




背景情况介绍
为了满足实时数据分析的需求,在离线数据中台的基础上,建立的一个基于MPP大数据集群的实时数据仓库。离线数据中台通过hive提供SQL查询功能,但是百亿级大表查询性能满足不了要求。为此,需要将离线中台几十张表实时同步到实时数据仓库,其中有一张将近100亿的业务表进行全量和增量数据同步过程中踩了不少坑,但是经过各方大佬的不懈努力,最终实现数据实时同步的目标。在整个过程中,有几个比较容易踩坑的经验拿出来跟大家分享。

专有名词简介
概念1:数据仓库 TCHouse-P兼容 PostgreSQL 开源数据仓库,是一种基于 MPP(大规模并行处理)架构的数仓服务。
概念2:大数据处理套件TBDS基于云原生技术和泛 Hadoop 生态开源技术对外提供的可靠、安全、易用的大数据处理平台。根据不同数据处理需求选择合适的大数据存算分析组件包括 Hive、Spark、HBase、Flink、presto、Iceberg、Alluxio 等,以快速构建企业级数据湖、数据仓库。
概念3:Sqoop是一个用来在Hadoop和关系数据库之间高效传输数据的工具。
主键及索引对批量插入的影响
实施过程:
1、采用TBDS大数据组件读取HIVE数据,并插入TCHouse数据库,每秒写入速度在6000~7000条。
2、采用Sqoop工具读取HIVE数据,写入性能提升几倍,但是随着目标表的数据量越来越大,插入速度也越来越慢。
3、按照时间的维度将源表拆分成多个目标表并成功迁移,每个目标表数据量在10~20亿之间。但是在TCHouse数据库将多个小表的数据归集表一张表的过程中,发现2亿的记录跑了4小时还跑不完。
4、在TCHouse数据库上使用COPY命令进行数据归集,但是性能依旧满足不了要求。
问题分析:
主键是关系数据库中的一个重要概念,用于唯一标识表中的每一行数据。主键的唯一性保证了数据的完整性,防止重复数据的插入。批量插入数据会对每条数据进行唯一性校验,导致性能下降。同时该表还有8个索引,也会导致插入性能严重下降。
优化经验:目标库创建表时,不建约束,不建索引。
分布键选择与设计
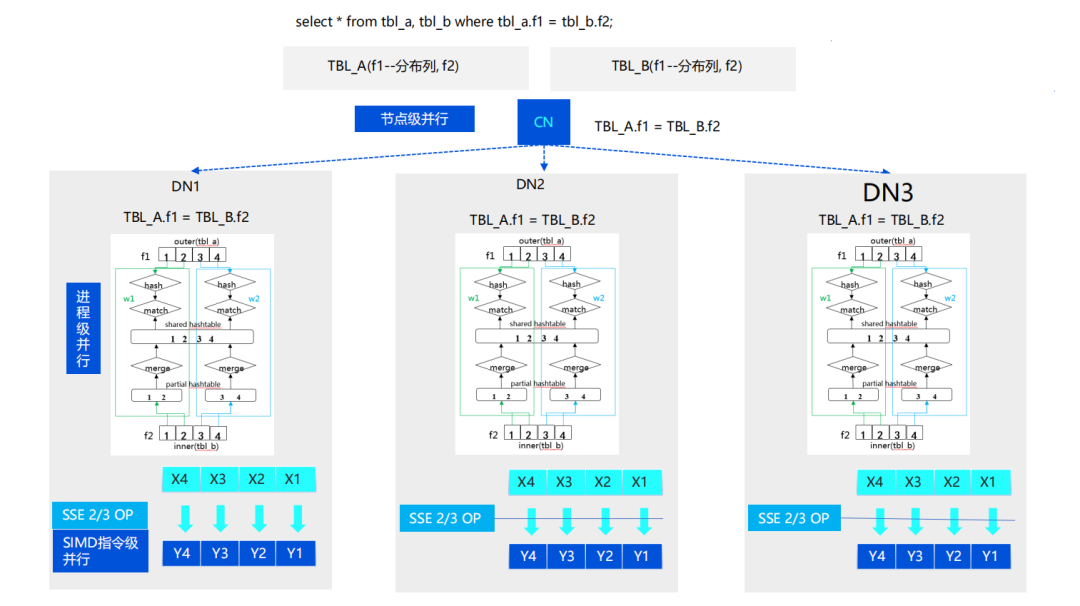
分布键:在分布式数据库系统中,合适的分布键(Distribute By: SHARD)可以帮助数据均匀分布在所有计算节点上,显著提高计算和查询性能。
分布键设置经验总结:
1、当表定义了主键,同时没有指定分布键时,Greenplum使用主键作为分布键。由于建表暂时不指定主键,因此要先明确分布键。
2、只要有可能,应该只使用单列作为分布键。如果单列无法实现均匀分布,最多使用两列的分布键。再多的分布列通常不会产生更均匀的分布,并且在散列过程中需求额外的时间。
4、分布键列数据应包含唯一值或具有非常高的基数(不同值个数与总行数的比值)。
6、应该尽量避免使用日期或时间列作为分布键,因为一般不会使用这种列来与其他表列进行关联查询。
7、不要用分区字段作为分布键。
8、为改善大表关键性能,应该考虑将大表之间的关联列作为分布键,关联列还必须是相同的数据类型。如果关联列数据没有分布在同一段中,则其中一个表所需的行要动态重新分布到其他段。
查看分布键的方法
方法一:登录CN计算节点,设置环境变量,使用psql命令登录数据库\c 库名库名=# \d+ ${schema}.${table}表结构最后会显示分布键信息Distribute By: SHARD(bkkp_sn)Location Nodes: ALL DATANODES方法二:SQL查询分布键select pg_namespace.nspname, pg_class.relname,(select array_to_string(array(select pg_attribute.attname from pg_attributewhere pg_attribute.attrelid = pgxc_class.pcrelidand pg_attribute.attnum in (select unnest(pgxc_class.discolnums))),',')) as shardkeyfrom pgxc_class, pg_namespace, pg_classwhere pgxc_class.pcrelid = pg_class.oidand pg_namespace.oid = pg_class.relnamespaceand pgxc_class.pclocatortype = 'S'and pg_class.relkind in ('r','p')and nspname = '${schema}'and relname = '${table}'ORDER BY pg_namespace.nspname, pg_class.relname;
分区表设计与查询
分区表:表分区可以将一个大表按照某个或多个属性的值划分为多个小表。当数据量非常大时,方便维护数据;最后就是利用分区消除查询时,不用扫描整张表,从而提高查询性能。
分片键与分区键的区别:分布键用于实现数据在多个分片均匀分布,分区键是用于划分数据范围。
查看分区键的方法
postgres=# \c 库名库名=# \d+ ${schema}.${table}表结构最后会显示分布键信息Partition key: RANGE (setl_time)Indexes:索引1列表索引2列表Partitions: ${schema}.${table}_prt_1 FOR VALUES FROM ('2019-01-01 00:00:00') TO ('2019-02-01 00:00:00'),${schema}.${table}_prt_2 FOR VALUES FROM ('2019-20-01 00:00:00') TO ('2019-03-01 00:00:00'),
总结
整个迁移同步实施工作做完之后,我认为以下几点经验可供借鉴:
1、一个好的分片键可以让数据均匀分散到每个DN节点,充分利用每台服务器资源,提升写入效率;
2、一个好的分区键可以让每个DN节点上的数据拆分成更小的表,更好维护数据,也更快速查询;
3、把主键与索引放到最后来创建,对整个全量同步效率带来很大的提升。
4、选择一个好的ETL同步工具,可以避免大量的调试、测试验证和返工工作。
参考资料:
https://mp.weixin.qq.com/s/eHosVyuCj_8PkODR_tYuNA
https://mp.weixin.qq.com/s/PZgpca3-35sCZB_NAptLWQ
https://mp.weixin.qq.com/s/chua8DCV7X4LDLonzRP0qg
https://mp.weixin.qq.com/s/N2RuWOFEWfJxv7NJbtqOiQ
https://mp.weixin.qq.com/s/YTKrM9eVwRecE-CBJlM1OQ
https://cloud.tencent.com/document/product/878
https://cloud.tencent.com/document/product/273
https://cloud.tencent.com/product/tbase
王雪松《Greenplum构建实时数据仓库实践》
https://www.yun88.com/product/2716.html
链接: https://pan.baidu.com/s/1hwKH8EE5wX1Pe0uQmoxiyA 提取码: j7tk
近期热门文章:
全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
欢迎关注公众号!
