




TiDB 备份之道:深入应用与实战解析 Dumpling 工具
一、Dumpling 工具简介
Dumpling是一款专为TiDB和MySQL设计的逻辑备份工具,它支持在不中断数据库服务的情况下进行全量逻辑导出。
功能特性:
- Dumpling可以将存储在TiDB或MySQL中的数据导出为SQL或CSV格式,用于逻辑全量备份。
- 它基于Go语言开发,具有简单易用、性能优越的特点。
- Dumpling采用了高效的并发处理机制,能够充分利用系统资源,加速数据导出的过程。
- 支持多种导出参数配置,如单个文件的最大行数(-r)和单个文件的最大大小(-F),以满足不同场景下的需求。
- 支持导出指定数据库或表的数据,提供了灵活的数据导出方式。
优势:
- 相较于传统的物理备份工具,Dumpling采用了逻辑备份的方式,导出的数据更为灵活和易于处理。
- Dumpling支持热备份,即在不中断数据库服务的情况下进行数据导出,保证了数据的完整性和一致性。
TiDB Dumpling作为TiDB生态中的重要工具之一,为数据库管理员和开发者提供了高效、灵活的数据备份和迁移方案。通过深入了解和掌握Dumpling的使用方法,可以更好地保障TiDB数据库的稳定性和数据安全性。
二、Dumpling 工具部署与使用
1、Dumpling 架构与特点
- 架构上Dumpling是一个客户端工具,连接到正在运行的TiDB数据库进行数据导出。
- Dumpling工具有如下特点:
1.支持导出多种数据形式, 包括SQL/CSV。
2.逻辑导出。
3.支持全新的表过滤和数据过滤(table-filter),筛选数据更加方便。
4.支持导出到Amazon S3 云盘。
5.针对TiDB 进行优化。
2、Dumpling 数据迁移工具特性
使用场景 | 用于将数据从MySQL/TiDB进行全量导出 |
|---|---|
上游 | MySQL,TiDB |
下游(输出文件) | SQL,CSV |
主要优势 |
|
使用限制 |
|
3、Dumpling 适用场景
- 导出数据量小于50G的场景。原因由于导出数据为SQL或者CSV,所以如果文件过大,导出导入成本会很高。
- 需要导出SQL语句或者CSV的场景,可以在异构数据库或者系统中进行迁移。
- 对于导出效率要求不高,由于需要读取数据和转换,所以比起物理导出效率低下。
4、Dumpling 不适用场景
Dumpling不适用于以下场景:
1.需要直接导出TiDB数据库中的原始数据SST(键值对)。
2.增量备份,目前只有全量导出,无法做到增量。
3.数据量大于50G,并且对于时间要求较高。原因由于导出数据为SQL或者CSV,所以如果文件过大,导出导入成本会很高。
5、Dumpling 的部署
Dumpling工具集成在tidb-toolkit中,官网下载地址:https://cn.pingcap.com/product-community/
此外在tidb-server中也有相关组件可以通过tiup安装
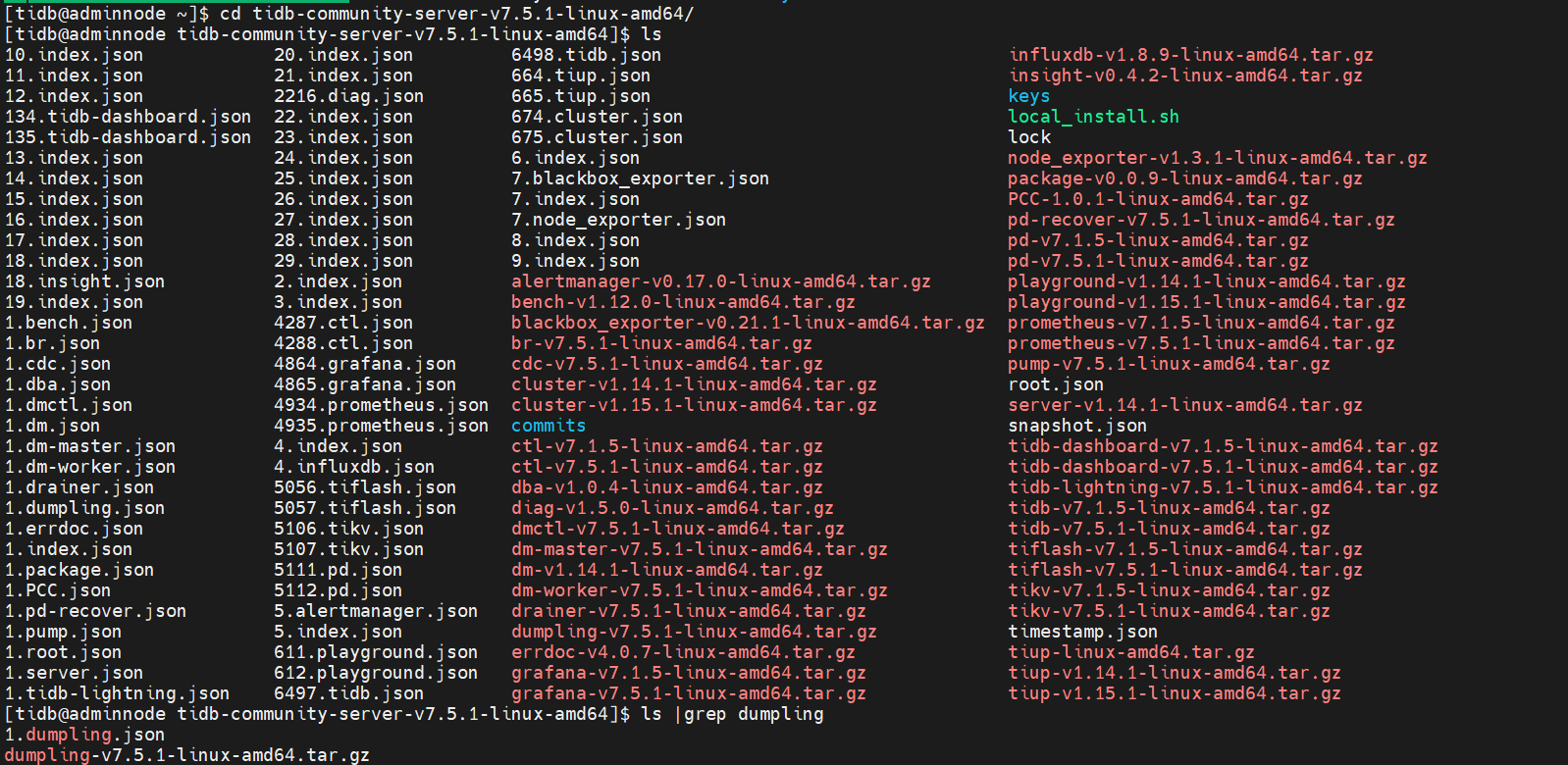
- 方式一、使用TiUP 执行tiup install dumpling 命令安装组件
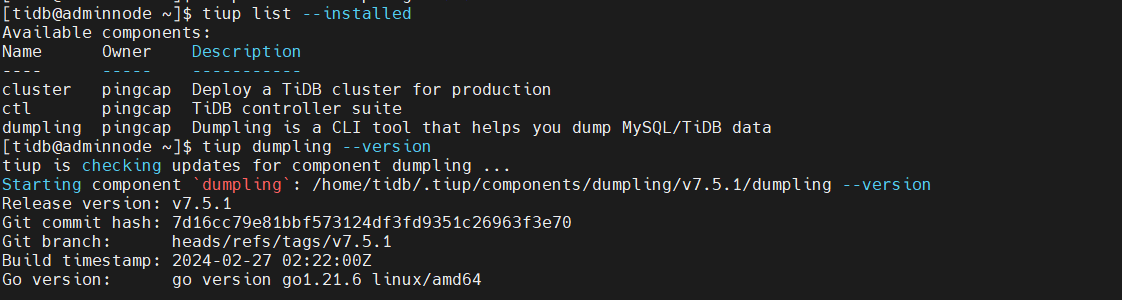
查看已安装的组件

查看能安装的组件
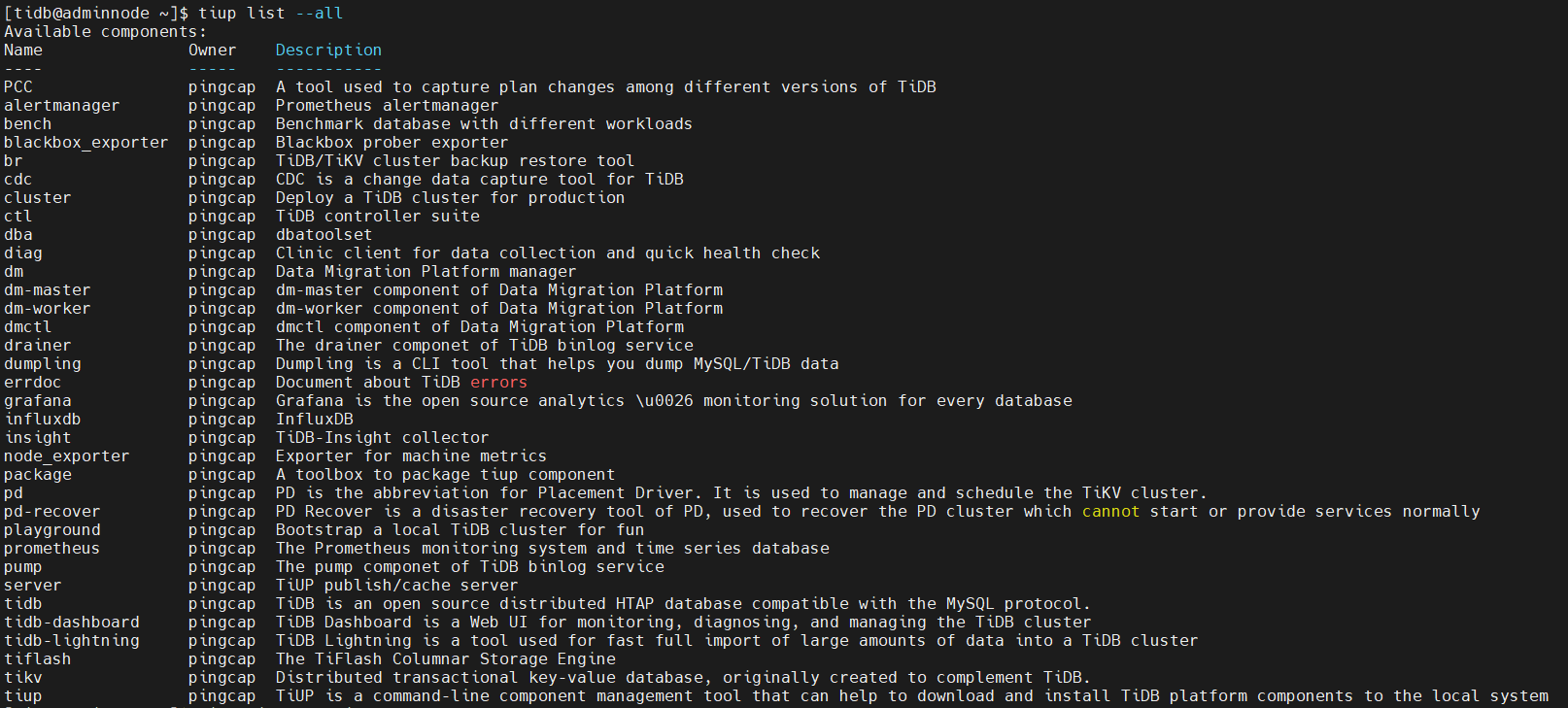
查看能安装的dumpling版本

安装dumpling组件

查看安装的信息
- 方式二、tidb-toolkit 安装包下载配置dumpling
下载相关toolkit工具包并配置环境变量
- 解压工具包
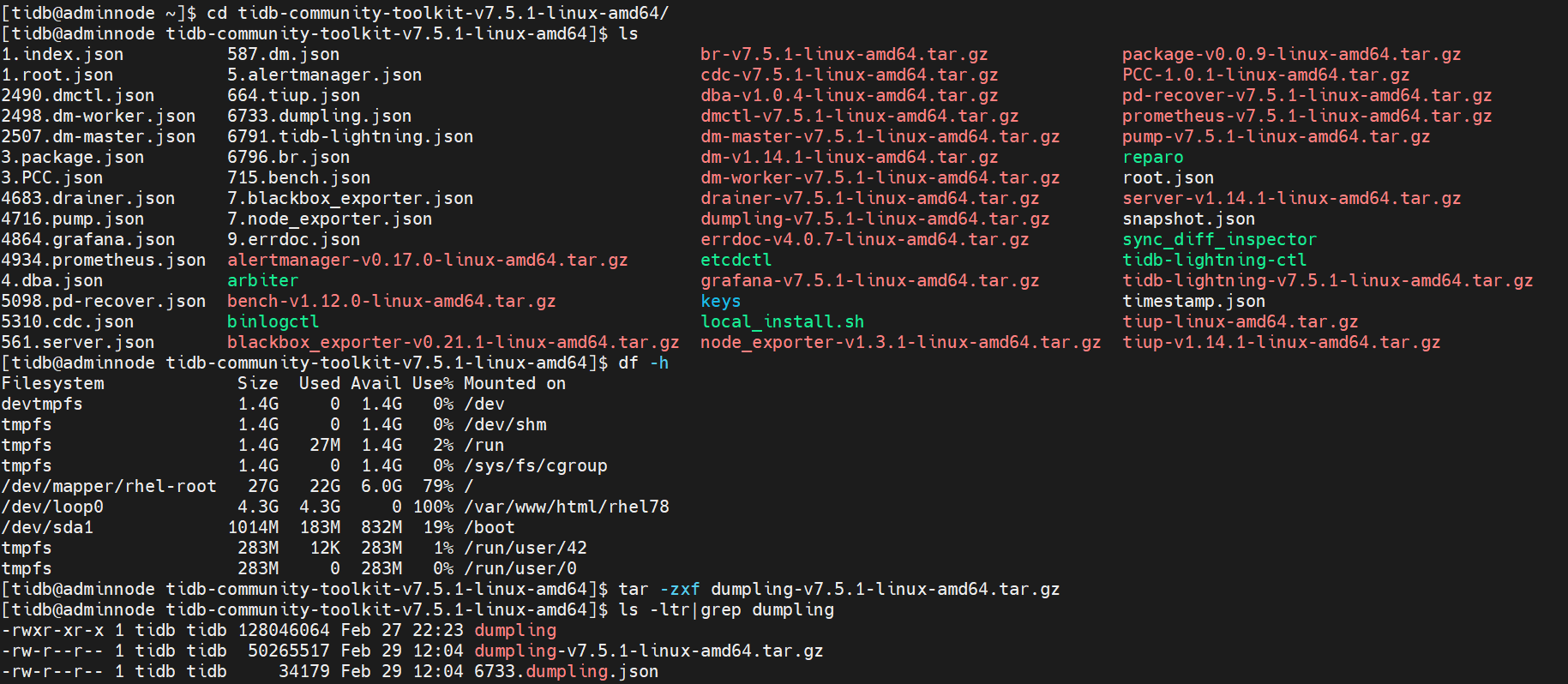
- 配置环境变量
$vi .bash_profile
添加如下:
export PATH=/home/tidb/.tiup/bin:$PATH:/usr/local/mysql/mysql-8.0/bin:/home/tidb/tidb-community-toolkit-v7.5.1-linux-amd64
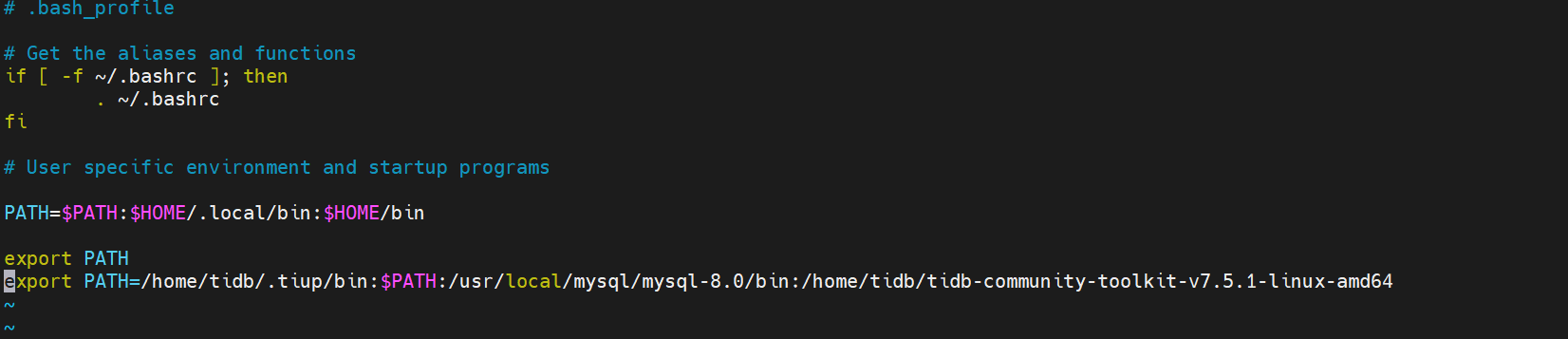
$source .bash_profile
- 查看dumpling版本信息

6、Dumpling 所需权限
最小权限要求:
- SELECT
- RELOAD
- LOCK TABLES
- REPLICATION CLIENT
- PROCESS
7、Dumpling 导出为 sql 文件
假设在 127.0.0.1:4000 有一个TiDB实例,并且这个TiDB实例中有无密码的 root 用户。
Dumpling 默认导出数据格式为SQL文件。也可以通过设置 --filetype sql 导出数据到SQL文件:
dumpling -u root -P 4000 -h 127.0.0.1 --filetype sql -t 8 -o /tmp/test -r 200000 -F 256MiB
以上命令中参数:
- -h、-P、-u 分别代表地址、端口、用户。如果需要密码验证,可以使用 -p $YOUR_SECRET_PASSWORD 将密码传给 Dumpling。
- -o(或 --output)用于选择存储导出文件的目录,支持本地文件的绝对路径或外部存储服务的 URI 格式。
- -t 用于指定导出的线程数。增加线程数会增加 Dumpling 并发度提高导出速度,但也会加大数据库内存消耗,因此不宜设置过大。一般不超过64。
- -r 用于开启表内并发加速导出。默认值是0,表示不开启。取值大于0表示开启,取值是 INT 类型。当数据源为 TiDB 时,设置 -r 参数大于0表示使用TiDB region信息划分区间,同时减少内存使用。具体取值不影响划分算法。对数据源为MySQL且表的主键是INT的场景,该参数也有表内并发效果。
- -F 选项用于指定单个文件的最大大小,单位为 MiB,可接受类似 5GiB 或 8KB 的输入。如果你想使用 TiDB Lightning 将该文件加载到 TiDB 实例中,建议将 -F 选项的值保持在256 MiB或以下。
注意:如果导出的单表大小超过 10 GB,强烈建议使用 -r 和 -F 参数。
举例如下:
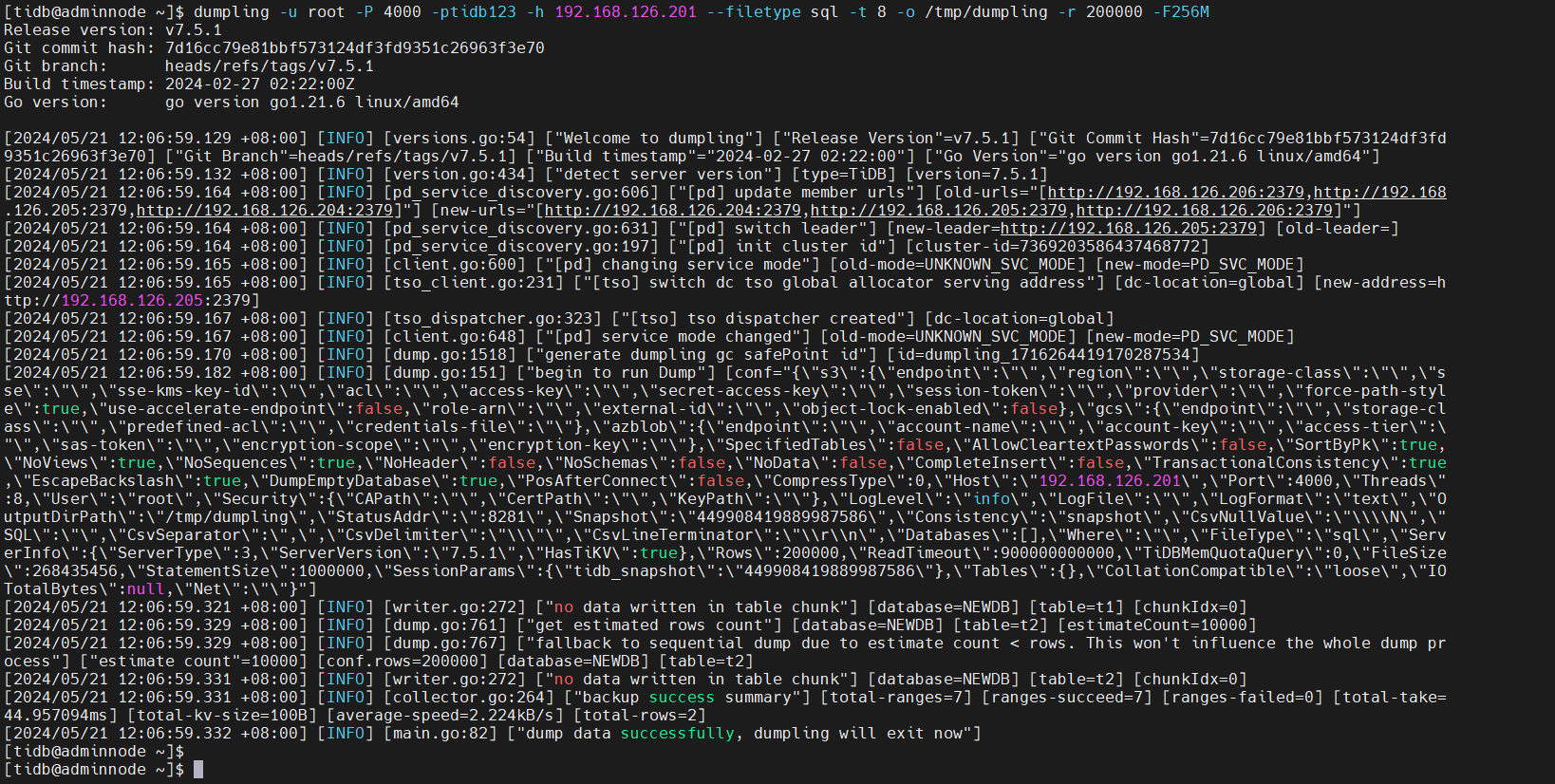
8、Dumpling 导出为 csv 文件
你可以通过使用 --filetype csv 导出数据到CSV文件。
当你导出CSV文件时,你可以使用 --sql <SQL> 导出指定SQL选择出来的记录。
例如,导出 test.sbtest1 中所有 id < 100 的记录:
./dumpling -u root -P 4000 -h 127.0.0.1 -o /tmp/test --filetype csv --sql 'select * from `test`.`sbtest1` where id < 100' -F 100MiB --output-filename-template 'test.sbtest1.{{.Index}}'
以上命令中:
- --sql 选项仅仅可用于导出 CSV 文件的场景。上述命令将在要导出的所有表上执行 SELECT * FROM <table-name> WHERE id < 100 语句。如果部分表没有指定的字段,那么导出会失败。
- 使用 --sql 配置导出时,Dumpling 无法获知导出的表库信息,此时可以使用 --output-filename-template 选项来指定 CSV 文件的文件名格式,以方便后续使用 TiDB Lightning 导入数据文件。 例如 --output-filename-template='test.sbtest1.{{.Index}}' 指定导出的CSV文件为 test.sbtest1.000000000、test.sbtest1.000000001 等。
- 你可以使用 --csv-separator、--csv-delimiter 等选项,配置 CSV 文件的格式。具体信息可查阅 Dumpling 主要选项表。
注意:Dumpling导出不区分字符串与关键字。如果导入的数据是Boolean类型的 true 和 false,导出时会被转换为 1 和 0。
举例如下:
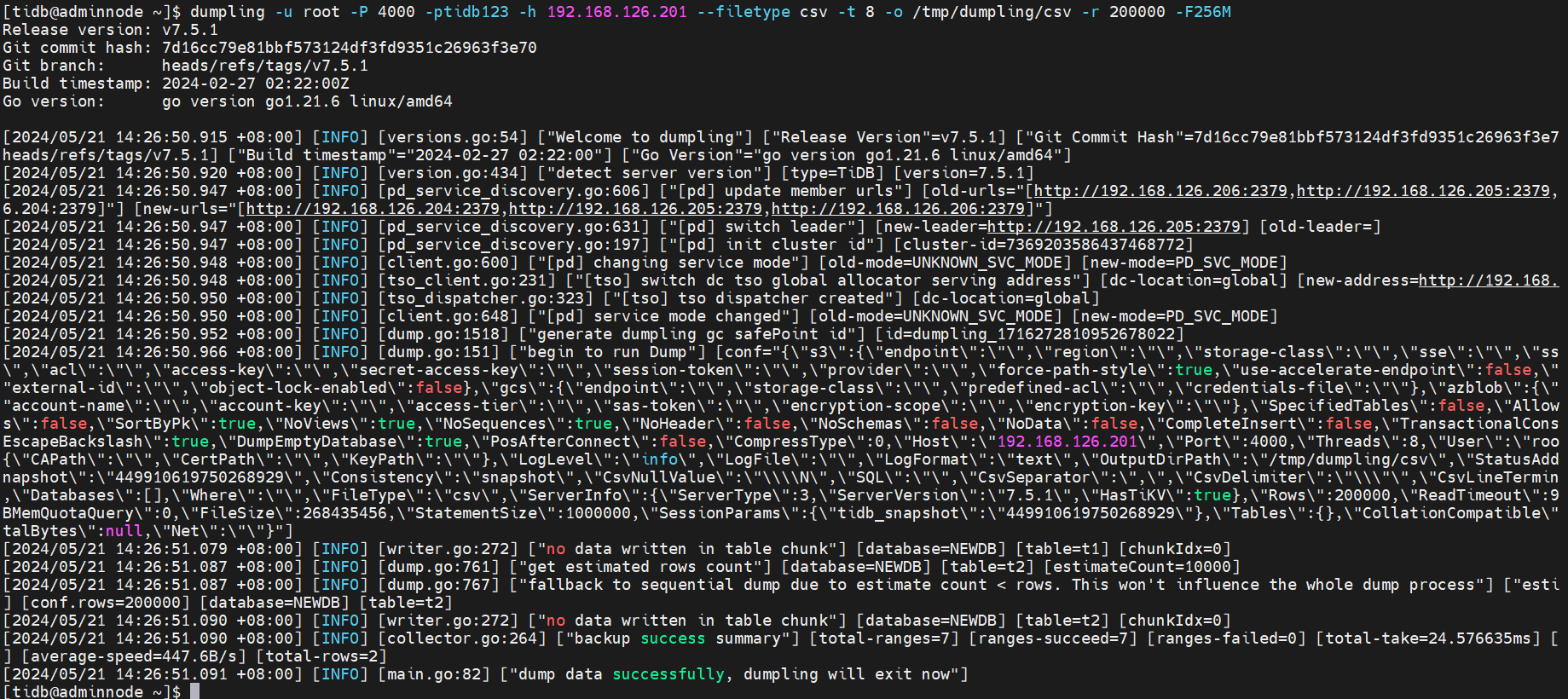
Dumpling参数还有-d可以只输出不导出数据,适用于只导出 schema 场景。-m 不导出 schema,只导出数据。详细的参数可以dumpling -h或者参考官方资料如下:
Dumpling 主要选项表:https://docs.pingcap.com/zh/tidb/stable/dumpling-overview
9、对导出数据进行筛选
1、使用--where 选项筛选数据
默认情况下,Dumpling会导出排除系统数据库(包括 mysql 、sys 、INFORMATION_SCHEMA 、PERFORMANCE_SCHEMA、METRICS_SCHEMA 和 INSPECTION_SCHEMA)外所有其他数据库。
你可以使用 --where <SQL where expression> 来指定要导出的记录。
./dumpling -u root -P 4000 -h 127.0.0.1 -o /tmp/test --where "id < 100"
上述命令将会导出各个表的 id < 100 的数据。注意 --where 参数无法与 --sql 一起使用。
2、使用--filter 选项筛选数据
Dumpling 可以通过 --filter 指定 table-filter 来筛选特定的库表。table-filter 的语法与 .gitignore 相似,详细语法参考表库过滤。
./dumpling -u root -P 4000 -h 127.0.0.1 -o /tmp/test -r 200000 --filter "employees.*" --filter "*.WorkOrder"
上述命令将会导出 employees 数据库的所有表,以及所有数据库中的 WorkOrder 表。
3、使用-B或-T 选项筛选数据
Dumpling 也可以通过 -B 或 -T 选项导出特定的数据库/数据表。
注意:
--filter 选项与 -T 选项不可同时使用。
-T 选项只能接受完整的 库名.表名 形式,不支持只指定表名。例:Dumpling 无法识别 -T WorkOrder。
例如通过指定:
-B employees导出employees 数据库
-T employees. WorkOrder导出employees. WorkOrder数据表
10、导出数据的格式内容
1、metadata: 此文件包含导出的起始时间, 以及 master binary log 的位置。
cat metadata
Started dump at: 2020-11-10 10:40:19
SHOW MASTER STATUS:
Log: tidb-binlog
Pos: 420747102018863124
Finished dump at: 2020-11-10 10:40:20
2、{schema}-schema-create. sql: 创建 schema 的SQL 文件。
cat {schema}-schema-create. sql
CREATE DATABASE `test` /*!40100 DEFAULT CHARACTER SET utf8mb4 */;
3、{schema}.{table}-schema. sql: 创建 table 的 SQL 文件
cat {schema}.{table}-schema. sql
CREATE TABLE 't1' (
`id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4 bin;
4、{schema}.{table}.{0001}.{sql|csv}: 数据源文件
/*!40101 SET NAMES binary*/;
INSERT INTO `t1` VALUES(1);
5、*-schema-view.sql、*-schema-trigger.sql、*-schema-post.sql:其他导出文件
举例如下:

11、导出数据的一致性
注意:数据一致性选项的默认值为 auto。在大多数场景下,你不需要调整该选项。
Dumpling 通过 --consistency <consistency level> 标志控制导出数据“一致性保证”的方式,默认是auto。
在使用snapshot来保证一致性的时候,可以使用 --snapshot 选项指定要备份的时间戳。还可以使用以下的一致性级别:
- flush:使用 FLUSH TABLES WITH READ LOCK 短暂地中断备份库的DML和DDL操作、保证备份连接的全局一致性和记录POS信息。所有的备份连接启动事务后释放该锁。推荐在业务低峰或者MySQL备份库上进行全量备份。
- snapshot:获取指定时间戳的一致性快照并导出。
- lock:为待导出的所有表上读锁。
- none:不做任何一致性保证。
- auto:对MySQL使用 flush,对TiDB使用 snapshot。
./dumpling --snapshot 417773951312461825 --设为 TSO(SHOW MASTER STATUS 输出的 Position 字段)
./dumpling --snapshot "2020-07-02 17:12:45" ---指定时间,数据被GC之前
12、Dumpling 性能优化
1.-t用于指定导出的线程数。增加线程数会增加Dumpling并发度提高导出速度,但也会加大数据库内存消耗,因此不宜设置过大。
2.-r选项用于指定单个文件的最大记录数(或者说,数据库中的行数) 。开启后Dumpling会开启表内并发,提高导出大表的速度。
