




问题描述
近期,在使用notebook
的过程中,使用spark
的时候,出现了如下一个必现的问题:
通过spark = SparkSession.builder.config(conf=sparkConf).enableHiveSupport().getOrCreate()
方式启动spark
,第一次启动spark
,启动一半还未成功时,手动将其中止了,然后按照上述方式,再次启动spark
的时候,必报如下错误,完整的日志信息见文末。
错误说的很明确,JVM
已经有sparkcontext
了,不允许再次创建,同时,也说了,可以通过设置 spark.driver.allowMultipleContexts = true
,开启多sparkcontext
Py4JJavaError: An error occurred while calling None.org.apache.spark.api.java.JavaSparkContext.
: org.apache.spark.SparkException: Only one SparkContext may be running in this JVM (see SPARK-2243).
To ignore this error, set spark.driver.allowMultipleContexts = true. The currently running SparkContext was created at:
简单分析
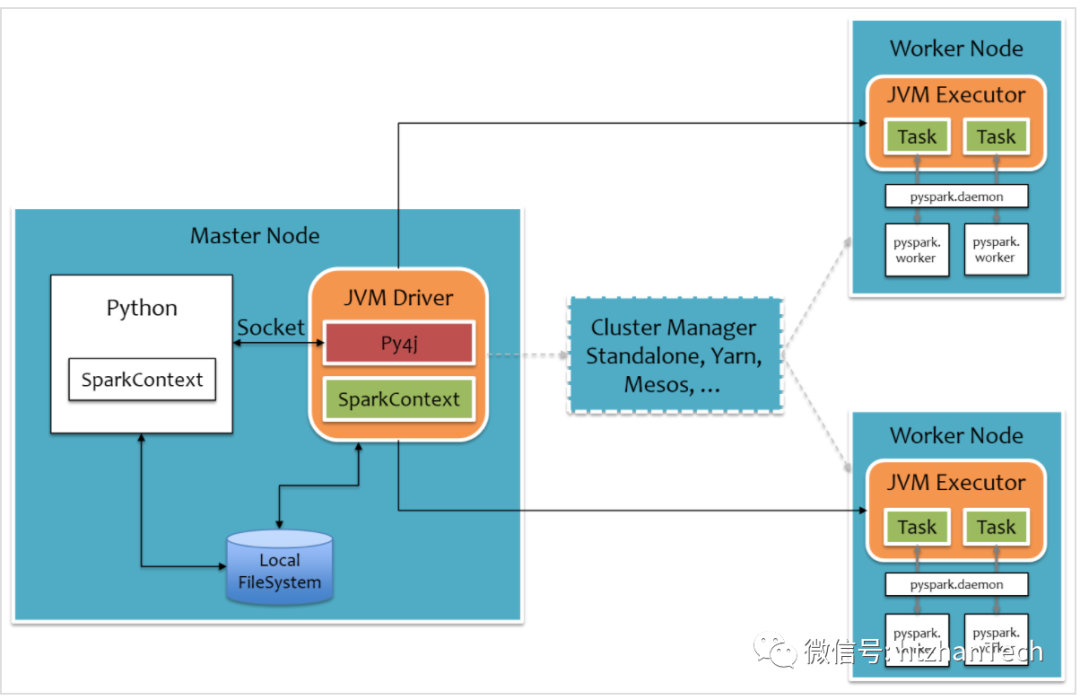
通过查看日志,翻阅pyspark
的代码和其架构原理,发现导致此问题的原因:
是因为pyspark
已经将创建sparkcontext
的命名,通过py4j
发送到JVM Drive
了,在JVM Drive
层面,通过反射动态的初始化sparkContext
对象实例,
然后,创建spark
的时候,执行到assertNoOtherContextIsRunning
,因为当前已经有sparkContext
在执行,报错抛出异常。
虽然代码的执行被中止,但是相关的命令已经发送到py4j server
端,所以JVM
中还会继续完成sparkContext
的创建工作。
而且python
进程中的sparkContext
实例和JVM Drive
中的sparkContext
实例是相呼应的,在pyspark
中的SparkContext
类中,有一系列的方法控制JVM
中sparkContext
的相关操作。
python
代码被中断后,pyspark
的sparkContext
未创建成功,所以,JVM
中的sparkContext
将失去束缚,无法直接被操作了。
所以,再次执行getorcreate()
创建spark
的时候,发现JVM
已经有sparkContext
, 就报错了。
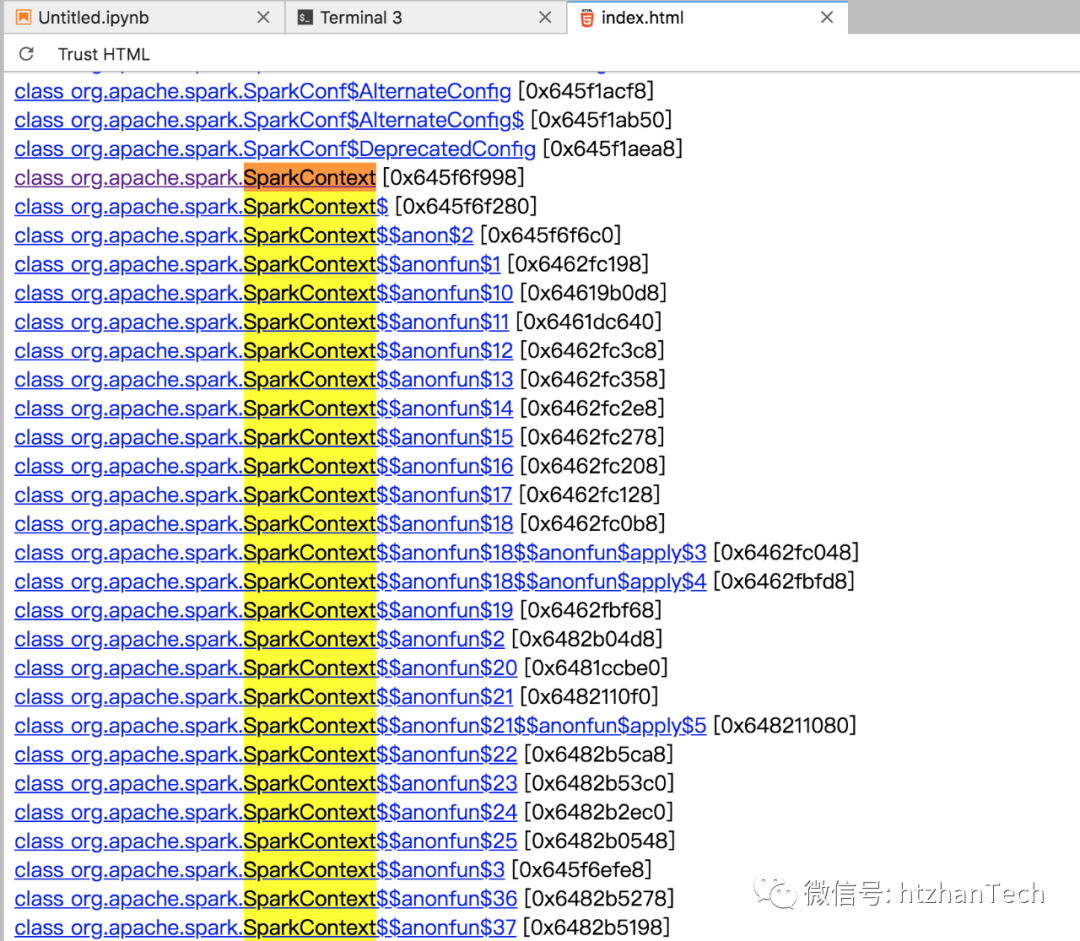
通过jps
查看当前系统的java
进程,然后jmap -dump:live,format=b,file=a.log <pid>
下载了当前Java
进程里存活对象的堆栈信息,
然后简单的通过jhat
简单分析堆栈文件,jhat a.log
,发现确实有sparkcontext
对象存在于jvm
中。
可能的解决思路
想办法复用
JVM Driver
的sparkContext将之前残留的
sparkContext
,通过某种方式清理掉设置
allowMultipleContext
开启多sparkContext用户手册告知用户,出现此错误时,点击右上角按钮,
restart
当前的kernel
复用JVM Driver的sparkcontext
显然,如果能够做到,这是最合理,最佳的实践方式。虽然,我们使用pyspark
的 getorcreate()
方法,现在也有sparkcontext
,
直观看,貌似也是应该复用,直接拿当前的sparkContext
对象,但是这个getorcreate()
方法,是pyspark
层面的,也就是Ipyhton
内核这个进程内的,如果当前已经有创建好的sparkcontext
,就get
, 否则就create
。
所以,此情形下,Ipython
进程给JVM Driver
发送的命令其实都是,创建sparkcontext
示例对象,代码如下
# Create the Java SparkContext through Py4J
self._jsc = jsc or self._initialize_context(self._conf._jconf)
def _initialize_context(self, jconf):
"""
Initialize SparkContext in function to allow subclass specific initialization
"""
return self._jvm.JavaSparkContext(jconf)
然后,查看spark
的scala
源码,在sparkcontext
的伴生对象中,有getOrCreate()
方法,
如果,将pyspark
直接实例化sparkcontext
, 改为调用getorcreate()
,理论上,貌似可行,但是需要改造pyspark
源码,成本较高,方式也不合理,
所以,这条路,貌似走不通。
清理之前的sparkContext
在pyspark
的代码,其本身也采取的类似的方式,创建失败了,会完成各类清理工作,
在SparkContext
的__init__()
方法中,相关代码如下:
try:
self._do_init(master, appName, sparkHome, pyFiles, environment, batchSize, serializer,
conf, jsc, profiler_cls)
except:
# If an error occurs, clean up in order to allow future SparkContext creation:
self.stop()
raise
现在问题就是,stop()
方法是SparkContext
中的实例方法,创建spark
过程中止,当前的sparkContext
实例未初始化完成,自然无法在代码中,显式的通过sc
实例调用这个这个stop
方法。
所以,貌似这个方法也无法行得通。
开启allowMultipleContexts
既然当前场景中,暂时无法简单的做到JVM
保持一个sparkcontext
,貌似,只能采取开启allowMultipleContexts
。
按照要求,spark
的conf
中,设置spark.driver.allowMultipleContexts = true
, 发现确实创建成功,不再报错,applicationId = application_1585648660955_513512

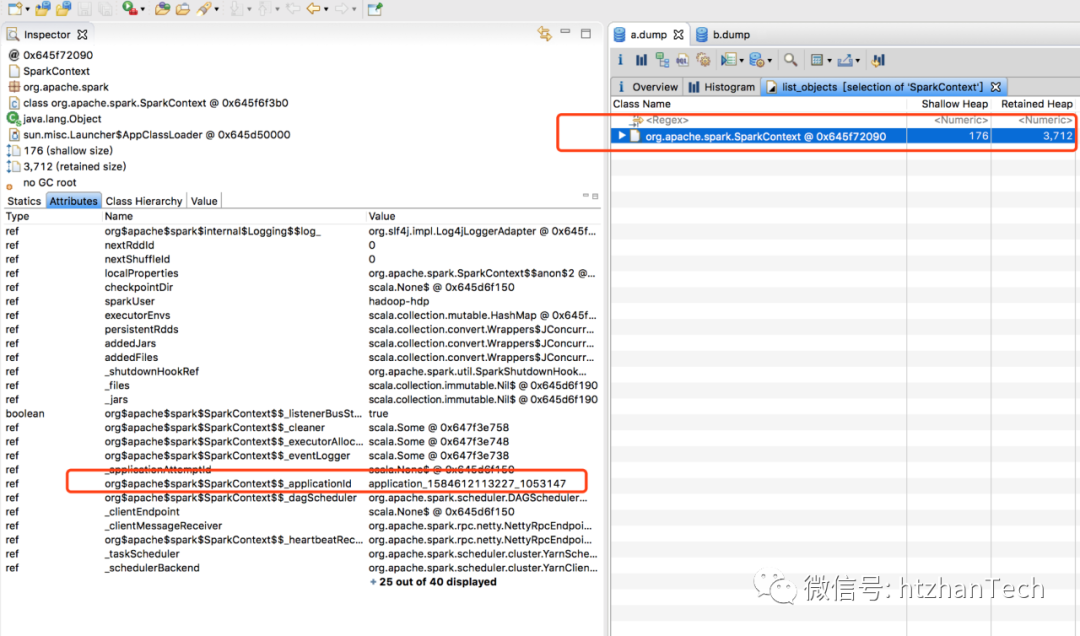
通过,使用eclipse MAT
工具分析中止后的Java
堆dump
文件,和 再次创建spark
后的Java
堆dump
文件,发现,再次启动后,jvm
有两个sparkcontext
,一个是第一次中止的,一次是新创建的。暂时也不清楚,JVM
中两个sparkContext
是否会埋下什么坑。
中止后,JVM
中SparkContext
类的对象情况
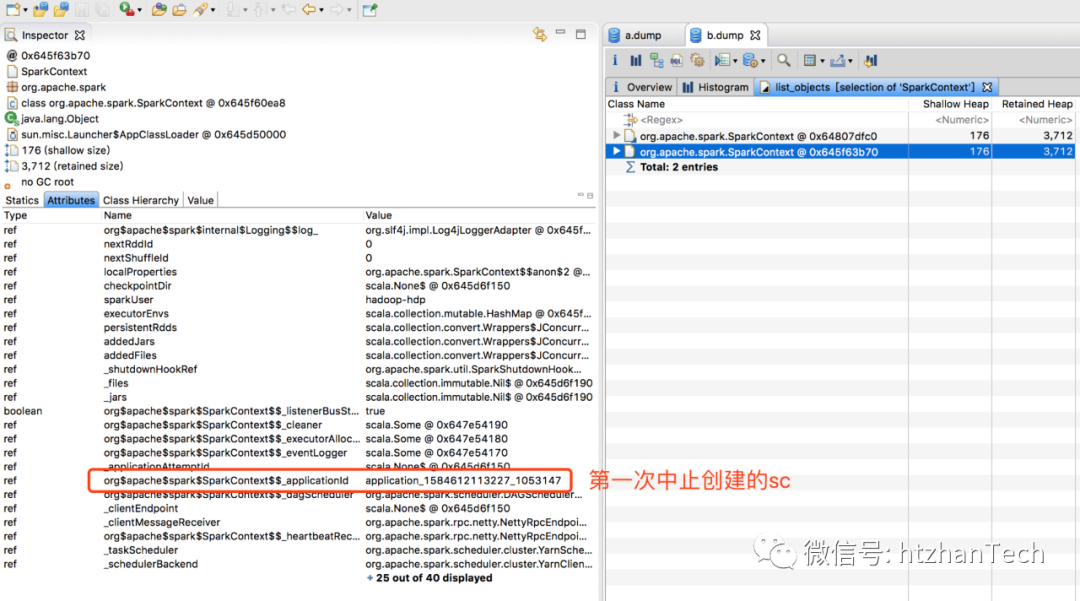
再次创建spark
后的Java
堆中,sparkContext
类的对象情况

补充
完整报错信息
---------------------------------------------------------------------------
Py4JJavaError Traceback (most recent call last)
<ipython-input-2-af0aed49fd56> in <module>
----> 1 get_ipython().run_line_magic('spark', '--s3key=keys/appId/hadoop-hdp/zhanhaitao/facf3179-a7c8-46ad-a998-f43dc9c30472')
/opt/conda/envs/notebook/lib/python3.6/site-packages/IPython/core/interactiveshell.py in run_line_magic(self, magic_name, line, _stack_depth)
2305 kwargs['local_ns'] = sys._getframe(stack_depth).f_locals
2306 with self.builtin_trap:
-> 2307 result = fn(*args, **kwargs)
2308 return result
2309
</opt/conda/envs/notebook/lib/python3.6/site-packages/decorator.py:decorator-gen-127> in spark(self, line, cell)
/opt/conda/envs/notebook/lib/python3.6/site-packages/IPython/core/magic.py in <lambda>(f, *a, **k)
185 # but it's overkill for just that one bit of state.
186 def magic_deco(arg):
--> 187 call = lambda f, *a, **k: f(*a, **k)
188
189 if callable(arg):
/opt/conda/envs/notebook/lib/python3.6/site-packages/sparkmagics/sparkmagics.py in spark(self, line, cell)
154 print(id(builder))
155 print(id(builder._lock))
--> 156 spark = builder.getOrCreate()
157 sc = spark.sparkContext
158 applicationId = sc.applicationId
/opt/meituan/spark-2.2/python/pyspark/sql/session.py in getOrCreate(self)
167 for key, value in self._options.items():
168 sparkConf.set(key, value)
--> 169 sc = SparkContext.getOrCreate(sparkConf)
170 # This SparkContext may be an existing one.
171 for key, value in self._options.items():
/opt/meituan/spark-2.2/python/pyspark/context.py in getOrCreate(cls, conf)
332 with SparkContext._lock:
333 if SparkContext._active_spark_context is None:
--> 334 SparkContext(conf=conf or SparkConf())
335 return SparkContext._active_spark_context
336
/opt/meituan/spark-2.2/python/pyspark/context.py in __init__(self, master, appName, sparkHome, pyFiles, environment, batchSize, serializer, conf, gateway, jsc, profiler_cls)
116 try:
117 self._do_init(master, appName, sparkHome, pyFiles, environment, batchSize, serializer,
--> 118 conf, jsc, profiler_cls)
119 except:
120 # If an error occurs, clean up in order to allow future SparkContext creation:
/opt/meituan/spark-2.2/python/pyspark/context.py in _do_init(self, master, appName, sparkHome, pyFiles, environment, batchSize, serializer, conf, jsc, profiler_cls)
178
179 # Create the Java SparkContext through Py4J
--> 180 self._jsc = jsc or self._initialize_context(self._conf._jconf)
181 # Reset the SparkConf to the one actually used by the SparkContext in JVM.
182 self._conf = SparkConf(_jconf=self._jsc.sc().conf())
/opt/meituan/spark-2.2/python/pyspark/context.py in _initialize_context(self, jconf)
271 Initialize SparkContext in function to allow subclass specific initialization
272 """
--> 273 return self._jvm.JavaSparkContext(jconf)
274
275 @classmethod
/opt/meituan/spark-2.2/python/lib/py4j-0.10.4-src.zip/py4j/java_gateway.py in __call__(self, *args)
1399 answer = self._gateway_client.send_command(command)
1400 return_value = get_return_value(
-> 1401 answer, self._gateway_client, None, self._fqn)
1402
1403 for temp_arg in temp_args:
/opt/meituan/spark-2.2/python/lib/py4j-0.10.4-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name)
317 raise Py4JJavaError(
318 "An error occurred while calling {0}{1}{2}.\n".
--> 319 format(target_id, ".", name), value)
320 else:
321 raise Py4JError(
Py4JJavaError: An error occurred while calling None.org.apache.spark.api.java.JavaSparkContext.
: org.apache.spark.SparkException: Only one SparkContext may be running in this JVM (see SPARK-2243). To ignore this error, set spark.driver.allowMultipleContexts = true. The currently running SparkContext was created at:
org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:58)
sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
java.lang.reflect.Constructor.newInstance(Constructor.java:423)
py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:247)
py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
py4j.Gateway.invoke(Gateway.java:236)
py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:80)
py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:69)
py4j.GatewayConnection.run(GatewayConnection.java:214)
java.lang.Thread.run(Thread.java:748)
at org.apache.spark.SparkContext$$anonfun$assertNoOtherContextIsRunning$2.apply(SparkContext.scala:2558)
at org.apache.spark.SparkContext$$anonfun$assertNoOtherContextIsRunning$2.apply(SparkContext.scala:2554)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.SparkContext$.assertNoOtherContextIsRunning(SparkContext.scala:2554)
at org.apache.spark.SparkContext$.setActiveContext(SparkContext.scala:2656)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:2462)
at org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:58)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:247)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:236)
at py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:80)
at py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:69)
at py4j.GatewayConnection.run(GatewayConnection.java:214)
at java.lang.Thread.run(Thread.java:748)
