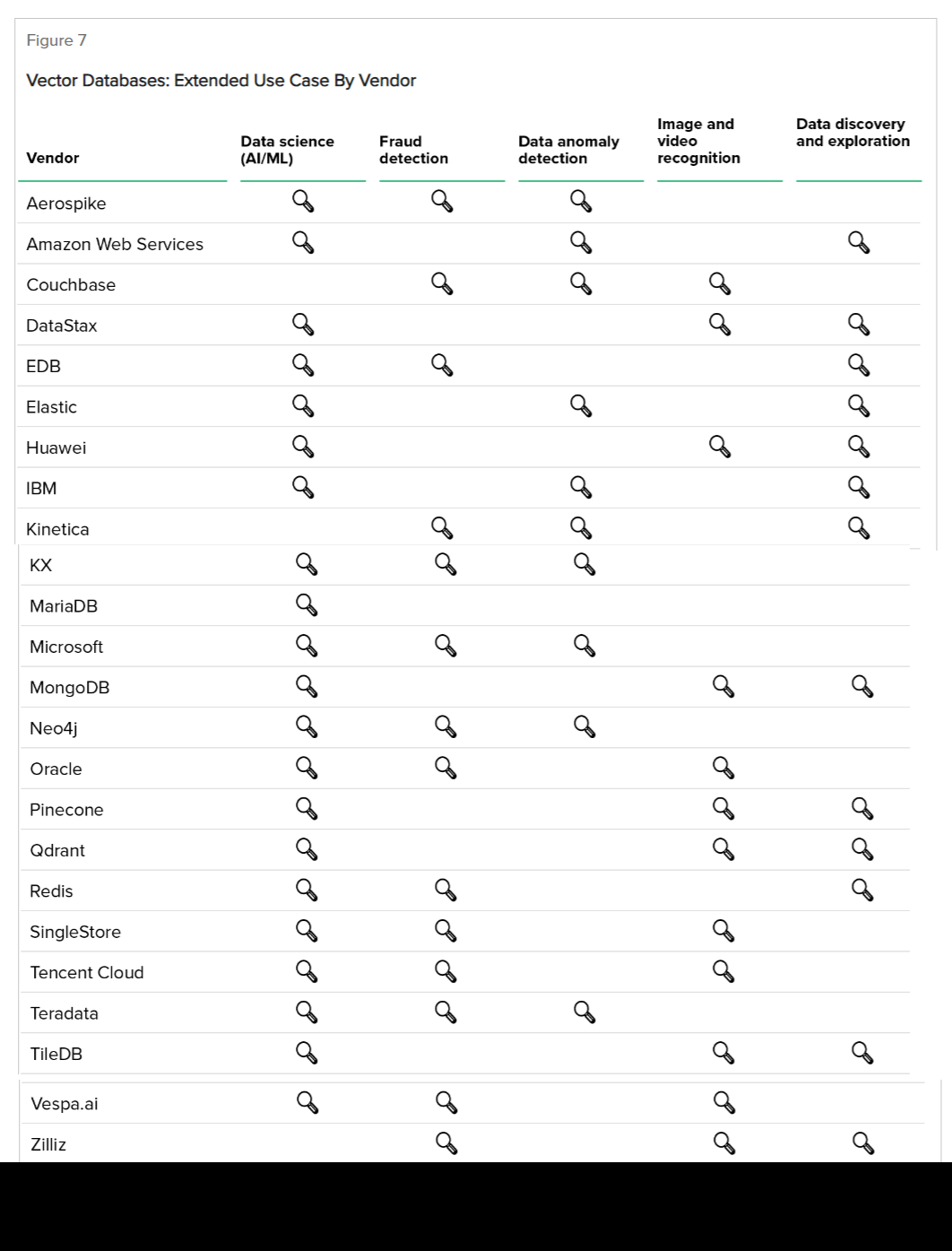
向量数据库的分类
Forrester将向量数据库市场分为两个主要部分:原生向量数据库和多模态向量数据库。Forrester表示,两者之间的主要区别在于原生向量数据库的更大可扩展性,尤其是在处理大量向量时。与此同时,多模态向量数据库的主要优势在于它可以存储其他类型的数据,可能消除了需要两个或更多独立数据库的需求。
向量数据库的挑战
Forrester指出,向量数据库的规模挑战尚未完全解决,高端市场“仍在进行中”。支持数十亿数据点(向量)时,高端规模和性能仍需要相当的努力。
向量数据库的新兴用途
Forrester没有根据它们处理标准向量数据库任务的能力对向量数据库进行排名(这可能是即将到来的Forrester Wave的主题)。但它确实研究了哪些数据库正在为向量数据库的一些新兴用例定位,这对观察者和客户来说是有用的信息。
向量数据库的未来趋势
向量数据库的预期能力正在变化。核心功能,如向量存储、索引和处理,正在被更先进的功能增强,包括增强的安全措施、优化的处理能力以及与多样化的向量嵌入转换器和数据流引擎的无缝集成。Forrester还指出,云数据平台,包括数据织物和数据湖房,也在采用向量能力,这可能会进一步颠覆向量数据库市场。
结语
Forrester的报告强调了向全面数据管理解决方案的转变,这些解决方案无缝集成了向量功能,可能会重塑专业向量数据库的格局。随着市场的不断发展和变化,观察者和客户应密切关注这些动态。
