




随着数据量爆炸性的增长,数据库类产品创新层出不穷,为了更好的做技术选型参考,笔者对国内主流8种数据库进行了TPC-H(数据分析)性能评测,被测试的数据库包括:MySQL、PostgreSQL、Oracle、达梦、ClickHouse、Doris、Starrocks、DuckDB。

测试方法
TPC-H:国际数据库标准测试组织TPC推出的面向决策支持系统的数据库方法,主要用于数据分析场景性能评测,TPC-H总共需要运行22条数据分析型SQL。本次测试属于TPC-H自由测试,仅测试查询SQL,没有执行更新和事务。
数据集:TPC-H v3.0.1测试数据集,200GB(非报告标准size)。
计时方法:统计每条SQL执行时间,全部累加。设置SQL最长执行时间为300秒(5分钟),如果执行出错或者超时,则本条SQL时间按600秒计算。
测试硬件
为了公平起见,本次TPC-H测试使用了完全相同的硬件,所有产品都是单机部署,重点是测试各个产品的单机处理能力。
处理器:16核2.7 GHz主频的Intel (®) Xeon (®) 可扩展处理器(Ice Lake ),
内存:128GB
硬盘:1块本地Nvme SSD,空间894GB
操作系统:CentOS7.9

测试结论
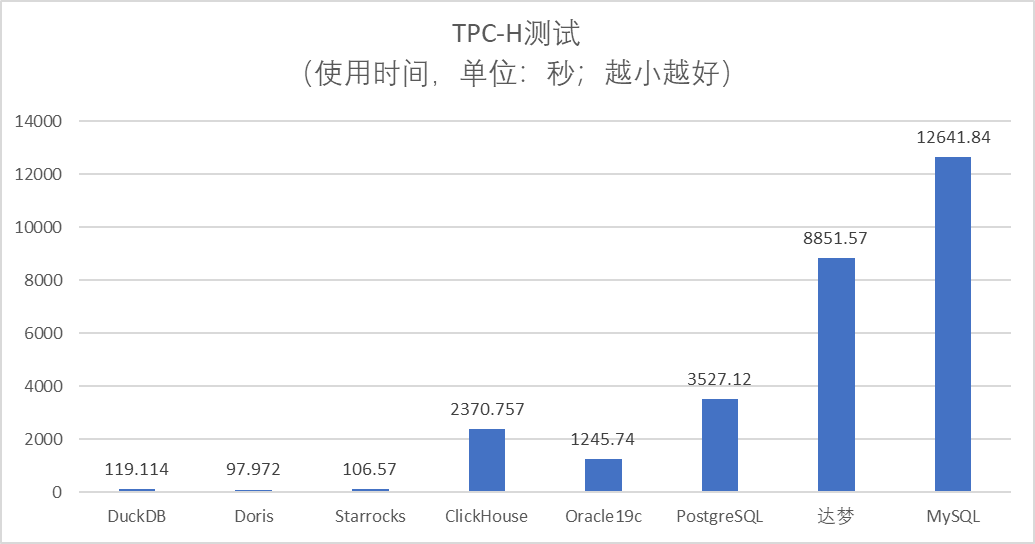
排名 | 数据库 | 运行时间 单位:秒 | 总结 |
1 | Doris v2.1.2 | 97.97 | 整体表现非常优秀,轻松完成所有任务 |
2 | Starrocks v3.2.6 | 106.57 | 整体表现非常优秀,轻松完成所有任务 |
3 | DuckDB v0.10.2 | 119.11 | 整体表现非常优秀,轻松完成所有任务,作为一个后起新秀,嵌入式的OLAP数据库,表现非常出色 |
4 | Oracle 19c | 1245.74 | 完成所有任务,性能中等,表现很稳定,不会出现内存不足的现象。 |
5 | ClickHouse 2024.04 | 2370.76 | 完成20个任务,数据导入非常快,单表查询表现出了优秀的性能力,两表Join以上性能急剧下滑,复杂查询容易出现内存不足而运行出错 |
6 | PostgreSQL v15.7 | 3527.1 | 完成19个任务,普遍性能不高,算法细节实现和Oracle还有差距,可以应用于简单的HTAP场景 |
7 | 达梦V8 202404 | 8851.57 | 完成11个查询SQL,整体性能不高,HASH JOIN内存控制还有待提升,容易出现内存不足导致SQL执行出错 |
8 | MySQL v8.0.32 | 12641.84 | 22个任务仅完成1个,完全不适合数据分析 |
接下来详细描述TPC-H测试方法和8种数据库的测试成绩
TPC-H数据模型简介
TPC-H主要模拟供应商和采购商之间的订单交易,模型总共8张表
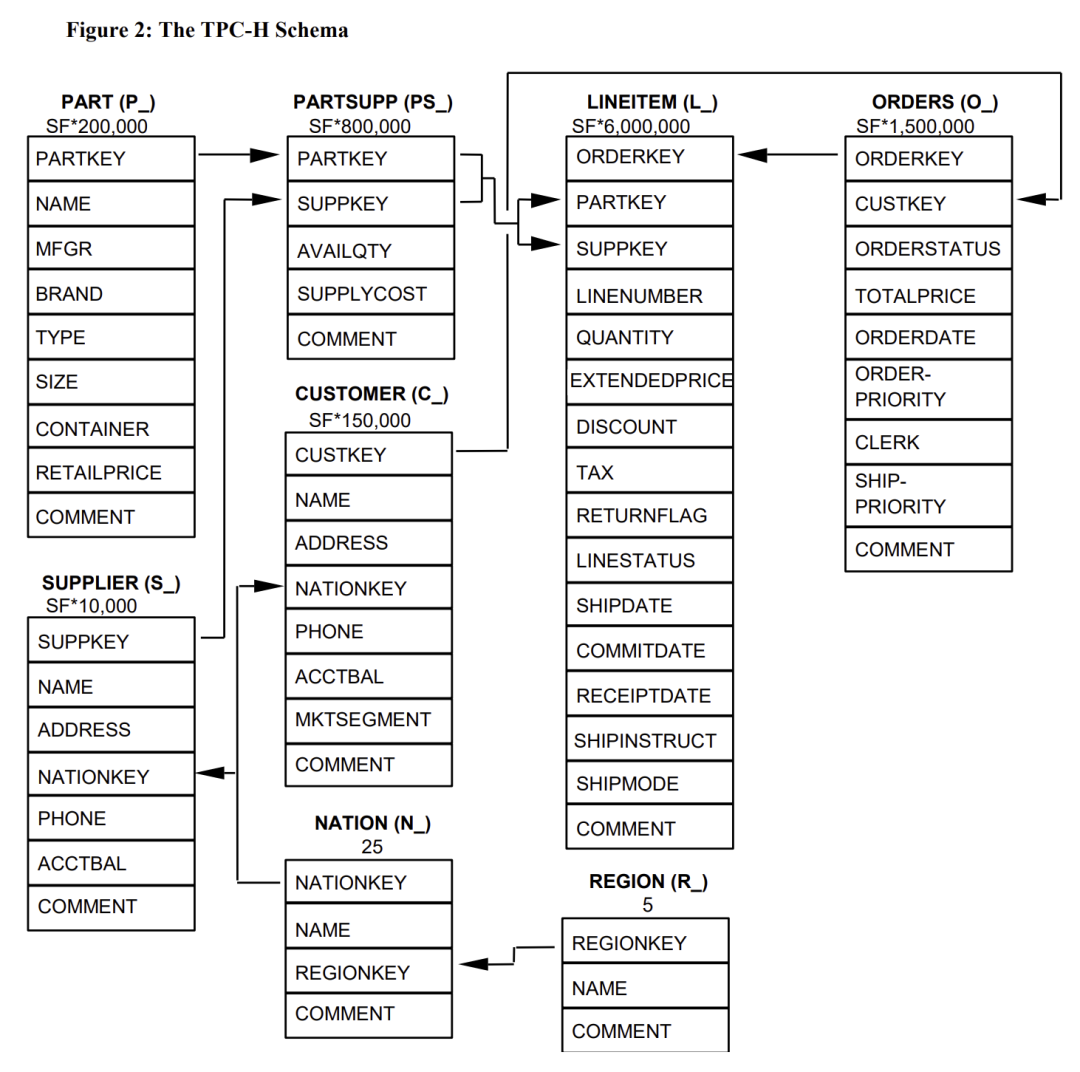
region:区域表,固定5条记录 nation:国家表,固定25条记录 supplier:供应商表,数据量因子*10000条记录 customer:客户表,数据量因子*150000条记录 part:商品表,数据量因子*200000条记录 partsupp:供应商物件表:数据量因子*800000条记录 orders:订单表,数据量因子*1500000条记录 lineitem:订单明细表,数据量因子*6000000条记录(最大的表,占总数据率70%)
模型建表
以下是MySQL语法参考,其他数据库可以根据语法修改
create database tpch;use tpch;CREATE TABLE `customer` (`c_custkey` int(11) NOT NULL,`c_name` varchar(25) NOT NULL,`c_address` varchar(40) NOT NULL,`c_nationkey` int(11) NOT NULL,`c_phone` varchar(15) NOT NULL,`c_acctbal` decimal(15,2) NOT NULL,`c_mktsegment` varchar(10) NOT NULL,`c_comment` varchar(117) NOT NULL,PRIMARY KEY (`c_custkey`)) ENGINE=InnoDB DEFAULT CHARSET=latin1;CREATE TABLE `lineitem` (`l_orderkey` bigint(20) NOT NULL,`l_partkey` int(11) NOT NULL,`l_suppkey` int(11) NOT NULL,`l_linenumber` bigint(20) NOT NULL,`l_quantity` decimal(15,2) NOT NULL,`l_extendedprice` decimal(15,2) NOT NULL,`l_discount` decimal(15,2) NOT NULL,`l_tax` decimal(15,2) NOT NULL,`l_returnflag` varchar(1) NOT NULL,`l_linestatus` varchar(1) NOT NULL,`l_shipdate` date NOT NULL,`l_commitdate` date NOT NULL,`l_receiptdate` date NOT NULL,`l_shipinstruct` varchar(25) NOT NULL,`l_shipmode` varchar(10) NOT NULL,`l_comment` varchar(44) NOT NULL,PRIMARY KEY (`l_orderkey`,`l_linenumber`)) ENGINE=InnoDB DEFAULT CHARSET=latin1;CREATE TABLE `orders` (`o_orderkey` bigint(20) NOT NULL,`o_custkey` int(11) NOT NULL,`o_orderstatus` varchar(1) NOT NULL,`o_totalprice` decimal(15,2) NOT NULL,`o_orderdate` date NOT NULL,`o_orderpriority` varchar(15) NOT NULL,`o_clerk` varchar(15) NOT NULL,`o_shippriority` bigint(20) NOT NULL,`o_comment` varchar(79) NOT NULL,PRIMARY KEY (`O_ORDERKEY`)) ENGINE=InnoDB DEFAULT CHARSET=latin1;CREATE TABLE `part` (`p_partkey` int(11) NOT NULL,`p_name` varchar(55) NOT NULL,`p_mfgr` varchar(25) NOT NULL,`p_brand` varchar(10) NOT NULL,`p_type` varchar(25) NOT NULL,`p_size` int(11) NOT NULL,`p_container` varchar(10) NOT NULL,`p_retailprice` decimal(15,2) NOT NULL,`p_comment` varchar(23) NOT NULL,PRIMARY KEY (`p_partkey`)) ENGINE=InnoDB DEFAULT CHARSET=latin1 ;CREATE TABLE `partsupp` (`ps_partkey` int(11) NOT NULL,`ps_suppkey` int(11) NOT NULL,`ps_availqty` int(11) NOT NULL,`ps_supplycost` decimal(15,2) NOT NULL,`ps_comment` varchar(199) NOT NULL,KEY `IDX_PARTSUPP_SUPPKEY` (`PS_SUPPKEY`),PRIMARY KEY (`ps_partkey`,`ps_suppkey`)) ENGINE=InnoDB DEFAULT CHARSET=latin1;CREATE TABLE `supplier` (`s_suppkey` int(11) NOT NULL,`s_name` varchar(25) NOT NULL,`s_address` varchar(40) NOT NULL,`s_nationkey` int(11) NOT NULL,`s_phone` varchar(15) NOT NULL,`s_acctbal` decimal(15,2) NOT NULL,`s_comment` varchar(101) NOT NULL,PRIMARY KEY (`s_suppkey`)) ENGINE=InnoDB DEFAULT CHARSET=latin1;CREATE TABLE `nation` (`n_nationkey` int(11) NOT NULL,`n_name` varchar(25) NOT NULL,`n_regionkey` int(11) NOT NULL,`n_comment` varchar(152) DEFAULT NULL,PRIMARY KEY (`n_nationkey`)) ENGINE=InnoDB DEFAULT CHARSET=latin1;CREATE TABLE `region` (`r_regionkey` int(11) NOT NULL,`r_name` varchar(25) NOT NULL,`r_comment` varchar(152) DEFAULT NULL,PRIMARY KEY (`r_regionkey`)) ENGINE=InnoDB DEFAULT CHARSET=latin1;
TPC-H 评测SQL简介
多表Join
子查询
分组汇总(Group By,SUM)
过滤计算(like模糊查询,Case when等)
视图关联查询
以TPC-H第21号SQL举例,一条SQL包括了多表关联、子查询、Group by、Order By几种数据分析中常见的运算:
#TPC-H 21号SQLselects_name,count(*) as numwaitfromsupplier,lineitem l1,orders,nationwheres_suppkey = l1.l_suppkeyand o_orderkey = l1.l_orderkeyand o_orderstatus = 'F'and l1.l_receiptdate > l1.l_commitdateand exists (select*fromlineitem l2wherel2.l_orderkey = l1.l_orderkeyand l2.l_suppkey <> l1.l_suppkey)and not exists (select*fromlineitem l3wherel3.l_orderkey = l1.l_orderkeyand l3.l_suppkey <> l1.l_suppkeyand l3.l_receiptdate > l3.l_commitdate)and s_nationkey = n_nationkeyand n_name = 'RUSSIA'group bys_nameorder bynumwait desc,s_name;
tpc-h完整的22条sql可以参考dbgen工具包内容,不同的数据库需要根据语法特性微调。
测试数据生成
TPC-H官方提供了测试数据集构建标准程序,下载地址,下载后可以直接编译运行
https://www.tpc.org/TPC_Documents_Current_Versions/download_programs/tools-download-request5.asp?bm_type=TPC-H&bm_vers=3.0.1&mode=CURRENT-ONLY
cd dbgen#从模版中创建编译需要用的makefilecp makefile.suit makefile
配置makefile内容
CC=gcc,DATABASE=ORACLE,MACHINE=LINUX,WORKLOAD=TPCH,具体参考如下:
## CHANGE NAME OF ANSI COMPILER HERE################CC = gcc# Current values for DATABASE are: INFORMIX, DB2, TDAT (Teradata)# SQLSERVER, SYBASE, ORACLE, VECTORWISE# Current values for MACHINE are: ATT, DOS, HP, IBM, ICL, MVS,# SGI, SUN, U2200, VMS, LINUX, WIN32# Current values for WORKLOAD are: TPCHDATABASE=ORACLEMACHINE = LINUXWORKLOAD = TPCH
# 执行编译,生成dbgen可以执行文件make
接下来可以用dbgen生成测试数据集,dbgen有非常多的参数,可以根据需要灵活使用,如果是100GB以内的小数据量,可以直接单线程一键生成
# -s后面跟上数据集大小,单位是GB./dbgen -s 100
dbgen执行完成后,在目录下会产生以下数据文件,都是csv格式,字段间分隔符是"|"
customer.tblnation.tblregion.tblsupplier.tblpart.tblpartsupp.tbllineitem.tblorders.tbl
如果超过100GB的数据量,建议几个大表并行生成数据,尤其是订单和明细表 orders,lineitem这个两个大表,如下:-T 表示单独生成某个表的数据,-C表示计划分割为几个文件,-S表示当前生成第几份数据,通过分割文件可以并行生成数据,提升效率,后面导入到数据库也可以直接并行加速。
./dbgen -s 200 -T o -C 10 -S 1 &./dbgen -s 200 -T o -C 10 -S 2 &./dbgen -s 200 -T o -C 10 -S 3 &./dbgen -s 200 -T o -C 10 -S 4 &./dbgen -s 200 -T o -C 10 -S 5 &./dbgen -s 200 -T o -C 10 -S 6 &./dbgen -s 200 -T o -C 10 -S 7 &./dbgen -s 200 -T o -C 10 -S 8 &./dbgen -s 200 -T o -C 10 -S 9 &./dbgen -s 200 -T o -C 10 -S 10 &
以下是各种数据库的测试明细
MySQL v8.0.32
导入数据
# 为了优化导入性能,可以做以下优化,都是危险操作,千万不要在生产数据库操作。
1. 关闭Binlog2. 关闭REDO_LOG3. 关闭Double Write
使用mysql的load data指令导入数据
load data local infile '/data/tpch3/dbgen/customer.tbl' into table customer fields terminated by '|';load data local infile '/data/tpch3/dbgen/lineitem.tbl' into table lineitem fields terminated by '|';load data local infile '/data/tpch3/dbgen/nation.tbl' into table nation fields terminated by '|';load data local infile '/data/tpch3/dbgen/orders.tbl' into table orders fields terminated by '|';load data local infile '/data/tpch3/dbgen/partsupp.tbl' into table partsupp fields terminated by '|';load data local infile '/data/tpch3/dbgen/part.tbl' into table part fields terminated by '|';load data local infile '/data/tpch3/dbgen/region.tbl' into table region fields terminated by '|';load data local infile '/data/tpch3/dbgen/supplier.tbl' into table supplier fields terminated by '|';
执行TPC-H SQL(操作省略)确实是小试牛刀,MySQL根本不适合TPC-H,即使设置了并行查询,但是只有在比较简单的单表SQL查询中可以,加上group by或者join后基本都只能是单线程操作,MySQL最后只完成了Q2,其他21条SQL都查询超时
查询语句 | 执行时间 |
Q1 | 超时 |
Q2 | 41.84 |
Q3 | 超时 |
Q4 | 超时 |
... | ... |
Q22 | 超时 |
总结:这个成绩真惨不忍睹,如果你要把MySQL用于查询分析,那基本是死翘翘。
PostgreSQL v15.7
功能最强大的开源关系型数据库PostgreSQL,看看是否能完成任务。
PostgreSQL可以采用copy导入csv文件,语法如下:
COPY customer FROM '/data/tpch3/dbgen/customer.tbl' delimiter '|' ;
需要注意的是TPC-H dbgen生成的csv格式最后多了一个"|",PostgreSQL COPY无法直接导入,可以在TPCH所有表增加一个临时的字段,或者用shell脚本批量把最后的"|"去除,类似下面的脚本
for i in `ls *.tbl`; do sed 's/|$//' $i > ${i/tbl/csv}; done
#大表设置并行alter table LINEITEM set (parallel_workers=16);alter table ORDERS set (parallel_workers=16);alter table PARTSUPP set (parallel_workers=16);alter table PART set (parallel_workers=16);#关闭表autovacuumALTER TABLE LINEITEM SET (autovacuum_enabled = off);ALTER TABLE ORDERS SET (autovacuum_enabled = off);ALTER TABLE PARTSUPP SET (autovacuum_enabled = off);ALTER TABLE PART SET (autovacuum_enabled = off);ALTER TABLE CUSTOMER SET (autovacuum_enabled = off);ALTER TABLE SUPPLIER SET (autovacuum_enabled = off);
执行结果
| 查询 | 执行时间 |
| Q1 | 149.26 |
| Q2 | 29.07 |
| Q3 | 90.03 |
| Q4 | 72.53 |
| Q5 | 102.01 |
| Q6 | 55.74 |
| Q7 | 77.44 |
| Q8 | 87.11 |
| Q9 | 超时 |
| Q10 | 98.25 |
| Q11 | 19.69 |
| Q12 | 71.94 |
| Q13 | 63.79 |
| Q14 | 64.32 |
| Q15 | 272.28 |
| Q16 | 125.39 |
| Q17 | 94.37 |
| Q18 | 超时 |
| Q19 | 51.14 |
| Q20 | 超时 |
| Q21 | 195.04 |
| Q22 | 7.72 |
总结:22条SQL,PostgreSQL执行成功19条,有3条SQL执行超时,比MySQL好了很多,对于一些HTAP场景,可以满足基本需求,超时的3条SQL都是有3张以上表的Join,PostgreSQL在并行查询性能方面算法还有待提升。
Oracle19c
老牌商业数据库,本次测试的是普通Oracle19c,没有使用Exadata,因此只使用行存模式。
#软件从官方下载https://www.oracle.com/database/technologies/oracle-database-software-downloads.html#安装手册https://docs.oracle.com/en/database/oracle/oracle-database/19/ladbi/running-rpm-packages-to-install-oracle-database.html
#设置表不记录log,可以加速导入alter table lineitem NOLOGGING;alter table partsupp NOLOGGING;alter table orders NOLOGGING;alter table part NOLOGGING;
导入csv数据可以使用Oracle自带的sqlldr工具
sqlldr userid=test/test@ORCLPDB1 control=load_tpch_customer.ctl rows=1000000 bindsize=20971520 direct=true
load_tpch_customer.ctl文件示例LOAD DATA INFILE 'customer.tbl' INTO TABLE customer TRAILING NULLCOLS (C_CUSTKEY terminated by '|',C_NAME terminated by '|',C_ADDRESS terminated by '|',C_NATIONKEY terminated by '|',C_PHONE terminated by '|',C_ACCTBAL terminated by '|',C_MKTSEGMENT terminated by '|',C_COMMENT terminated by '|')
#设置大表开启并行查询alter table LINEITEM parallel(degree 16);alter table PART parallel(degree 4);alter table CUSTOMER parallel(degree 4);alter table ORDERS parallel(degree 4);alter table PARTSUPP parallel(degree 4);#收集表统计信息,数据导入完毕后执行EXEC DBMS_STATS.GATHER_TABLE_STATS(ownname=> 'TEST',tabname=> 'LINEITEM',estimate_percent=>0.1,block_sample=> TRUE, method_opt=> 'FOR ALL COLUMNS SIZE AUTO');EXEC DBMS_STATS.GATHER_TABLE_STATS(ownname=> 'TEST',tabname=> 'PART',estimate_percent=>1,block_sample=> TRUE, method_opt=> 'FOR ALL COLUMNS SIZE AUTO');EXEC DBMS_STATS.GATHER_TABLE_STATS(ownname=> 'TEST',tabname=> 'SUPPLIER',estimate_percent=>1,block_sample=> TRUE, method_opt=> 'FOR ALL COLUMNS SIZE AUTO');EXEC DBMS_STATS.GATHER_TABLE_STATS(ownname=> 'TEST',tabname=> 'PARTSUPP',estimate_percent=>1,block_sample=> TRUE, method_opt=> 'FOR ALL COLUMNS SIZE AUTO');EXEC DBMS_STATS.GATHER_TABLE_STATS(ownname=> 'TEST',tabname=> 'CUSTOMER',estimate_percent=>1,block_sample=> TRUE, method_opt=> 'FOR ALL COLUMNS SIZE AUTO');EXEC DBMS_STATS.GATHER_TABLE_STATS(ownname=> 'TEST',tabname=> 'ORDERS',estimate_percent=>1,block_sample=> TRUE, method_opt=> 'FOR ALL COLUMNS SIZE AUTO');EXEC DBMS_STATS.GATHER_TABLE_STATS(ownname=> 'TEST',tabname=> 'NATION',estimate_percent=>1,block_sample=> TRUE, method_opt=> 'FOR ALL COLUMNS SIZE AUTO');EXEC DBMS_STATS.GATHER_TABLE_STATS(ownname=> 'TEST',tabname=> 'REGION',estimate_percent=>1,block_sample=> TRUE, method_opt=> 'FOR ALL COLUMNS SIZE AUTO');
执行结果| 查询 | 执行时间 |
| Q1 | 59.67 |
| Q2 | 13.64 |
| Q3 | 77.75 |
| Q4 | 64.06 |
| Q5 | 65.95 |
| Q6 | 57.43 |
| Q7 | 66.98 |
| Q8 | 67.43 |
| Q9 | 82.34 |
| Q10 | 141.63 |
| Q11 | 9.97 |
| Q12 | 63.82 |
| Q13 | 41.26 |
| Q14 | 16.67 |
| Q15 | 59.17 |
| Q16 | 18.37 |
| Q17 | 29.33 |
| Q18 | 74.68 |
| Q19 | 71.02 |
| Q20 | 31.64 |
| Q21 | 127.94 |
| Q22 | 4.99 |
总结:Oracle19c完成了所有任务,性能中等,Join表现很稳定,不会出现内存不足的现象。由于Oracle列存压缩仅在Exadata支持,本次使用的是行存模式,并不能展现出Oracle的最强能力。Oracle在大表扫描方面使用并行全表查询,硬盘性能大约3GB/s,因此需要全表访问大表lineitem(140GB)的任务,基本都是50秒以上。
达梦8 v20240408
达梦是老牌国产数据库,超过20年历史,以Oracle兼容性著称
达梦8安装安装比较方便,可以在官网直接下(https://www.dameng.com),根据安装文档一步一步安装即可
可以自带的dmfldr工具导入csv数据,语法和Oracle的sqlldr类似
./dmfldr userid=TEST/Dameng_123:5236 control=\'load_tpch_customer.ctl\' direct=true
#load_tpch_customer.ctl 文件示例LOAD DATA INFILE 'customer.tbl' INTO TABLE customer (C_CUSTKEY terminated by '|',C_NAME terminated by '|',C_ADDRESS terminated by '|',C_NATIONKEY terminated by '|',C_PHONE terminated by '|',C_ACCTBAL terminated by '|',C_MKTSEGMENT terminated by '|',C_COMMENT terminated by '|')
#设置并行SP_SET_PARA_VALUE (1,'MAX_PARALLEL_DEGREE',16);
执行结果
| 查询 | 执行时间 |
| Q1 | 326.49 |
| Q2 | 65.59 |
| Q3 | 95.43 |
| Q4 | 290.35 |
| Q5 | 内存不足 |
| Q6 | 285.07 |
| Q7 | 内存不足 |
| Q8 | 内存不足 |
| Q9 | 内存不足 |
| Q10 | 内存不足 |
| Q11 | 20.92 |
| Q12 | 292.27 |
| Q13 | 超时 |
| Q14 | 273.94 |
| Q15 | 270.57 |
| Q16 | 28.65 |
| Q17 | 内存不足 |
| Q18 | 超时 |
| Q19 | 超时 |
| Q20 | 超时 |
| Q21 | 超时 |
| Q22 | 28.78 |
总结:22条SQL,达梦执行成功11条,另外11条SQL执行超时或出错,超时或出差的11条SQL都是有3张以上表的Join,达梦在Hash Join的内存管理方面欠佳,即使设置了内存大小,但还是很容易报全局内存不足。
ClickHouse v2024.04
ClickHouse是非常流行的开源列式数据仓库,由俄罗斯Yandex公司研发,目前是ClickHouse公司在推动发展。ClickHouse以惊人的单表查询能力著称,很好的弥补了大数据平台OLAP交互式分析能力。
由于ClickHouse并不能执行标准TPC-H的SQL语法,所以需要在查询语法上做一些修改,具体参考如下文章
https://www.cnblogs.com/syw20170419/p/16421131.html
ClickHouse数据导入非常简单,可以直接使用Insert into table from infile语法,如下所示
SET format_csv_delimiter = '|';INSERT INTO customer from infile '/data/tpch3/dbgen/customer.tbl' FORMAT CSV;
执行结果:| 查询 | 执行时间 |
| Q1 | 0.415 |
| Q2 | 7.632 |
| Q3 | 45.953 |
| Q4 | 175.988 |
| Q5 | 110.021 |
| Q6 | 3.691 |
| Q7 | 112.006 |
| Q8 | 172.344 |
| Q9 | 内存不足 |
| Q10 | 44.416 |
| Q11 | 4.62 |
| Q12 | 6.768 |
| Q13 | 48.432 |
| Q14 | 6.037 |
| Q15 | 2.86 |
| Q16 | 5.08 |
| Q17 | 28.806 |
| Q18 | 215.036 |
| Q19 | 118.199 |
| Q20 | 48.293 |
| Q21 | 内存不足 |
| Q22 | 14.16 |
总结:ClickHouse数据导入非常快,单线程可以到达300MB/s,总共完成20个任务,2个任务失败,单表查询表现出了优秀的性能力,两表Join以上性能急剧下滑,复杂查询容易出现内存不足而运行出错。ClickHouse有众多的使用者,遇到普通问题在网上都可以找到解决方案。
Doris 2.1.2
Apache Doris 是一款基于 MPP 架构的高性能、实时的分析型数据库。
Apache Doris 最早是诞生于百度广告报表业务的 Palo 项目,2017 年正式对外开源,2018 年 7 月由百度捐赠给 Apache 基金会进行孵化,之后在 Apache 导师的指导下由孵化器项目管理委员会成员进行孵化和运营。2022 年 6 月,Apache Doris 成功从 Apache 孵化器毕业,正式成为 Apache 顶级项目(Top-Level Project,TLP)。目前 Apache Doris 社区已经聚集了来自不同行业数百家企业的 600 余位贡献者,并且每月活跃贡献者人数也超过 120 位。
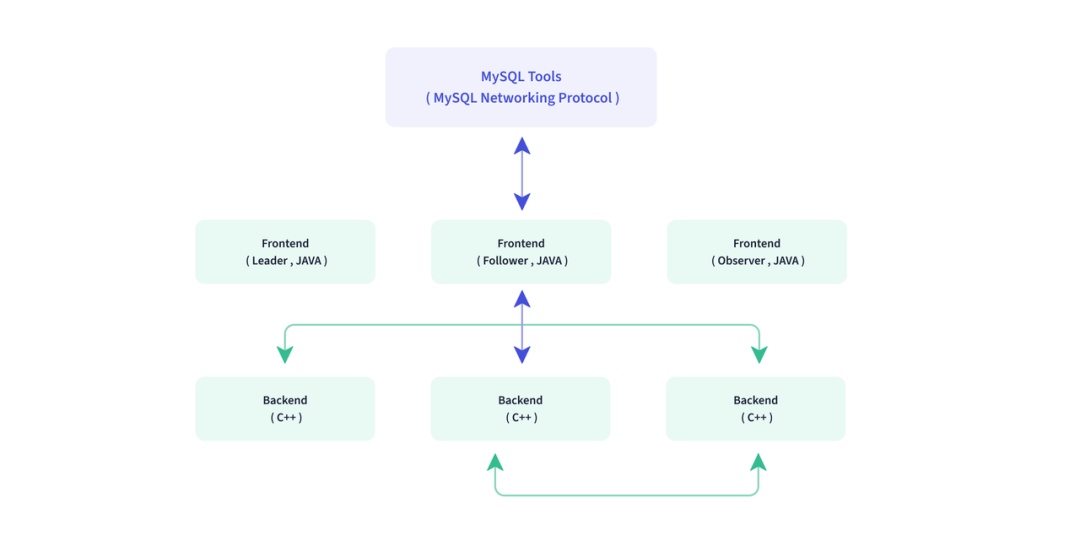
Doris 采用 MySQL 协议,高度兼容 MySQL 语法,整体上是FE(前端节点)+BE(后端计算与数据存储节点)的MPP架构,如下图所示。
doris可以使用stream load的模式导入csv数据,性能可以达到200MB/s
curl --location-trusted -u admin:admin -T data/tpch3/dbgen/customer.tbl -H "column_separator:|" -H "columns: c_custkey, c_name, c_address, c_nationkey, c_phone, c_acctbal, c_mktsegment, c_comment, temp" http://127.0.0.1:8030/api/tpch200/customer/_stream_load#如果导入的csv文件很大,可以先设置最大导入的文件大小curl -X POST http://127.0.0.1:8030/api/update_config?streaming_load_max_mb=10240
执行结果:
| 查询 | 执行时间 |
| Q1 | 13.22 |
| Q2 | 0.761 |
| Q3 | 3.731 |
| Q4 | 3.308 |
| Q5 | 6.293 |
| Q6 | 0.415 |
| Q7 | 2.212 |
| Q8 | 3.793 |
| Q9 | 11.499 |
| Q10 | 6.835 |
| Q11 | 0.709 |
| Q12 | 0.944 |
| Q13 | 8.835 |
| Q14 | 0.527 |
| Q15 | 0.803 |
| Q16 | 1.435 |
| Q17 | 1.929 |
| Q18 | 15.366 |
| Q19 | 3.095 |
| Q20 | 2.428 |
| Q21 | 8.755 |
| Q22 | 1.079 |
总结:Doris数据导入非常快,并且轻松完成了所有任务,本次测试内存128GB,Doris导入列式压缩后实际空间大约60GB,因此大部分请求都是在内存中可以计算完成,如果数据量更大,Doris可能会发生内存不足的现象。
Starrocks
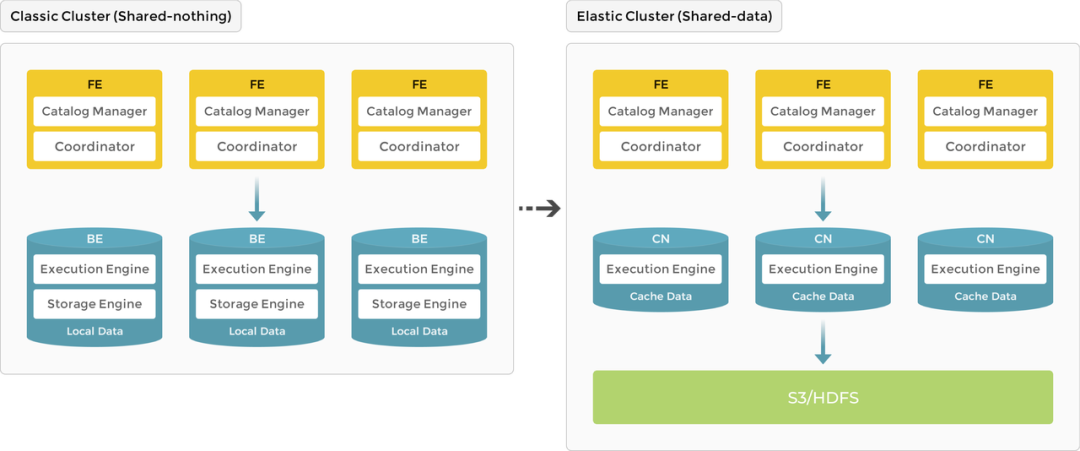
Starrocks与Doris在早期是同一个内核引擎,也是FE+BE的架构,现在已经是独立开源产品演进。Starrocks最新版本支持存储计算完全分离的架构,可以把数据存储在S3、HDFS、MinIO等共享对象存储上,通过增加无数据的CN节点完成计算扩展,如下图所示。
本次测试采用单机FE+BE架构部署
starrocks操作与doris基本一致,可以使用stream load的模式导入csv数据,性能可以达到200MB/s
curl --location-trusted -u admin:admin -T data/tpch3/dbgen/customer.tbl -H "column_separator:|" -H "columns: c_custkey, c_name, c_address, c_nationkey, c_phone, c_acctbal, c_mktsegment, c_comment, temp" http://127.0.0.1:8030/api/tpch200/customer/_stream_load
执行结果:| 查询 | 执行时间 |
| Q1 | 10.42 |
| Q2 | 0.44 |
| Q3 | 6.02 |
| Q4 | 4.66 |
| Q5 | 7.99 |
| Q6 | 0.35 |
| Q7 | 4.58 |
| Q8 | 4.71 |
| Q9 | 12.76 |
| Q10 | 7.94 |
| Q11 | 0.73 |
| Q12 | 1.21 |
| Q13 | 10.09 |
| Q14 | 0.84 |
| Q15 | 0.95 |
| Q16 | 1.79 |
| Q17 | 2.51 |
| Q18 | 12.03 |
| Q19 | 3.29 |
| Q20 | 1.26 |
| Q21 | 10.93 |
| Q22 | 1.07 |
总结:Starrocks数据导入非常快,并且轻松完成了所有任务。
DuckDB(0.10.2)
DuckDB是2019年荷兰人发布的一个高性能的嵌入式开源分析性数据,它的定位类似面向OLAP的SQLite,非常轻巧,不需要安装,可以嵌入到多种语言中。比如在java中,只需要引入duckdb的jar包,就可以在代码里创建一个本地文件存储的duckdb数据仓库。DuckDB性能非常出色,本次测试中表现非常亮眼,一个仅15MB的小型嵌入式数据库达到了大型MPP系统的性能。
duckdb在tpc-h和tpc-ds方面都附加的插件,可以直接使用,非常方便
https://duckdb.org/docs/extensions/tpch
#安装tpch插件INSTALL tpch;#加载插件LOAD tpch;#生成200GB数据CALL dbgen(sf = 200);#运行具体的TPC-H任务PRAGMA tpch(1);PRAGMA tpch(2);...PRAGMA tpch(22);
使用默认的tpc-h生成数据比较慢,也可以使用COPY语法导入使用TPC-H官方工具生成的数据,不需要知道分隔符,duckdb默认会自动识别CSV的格式,非常方便。
COPY customer FROM '/data/tpch3/dbgen/customer.tbl';
执行结果:
| 查询 | 执行时间 |
| Q1 | 5.209 |
| Q2 | 1.417 |
| Q3 | 3.369 |
| Q4 | 3.051 |
| Q5 | 3.492 |
| Q6 | 1.006 |
| Q7 | 15.31 |
| Q8 | 3.995 |
| Q9 | 8.681 |
| Q10 | 5.756 |
| Q11 | 1.074 |
| Q12 | 2.548 |
| Q13 | 11.28 |
| Q14 | 2.139 |
| Q15 | 3.372 |
| Q16 | 1.496 |
| Q17 | 3.339 |
| Q18 | 21.53 |
| Q19 | 5.679 |
| Q20 | 2.808 |
| Q21 | 10.56 |
| Q22 | 2.003 |
总结:整体表现非常优秀,轻松完成了所有任务,作为一个后起新秀,嵌入式的OLAP数据库,表现非常出色,如果数据库可以在单机内管理,duckdb是非常有竞争力的产品。
总结
从测试结果看:
Starrocks、Doris、DuckDB是目前OLAP引擎中第一梯队,可以轻松处理TPC-H的任务。 ClickHouse是非常流行的开源数据仓库,在单表查询方面比较强,但是多表关联计算能力容易较弱,并且容易发生内存不足现象。 MySQL、PostgreSQL、达梦数据库主要还是面向OLTP场景,在本次TPC-H测试中表现欠佳。 Oracle作为老牌数据库,测试中表现非常稳定,数据量在增加也不会出现内存不足的现象,但是由于行式存储引擎的缺陷,在性能上与列式存储引擎有巨大的差距,更适合复杂的HTAP场景。
为了公平起见,本次TPC-H测试使用了完全相同的硬件,所有产品都是单机部署,重点是测试各个产品的单机处理能力,没有测试Starrocks、Doris、ClickHouse这些MPP产品的分布式处理能力。计划在未来的工作中继续完善。
关于作者
叶正盛,NineData 创始人 &CEO,资深数据库专家,原阿里云数据库产品管理与解决方案部总经理。NineData(www.ninedata.cloud)是云原生数据管理平台,提供数据库 DevOps(SQL IDE、SQL 审核与发布、性能优化、数据安全管控)、数据复制(迁移、同步、ETL)、备份等功能,可以帮助用户更安全、高效使用数据。
