




Question: 25
A master-slave replication setup has the slave showing this error:
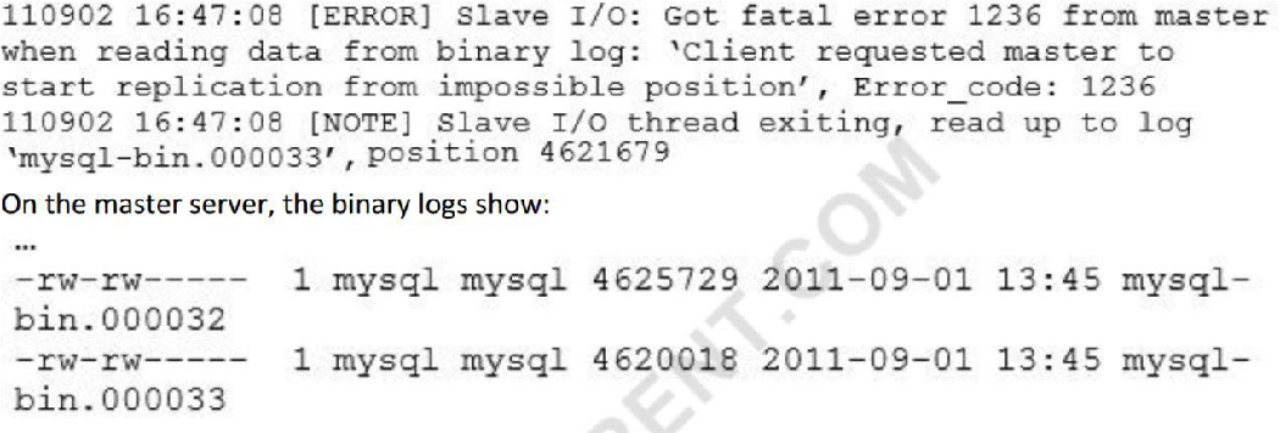
What could explain this error? (Choose two.)
A. binlog_cache_size=1024 is too small and transactions are lost.
B. binlog_format=STATEMENT and a non-deterministic query was executed.
C. enforce_gtid_consistency=ON and consistency is broken between the master and the slave.
D. The sync_relay_log=1000 setting on the slave is too small.
E. sync_binlog=0 and the master server crashed.
答案:CE
解析:主从同步场景中,总共有三个线程,主节点上一个binlog dump线程,从节点上io线程和sql线程;
其中,master上的binlog dump线程负责接受slave端io线程发送的消息(比如读哪个binglog文件的哪个位置),然后读取binlog的内容并发送给slave端的io线程,而从节点的io线程负责接收binlog dump线程发送的内容并且在本地转存为relay log。如题所示报错信息是读取binlog时报错,客户端(slave io线程)在请求的位置在master的binlog里是不可能的,意味着master的binlog可能遭到损坏、或者主从一致性被破坏。
A选项,binlog_cache_size参数过小不会导致事务丢失,当客户端线程开始一个事务时,会初始化一个binlog_cache用于缓存事务中的增删改,内存不够用时会使用临时文件存储,在事务commit前,需要先把binlog_cache中的事务写到binlog中后再commit。
B选项,binlog_format=STATEMEN且执行了一些非确定性的语句,如update xx set update_time=now()此类,可能会造成主从不一致,但不会造成master的binlog损坏。
C选项,enforce_gtid_consistency=on,表示强制进行gtid一致性检测,在gtid进行主从复制时,可以阻止可能某些导致复制失败的语句的执行;比如create table ... select或在一个事务中同时更新事务表与非事务表。比如一个事务在master执行时事一个事务,产生一个gtid,而在slave上执行时,由于某些原因导致产生了两个gtid,此时主从的一致性就被破坏,io线程下一次请求读取master上的binlog时,master就无法找到指定的事务id。
D选项,sync_relay_log=1000,表示slave节点上relay log落盘策略是累积到1000个事务进行一次sync。slave节点发生意外故障时,可能会有最多1000个事务在内存中,没有sync到磁盘,如果slave节点的主机没有重启,不影响relay log;如果主机意外重启,可能会丢失最多1000个事务的relay log;但不会影响master的binlog
E选项,syncz_binlog=0,表示mysql 程序不会主动进行sync,将binlog持久化道磁盘而是依赖操作系统时不时的flush。如果master节点意外故障,可能会导致内存中的binlog没有flush到磁盘,从而导致磁盘binlog文件不完整。
