




引言
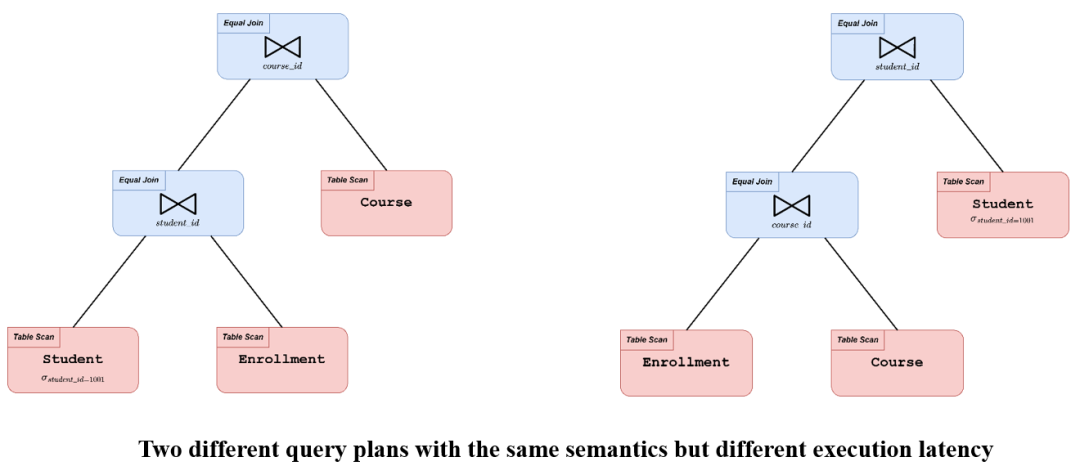
优化器是数据库的核心组件,被誉为“数据库的大脑”。它将一个SQL查询“翻译”为一个高效的执行计划,交给执行引擎运行。对于一个SQL查询,往往有许多种不同的执行计划。它们具有相同的语义,但执行时间可能大相径庭。下图示例展示了同一个SQL查询的两种不同的执行计划。如何从庞杂的计划空间中选出执行时间最短的计划,是查询优化的核心问题。
解决查询优化问题,通常有基于规则的方法、基于启发式的方法和基于代价的方法。其中,效果最可靠、最广泛应用于各大主流商业数据库和开源数据的,是基于代价的优化器(Cost-Based Optimizer,CBO)。其思想是,根据数据库中的所存数据的统计信息,为每个计划估计一个代价,选出执行代价最小的计划。实践中,大多数情况下,基于代价的优化器已经足够好了,大多数查询都能生成不错的计划,在几十年的实践中已被广泛应用。但是,基于代价的优化器也一直存在着一些问题:
困难查询往往产生次优的计划。传统优化器的基数估计模块常常使用一些假设,如均匀假设、独立假设,难以捕捉表的若干列的分布、不同表之间的关联关系。面对很多个表之间的复杂连接,难以对中间结果的大小做出准确的估计,产生很大的误差,从而引出糟糕的计划。 无法从失误中学习。当一个糟糕计划被执行后,产生较长的运行时间。传统优化器无法将这一信息作为反馈,来自我改进。面对同样的查询,下一次,它将继续产生同样的糟糕计划,无法在失误中学习。
为了解决上述问题,近年来,研究者们考虑能否将机器学习的方法应用到查询优化中,做了许多探索性的工作。相比之下,基于学习的方法有颇多优势:
基于学习的方法更擅长学习复杂的特征,捕获不同表连接之间的关系。 一个计划执行的结果,能作为反馈进行学习,改进模型性能。
本文对比较有代表性的若干工作进行梳理,总结运用机器学习解决查询优化问题可能的角度与方法,为后续工作提供一些参考。方便起见,将这些工作分为如下三个类别,依次介绍。
基于学习的优化器组件。例如,将基数估计模块、代价估计模块用一个可学习的模型替换掉。此类方法只是将CBO的某些组件用学习的方法替换掉,但总体框架不变。 端到端基于学习的优化器。此类方法抛弃了CBO整个基于代价搜索的框架,重新建模查询优化问题。这类方法将查询优化看成一个马尔可夫决策过程(Markov Decision Process, MDP)——状态定义为一个未完成的计划,动作定义为将两个子计划连接起来。之后用强化学习(Reinforcement Learning, RL)的方法来解决MDP。 结合基于学习的方法与传统方法。传统优化器虽然偶尔会产生糟糕的计划,但大多数时候表现足够好,并且传统优化器中凝聚了大量的人类智慧。如何利用基于学习的方法,并将传统优化器具有的知识利用起来,是这类方法的着眼点。
思路1:基于学习的优化器组件
此次方法的思想是将基数估计模块、代价估计模块用一个可学习的模型替换掉。
基于学习的基数估计是该类方法的重要代表,已有大量的工作研究。粗略的分,可以分为如下两类。此类方法的详细综述请参考[1]。
查询驱动(query-driven):假设已有查询集工作负载作为训练集,通过对进行学习获得模型,来预测未来查询的基数。通常是有监督学习。 数据驱动(data-driven):不从查询中学习,直接从存储的数据中学习,目标是学习底层数据的分布。通常是无监督学习。
基于学习的代价估计则是思考直接预测整个计划或单步算子的代价,相当于同时完成原有的基数估计+代价模型的任务。以下以论文“An End-to-End Learning-based Cost Estimator”(以下称Cost Estimator)[2]为例,介绍一种估计计划的执行代价的思路。
Cost Estimator [2]
本文是发表在2019年VLDB上的工作, 作者是清华大学孙佶、清华大学李国良老师。本文提出了一个端到端的基于学习的代价估计器,来替代传统优化器的代价估计模块。
代价估计的目标是给定一个计划,预测其总执行代价。观察到一个计划是一个树形的结构,计划是自底向上执行的。从直觉上,一个计划的Cardinality和Cost,应该是基于其子计划计算得出。所以,期待给执行树的每个结点一个Embedding,其中融合了Cardinality和Cost的信息,同时父亲节点的Embedding由两个子节点的Embedding求得。怎样设计模型,天然的适应计划树这种树形的结构?时序模型——LSTM!
模型设计:下图给出了完整的网络架构示意,以下分别介绍各个模块。
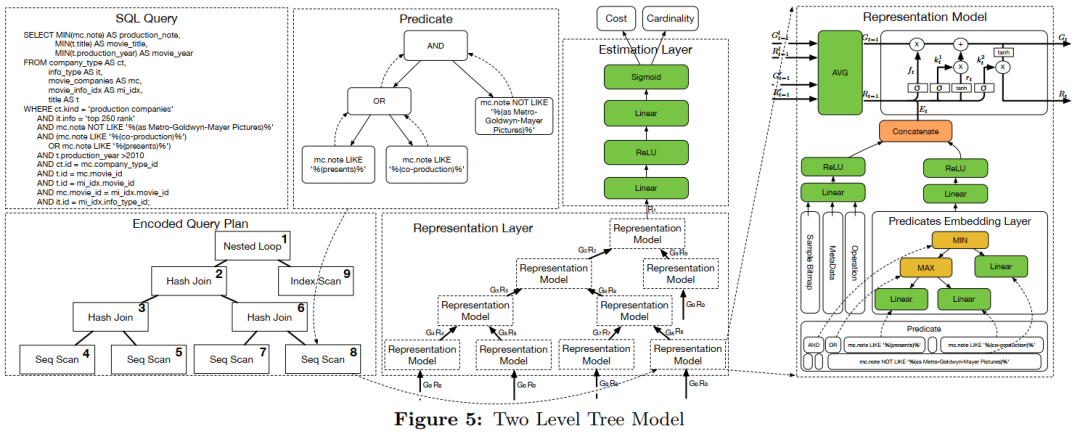
Embedding Layer
目的是将原始的编码过一层神经网络,得到embedding。如下,设的Operation、Metadata、Predicate、Sample Bitmap的编码分别为、、、(其实就是对算子的feature做的初始化)。可见都是简单过一层神经网络,Predicate的处理特别一些:把表达式树中的AND替换为MinPooling,把OR替换为MaxPooling。这种设计非常符合语义上的直觉。实验中也证明了这种方法更好:另一种方法是,遍历表达式树得到DFS序列,过LSTM,效果不如Pooling。
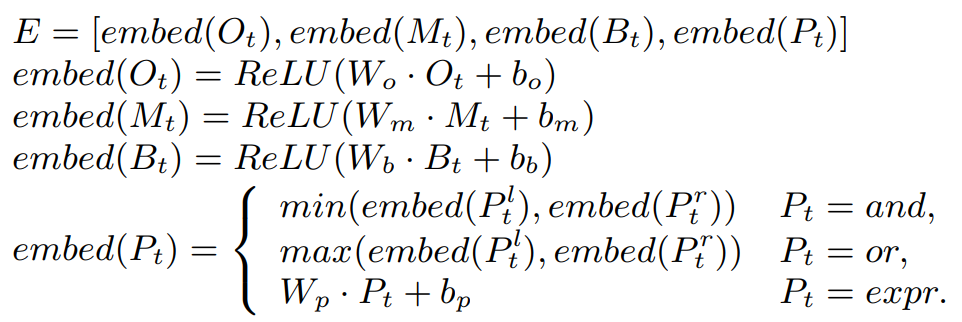
Representation Layer
自底向上为树中每个结点计算融合了Cardinality/Cost信息的embedding。具体来说,每个结点的输入是两个孩子的与。其中是融合了Cardinality/Cost信息的embedding,是历史记忆(i.e. 子树信息)。该节点需要根据左子信息与右子信息,以及自身的embedding信息,来计算自己的。方法很直接,计算左子右子的平均历史记忆与平均表征向量,融入,过一次LSTM即可。(注:记为LSTM中常用的记号c
,cell,记忆单元;就是常说的hidden state)。
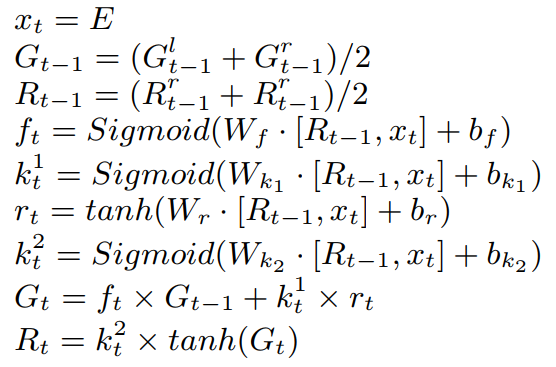
Estimation Layer
将融合了Cardinality/Cost信息的表征映射到Cardinality/Cost,简单的单层神经网络即可。本文的目的是预测Cost,但网络上同时预测了Cardinality,这是因为双头学习两个相关任务,可以利用多任务学习的好处,让模型具有更好的性能。
思路2:端到端基于学习的优化器
该方法将查询优化问题建模为马尔可夫决策过程(MDP),如图所示,
状态定义为一个部分计划(Partial Plan,包括空计划和完整计划)P,一个部分计划是一个森林,还未将所有的表Join起来,也有些表的访问模式还没确定(直接 Scan还是Index Seek) 状态转移为(1)确定一个表的访问方式(Scan 或 Index)(2)将两个子树通过某物理连接算子Join起来 每一步动作的价值定义为0 终点(完整计划)的价值(回报)定义为该计划在真实引擎上的执行时间(latency)的相反数。
而求解MDP,可以用强化学习的方法解决!这便是此类方法的核心。
ReJOIN [3]
这篇工作是用强化学习(RL)做查询优化中计划选择的先驱之作。作者注意到,通常的优化器都只有静态的查询优化算法,无法根据生成的计划质量的反馈改进策略。因此,本文提出了一款基于强化学习的优化器(deep reinforcement learning join order enumerator),能够从过往的经历中学习,希望生成更好的计划,同时更快的生成计划。本文通过简单的方法设计,展示了proof-of-concept的RL优化器,能够达到超越PostgreSQL优化器的性能。
简单起见,本文只考虑了Join Order的选取,不考虑物理算子的选择。
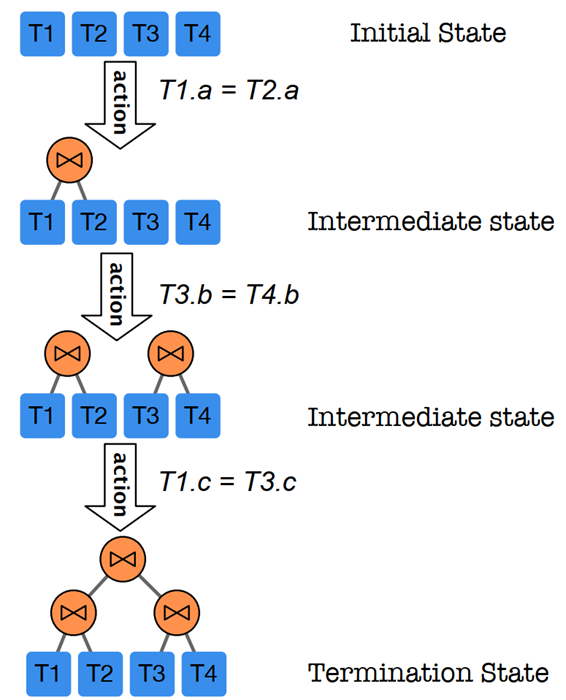
建模。本文首创性地将Join Order问题建模为马尔可夫决策过程。将状态定义为一个部分的计划,如下图的四个状态。初始状态是所有表都没有被连接,终止状态形成一棵完整的执行树。并且,终止状态的回报定义为该计划的执行时间的倒数,其余回报为0。
RL:策略网络是神经网络,是参数。给定任何状态(partial plan),根据获得所有可能动作的得分(概率分布)。对此概率分布采样执行采样,得到下一步的动作,最终得到一个计划,通过Cost Model(注意不是真正执行的latency)评估获得回报,就完成了一个trajectory。完成若干回合后,通过策略梯度算法可以更新,从而策略得到改进。(文章中用的具体RL算法:PPO)。
实验设定:
数据集:JOB,共113个查询,103个做训练集,10个做测试集 对比方法:PostgreSQL优化器,QuickPick100
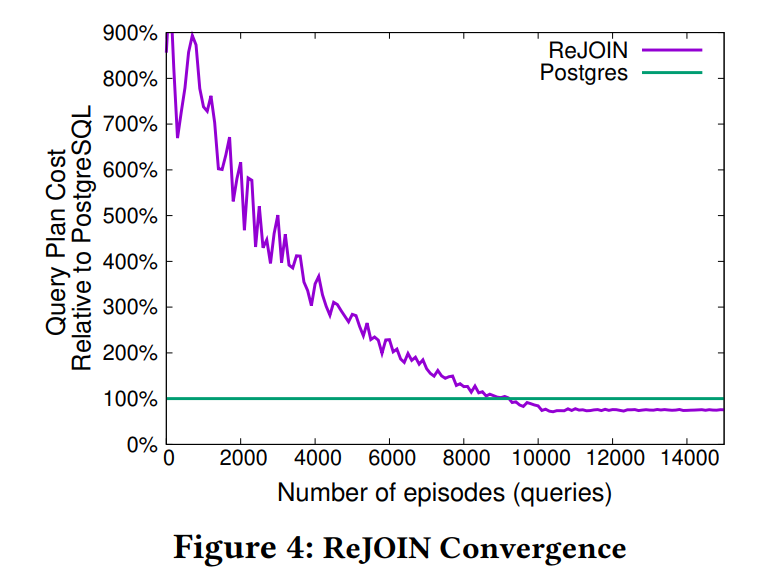
学习曲线
纵轴表示的是PostreSQL优化器估计的cost,不是执行latency
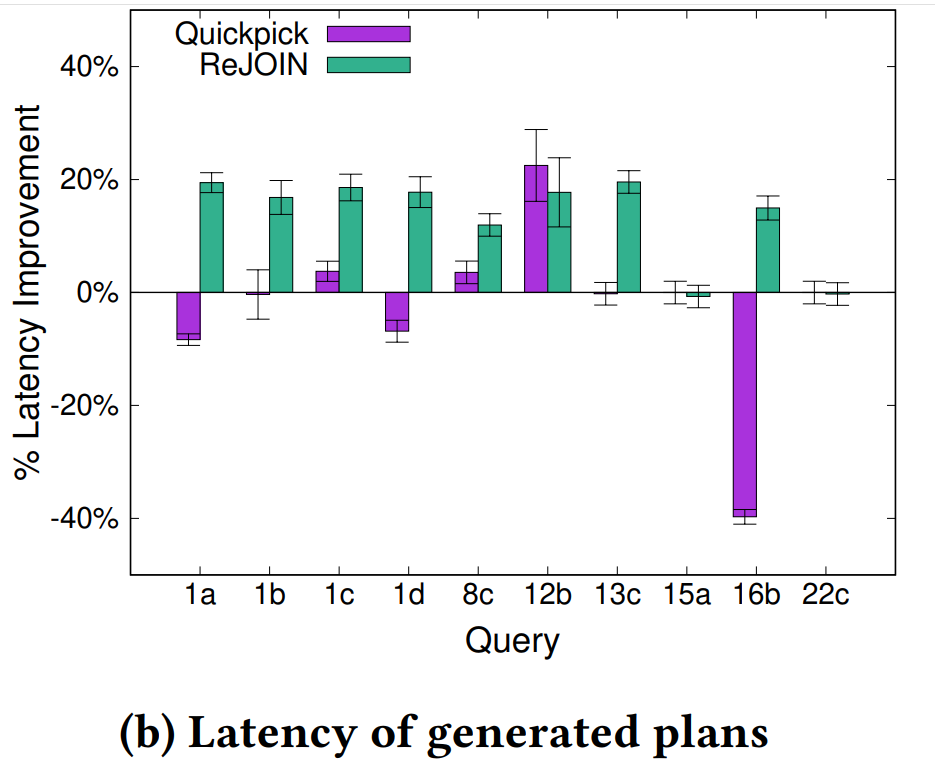
执行时间
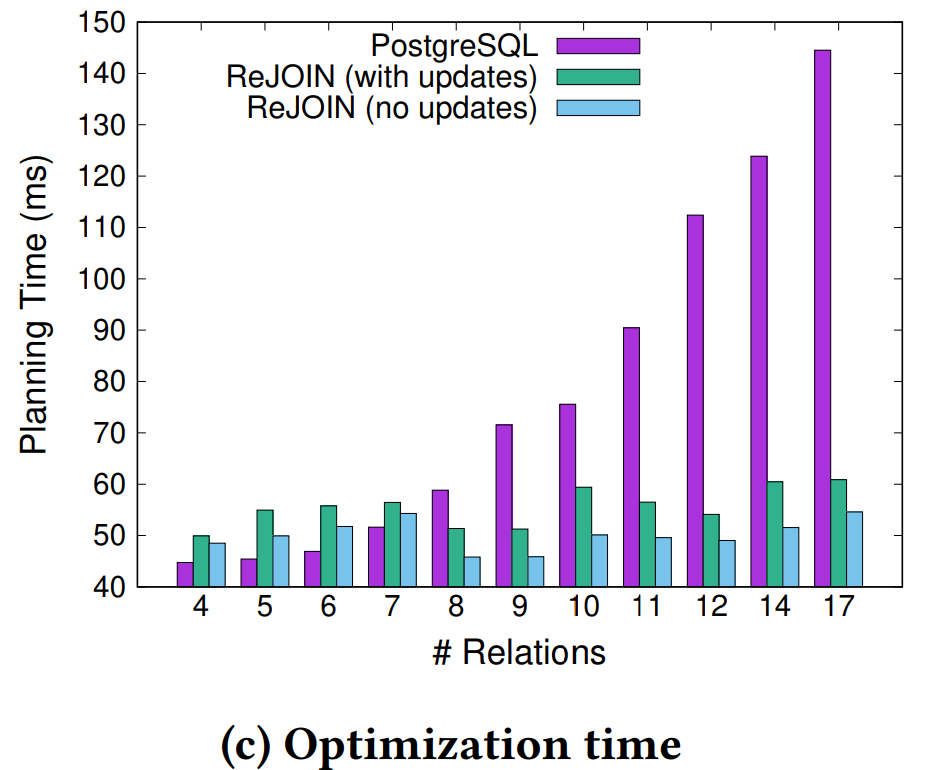
优化时间
同时标注了不更新网络和更新网络的时长,都足够快
Neo [4]
这是发表在2019年VLDB上的一篇工作。文章中提出了一个全新的端到端的基于深度学习的优化器——Neo(Neural Optimizer)。相比ReJOIN[3], Neo不仅解决Join order,同时还完成物理算子的选择, 是第一个端到端的基于学习的优化器。其设计思想如下。
建模:MDP
学习目标,即从一个部分计划开始,所能走到的执行时间最短的完整计划的执行时间。或者说,是指所有包含的完整计划的最短执行时间。也即RL中的术语“状态值”。
推理:如果学到了这个函数,显然就可以用它来进行搜索了!初始的计划为空,,即个树构成的森林,每个树只有一个结点,表示一个表,并且表的访问方式还没确定。我们可以遍历下的所有动作,选出下一个最好动作和相应的新状态。
显然,这是一个贪心的搜索。为了提高质量,使用Best-First-Search,如下。
最好最先搜索:维护一个优先队列,期望cost较小的Partial计划被放在前面。每次从堆中取出一个元素,扩展所有可能的动作,得到所有的计划,放到优先队列里,直至搜到完整计划。搜到完整计划后还可继续,搜多个完整计划,直至达到TimeOut时间设定。
Neo展示了端到端的基于学习的优化器的可能性。
Balsa [5]
Balsa的贡献在于,证实了不利用一个现有的专家优化器,只通过基于学习的办法得到一个优化器,是可能的而且可以做到很有效。用RL的方法来学习查询优化,一个明显的问题是计划空间中有大量的坏查询,在训练的初期,可能会阻碍学习进展。为此,本文用如下方案来解决:
Bootstrap,也即Simulation,先用一个模拟器来模拟不同计划的cost,而不是真正的执行这个计划。可以用一个Cardinality Estimator进行模拟,用基数来作为cost。这是最简单的环境模拟,最简单的cost model,不依赖于任何执行引擎。能够帮助Agent在训练早期尽可能避免坏查询。 Safely Execute:引入timeout,避免坏计划阻碍学习的进行。timeout根据该查询当前已知的最快执行时间来设定。 Safely Explore:随机探索会探索到坏计划,阻碍学习,应该思考怎样从“很可能不错但未探索”的计划进行探索。具体方法为 beam-search
并得到top-K计划,从中选择探索最少的。
本文的优化器Balsa的命名也正是"Bootstrap, Safely Execute, Safely Explore"中的相应字母。
思路3:结合基于学习的方法与传统方法
传统优化器虽然偶尔会产生糟糕的计划,但大多数时候表现足够好,并且传统优化器中凝聚了大量的人类智慧。如何利用基于学习的方法,并将传统优化器具有的知识利用起来,是这类方法的着眼点。比如,让基于学习的方法为传统优化器提供提示(query hint),再让传统优化器根据这个提示生成完整的计划。一方面,好的提示能防止传统优化器生成坏的计划,提供了改进计划质量的可能性;另一方面,不太好的提示,又有传统优化器“兜底”,能保证计划还不错。Bao[6]正是基于这个思想。
Bao [6]
本文是MIT团队发表在SIGMOD的工作,荣获SIGMOD 2021的Best Paper。本文中介绍了Bao(the Bandit optimizer),能够建立在一个已有的优化器之上,以一种插件的形式,给优化器进行“提示”,以达到生成更好执行计划的效果。具体来说,Bao能够根据不同查询,给优化器不同的“提示”(如禁用Loop Join,使用Index Scan且Merge Join,等等),这些“提示”的约束下会限制只有若干种算子可用,让优化器生成更好的计划。当然了,可能的提示(Hint)只有有限个。
Bao利用优化器的基数估计和代价估计,而不需要用底层的数据作为输入,从而其设计天然的支持更新,支持工作负载以及底层数据的更新,支持Schema的改变。现实场景中,很多查询负载的执行时间服从长尾分布:“20%的查询占用了80%”的时间。本文实验表明,Bao能够极大的改善长尾分布的情况,很大程度上减少了坏计划的生成,从而加快慢查询,达到整个查询负载的性能提升。本文将Bao集成到PostgreSQL和一个商业数据库Comsys,都获得了显著的性能提升。
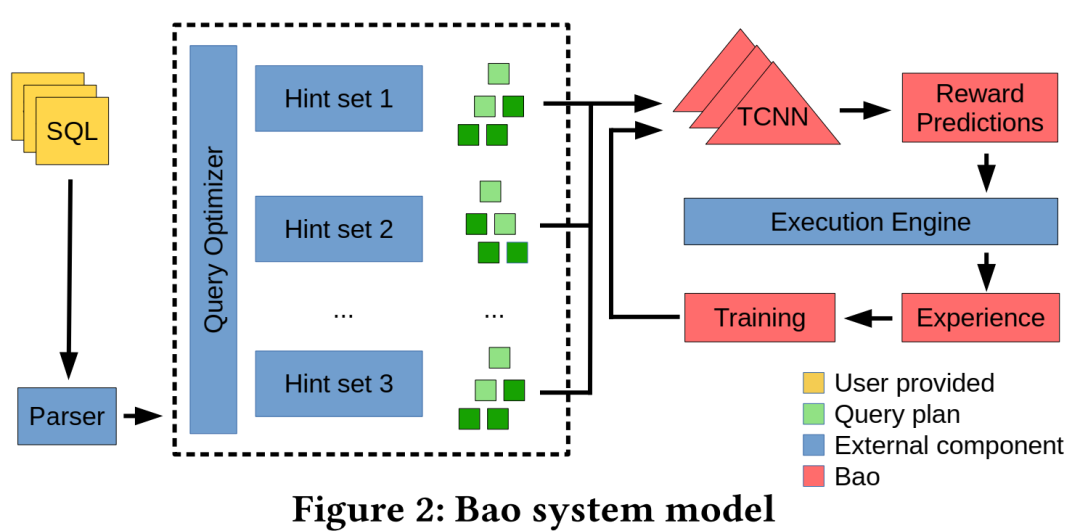
Bao的工作流如下:
生成n个执行计划:当用户发出一个SQL查询,Bao会调用宿主优化器,在n个提示集下,生成n个执行计划。 估计每个计划的执行时间:最终,每个计划是一个树形的执行树,每个结点会附带encode feature。这些计划会通过Bao的树形卷积网络,来预测实际执行代价。计划的生成,以及计划执行时间的预测都是可用并行的。 选择一个计划并执行:Bao从n个计划中选出期望运行时间最小的,并运行,将运行结果加入到经验集合(Experience,记作$E = \{ 迭代训练:每经过个查询,经验集合会增长个经验,期望更多的经验能产生更好的模型,因而此时模型会进行重训练,从而迭代。考虑到平衡探索和利用,引入随机性,不是直接训练期望模型,而是利用Thompson sampling来从中采样模型参数。实际怎么做呢?从中采样个样本训练,这样就随机了。实际考虑训练时间,可以只采样个而不是个。
- HybridQO [7]
本文提出了一种混合优化器,
先结合传统方法和学习方法生成一批高质量的候选计划 再用一个uncertainty-aware的model来预测执行时间,选出执行时间最短的计划
实验结果表明,在JOB数据集,相比于postgreSQL,总执行时间减少25%,tail latency减少65%。
系统架构
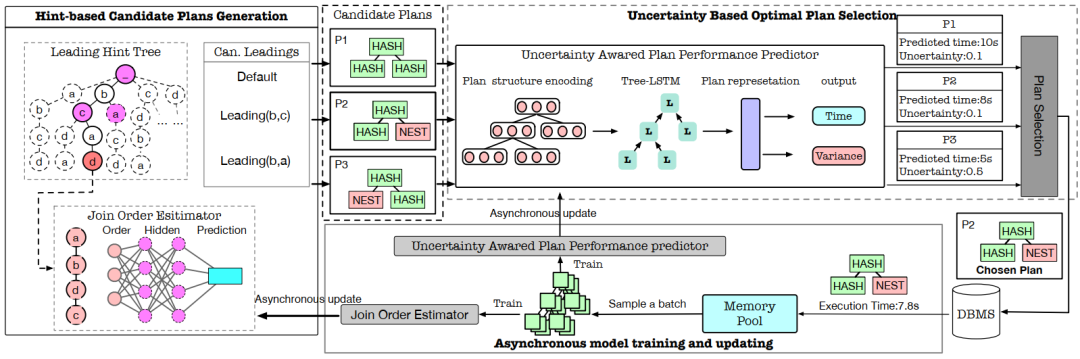
Hint-based Candidate Plans Generation: 在Leading Hint Tree上做MCTS搜索,叶子结点对应一个完整Join Order,用一个LSTM评估这个Join Order作为Reward。最终,从树上选择H个最好的长度为L的hint,生成H个计划。 Uncertainty Based Optimal Plan Selection:预测H个计划的执行时间,以及不确定性。只保留不确定性低于阈值的计划。选出预测时间最短的。如果所有计划的不确定性都高于阈值,采用传统CBO计划。
LOGER [8]
本文提了的优化器LOGER(a learned optimizer towards generating efficient and robust plans),其特点在于机器学习方法与传统优化器的结合:机器学习的部分负责确定Join Order,并对每个Join算子做限制(如禁用Merge Join、禁用Hash Join等),最终再由传统优化器“拍板”,确定每个连接具体应该使用哪个物理算子。二者协同,最终完成查询计划的生成。
概念:ROSS。本文中,由基于学习的方法生成的计划,不必确认具体的物理算子,只要给出算子限制即可。本文将这个搜索空间叫做ROSS(Restricted Operator Search Space)。在每一步,优化器需要选择两个子计划,用一个Restricted Operator连接起来。本文中有四种restricted operator,分别是:no restriction( )、no nested loop join()、no merge join()、no hash join()。相反,需要选出具体的物理算子的计划空间叫做DOSS(Direct Operator Search Space)。本文中LOGER的目标就是在ROSS中选出Join Order和Restricted Operator,形成一个计划树。
方法设计:LOGER还是将问题规约为一个MDP问题:初始状态为,所有表都没有Join。一个动作为,根据Join Predicate,将两个子计划连接起来。最终得到完整的计划。并运行该计划得到最终回报。正式的讲,
状态:,其中是一个表示连接计划的森林,表示每个连接算子的信息(限制)。 动作:选出中两棵树,用限制算子连接。 回报:该计划的执行时间与传统优化器生成的计划的执行时间的比值
神经网络的学习目标是动作值函数
如图展示了LOGER的总体架构。
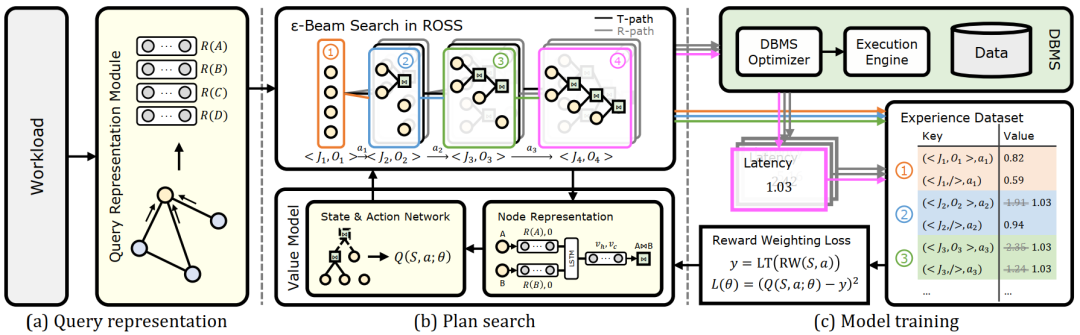
Query Representation:该模块用于将一个查询映射到向量空间,最终Join Graph的每个点(即每个表)获得一个向量表示,例如、、、。这些向量表示融合了表的统计信息、谓词的选择度,并使用了Graph Transformer,更进一步融合Join Graph的图结构信息。该模块的详细介绍后续讨论。
Plan Search:神经网络计算了动作值,如何用其来搜索出比较好的完整计划呢?作者在普通的Beam Search上引入了随机,提出了ε-beam search,能够更好的平衡探索和利用。
总结
现有的工作证实了利用机器学习的方法来改进查询优化器是可行的和有效的,为查询优化开辟了研究方向。这些工作也展示出基于学习的优化器的潜力:能够达到与传统方法可比的水平,甚至超越传统方法。
本文从三种角度对现有工作做了梳理:基于学习的优化器组件、端到端基于学习的优化器、结合基于学习的方法与传统方法。尽管其中一些方法可能还有比较多的局限,是机器学习做查询优化的探索性工作,但我们相信这是个可行的研究方向:未来的数据库会越来越智能,我们期待AI4DB领域更多的优秀的工作落地。
参考文献
[1] Ji Sun,Jintao Zhang,Zhaoyan Sun,Guoliang Li,Nan Tang. Learned Cardinality Estimation: A Design Space Exploration and A Comparative Evaluation. PVLDB, 15(1): 85 - 97, 2022. doi:10.14778/3485450.3485459
[2] Ji Sun, Guoliang Li. An End-to-End Learning-based Cost Estimator. PVLDB, 13(3): 307-319, 2019. DOI: https://doi.org/10.14778/3368289.3368296
[3] Ryan Marcus and Olga Papaemmanouil. 2018. Deep Reinforcement Learning for Join Order Enumeration. In aiDM’18: First International Workshop on Exploiting Artificial Intelligence Techniques for Data Management, June 10, 2018, Houston, TX, USA. ACM, New York, NY, USA, 4 pages. https://doi.org/10.1145/3211954.3211957
[4] Ryan Marcus, Parimarjan Negi, Hongzi Mao, Chi Zhang, Mohammad Alizadeh, Tim Kraska, Olga Papaemmanouil, Nesime Tatbul. Neo: A Learned Query Optimizer. PVLDB, 12(11): 1705-1718, 2019. DOI: https://doi.org/10.14778/3342263.3342644
[5] Zongheng Yang, Wei-Lin Chiang, Sifei Luan, Gautam Mittal, Michael Luo, and Ion Stoica. 2022. Balsa: Learning a Query Optimizer Without Expert Demonstrations. In Proceedings of the 2022 International Conference on Management of Data (SIGMOD ’22), June 12–17, 2022, Philadelphia, PA, USA. ACM, New York, NY, USA, 14 pages. https://doi.org/10.1145/3514221.3517885
[6] Ryan Marcus, Parimarjan Negi, Hongzi Mao, Nesime Tatbul, Mohammad Alizadeh, and Tim Kraska. 2021. Bao: Making Learned Query Optimization Practical. In Proceedings of the 2021 International Conference on Management of Data (SIGMOD ’21), June 20–25, 2021, Virtual Event, China. ACM, New York, NY, USA, 14 pages. https://doi.org/10.1145/3448016.3452838
[7] Xiang Yu, Chengliang Chai, Guoliang Li, and Jiabin Liu. Cost-based or Learning-based? A Hybrid Query Optimizer for Query Plan Selection. PVLDB, 15(13): 3924 - 3936, 2022. doi:10.14778/3565838.3565846
[8] Tianyi Chen, Jun Gao, Hedui Chen, and Yaofeng Tu. LOGER: A Learned Optimizer towards Generating Efficient and Robust Query Execution Plans. PVLDB, 16(7): 1777 - 1789, 2023. doi:10.14778/3587136.3587150


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

