背景
在基于KingbaseES V8 的信息系统里面,随着业务增长,数据增加,翻过一页页的数据,总会遇到深分页问题,因为数据太多,标准的分页SQL查询速度越来越慢,最后KingbaseES V8 不胜负荷。
标准的分页SQL太坑 ,基于官网对 KingbaseES V8 加深认识,测试了下面5个深分页优化改造的语句,经测试前面可能有助于解决生产环境上的问题。
复现问题
drop table pageT;
#创建表
create table pageT( id int,t1 timestamp, prdid int, price float, prdName varchar(50), primary key(id) );
#插入5000万数据
insert into pageT(id,t1,prdid,price,prdName) select s.a,('2024-5-17 16:26:38.000000'::timestamp) +concat(s.a/10000,'s')::INTERVAL,s.a, random(),md5(random()::text) FROM generate_series(1, 50000000) AS s(a);
# 根据t1创建索引
king8=# create index pageT_t1_id_idx ON pageT (t1) ;
CREATE INDEX
# 标准SQL分页查询,查询100万数据
king8=# explain analyze select * from pageT order by t1 offset 1000000 limit 5;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
----------------------
Limit (cost=37408.26..37408.45 rows=5 width=53) (actual time=388.850..388.854 rows=5 loops=1)
-> Index Scan using pageT_t1_id_idx on pageT (cost=0.56..1870385.56 rows=50000000 width=53) (actual time=3.388..345.129
rows=1000005 loops=1)
Planning Time: 0.876 ms
Execution Time: 388.922 ms
(4 rows)
# 标准SQL分页查询,查询10000万数据
king8=# explain analyze select * from pageT order by t1 offset 10000000 limit 5;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
------------------------
Limit (cost=374077.57..374077.75 rows=5 width=53) (actual time=3634.972..3634.974 rows=5 loops=1)
-> Index Scan using pageT_t1_id_idx on pageT (cost=0.56..1870385.56 rows=50000000 width=53) (actual time=0.167..3110.737
rows=10000005 loops=1)
Planning Time: 0.179 ms
Execution Time: 3635.009 ms
(4 rows)
# 标准SQL分页查询,查询2000万数据
king8=# explain analyze select * from pageT order by t1 offset 20000000 limit 5;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
------------------------
Limit (cost=748154.56..748154.75 rows=5 width=53) (actual time=6786.113..6786.117 rows=5 loops=1)
-> Index Scan using pageT_t1_id_idx on pageT (cost=0.56..1870385.56 rows=50000000 width=53) (actual time=0.193..5741.663
rows=20000005 loops=1)
Planning Time: 0.177 ms
Execution Time: 6786.161 ms
(4 rows)
# 标准SQL分页查询,查询3000万数据
king8=# explain analyze select * from pageT order by t1 offset 30000000 limit 5;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
------------------------
Limit (cost=1122231.56..1122231.75 rows=5 width=53) (actual time=9800.186..9800.192 rows=5 loops=1)
-> Index Scan using pageT_t1_id_idx on pageT (cost=0.56..1870385.56 rows=50000000 width=53) (actual time=0.087..8261.063
rows=30000005 loops=1)
Planning Time: 0.105 ms
Execution Time: 9800.250 ms
(4 rows)
# 标准SQL分页查询,查询3500万数据
king8=# explain analyze select * from pageT order by t1 offset 35000000 limit 5;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
------------------------
Limit (cost=1309270.06..1309270.25 rows=5 width=53) (actual time=11140.914..11140.918 rows=5 loops=1)
-> Index Scan using pageT_t1_id_idx on pageT (cost=0.56..1870385.56 rows=50000000 width=53) (actual time=0.171..9270.387
rows=35000005 loops=1)
Planning Time: 0.169 ms
Execution Time: 11140.960 ms
(4 rows)
# 标准SQL分页查询,查询4000万数据
king8=# explain analyze select * from pageT order by t1 offset 40000000 limit 5;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
-------------------------
Limit (cost=1496308.56..1496308.75 rows=5 width=53) (actual time=12416.274..12416.278 rows=5 loops=1)
-> Index Scan using pageT_t1_id_idx on pageT (cost=0.56..1870385.56 rows=50000000 width=53) (actual time=0.098..10262.56
2 rows=40000005 loops=1)
Planning Time: 0.271 ms
Execution Time: 12416.313 ms
(4 rows)
根因分析
select * from pageT order by t1 offset 查询记录 limit 返回记录;
标准SQL分页查询原因是LIMIT语句会先获取符合条件的offset+n行数据,然后再丢弃掉前offset行,返回后n行数据。也就是说limit 10000,10,就会扫描100010行,而limit 0,10,只扫描10行。随着查询记录增多,花费的时间也增多。
经过实验测试,从100万的388.922 ms到1000万的 3635.009 ms,再到2000万的6786.161 ms,3000万的9800.250 ms, 最后3500万的11140.960 ms,4000万的12416.313 ms,标准SQL分页查询不适用于生产环境。
以4000万数据为基准,对分页SQL进行加工改造重构,使之查询性能能够符生产环境的响应需求。经过测试,可以通过游标、索引、wtih语句达到性能优化的目的。
SQL语句重构
添加游标
#定义一个游标,游标指向4千万数据位置, 此法 初始化耗费较多的时间,游标会占有大量资源,但是后期移动游标重定向相关数据非常迅速。
king8=# begin;
king8=# DECLARE c SCROLL CURSOR WITH HOLD FOR
king8-# select * from pageT order by t1 ;
DECLARE CURSOR
Time: 1.330 ms
king8=# MOVE ABSOLUTE 40000000 IN c;
MOVE 1
Time: 12177.204 ms (00:12.177)
king8=# FETCH 5 FROM c;
40000001 | 2024-05-17 17:33:18 | 40000001 | 0.37001383 | 1147823a1f390eb1ae06ee2fa4b85569
40000002 | 2024-05-17 17:33:18 | 40000002 | 0.12508851 | c7a495986f09a879c68066a365f30a73
40000003 | 2024-05-17 17:33:18 | 40000003 | 0.7382892 | ed6393332141722075dcd37340a6fcab
40000004 | 2024-05-17 17:33:18 | 40000004 | 0.9076735 | a9c8b8c0c1aa7478a92e442101685588
40000005 | 2024-05-17 17:33:18 | 40000005 | 0.8114186 | 2c06b862775b275e2e13e755a28f0efe
Time: 0.782 ms
king8=#
king8=# FETCH 5 FROM c;
40000006 | 2024-05-17 17:33:18 | 40000006 | 0.17201534 | fc3b46a7284cb1500ed113f68f7b50cc
40000007 | 2024-05-17 17:33:18 | 40000007 | 0.46472174 | 61a1c636827848f1640b8d5a5c38b608
40000008 | 2024-05-17 17:33:18 | 40000008 | 0.57982343 | 5362999f5042e5ba8c5f17f5922453d8
40000009 | 2024-05-17 17:33:18 | 40000009 | 0.5763288 | 8d8ea4ff4acc48e0fd29d93985098a89
40000010 | 2024-05-17 17:33:18 | 40000010 | 0.22719811 | 2b38272842cdbbe7085e71fd012282c4
Time: 1.623 ms
king8=# close c;
CLOSE CURSOR
Time: 1.823 ms
添加索引
# 大从都会用的做法,数据库的基本能力,将页码、页记录写入索引,通过范围查询提高性能,此法需要多了解业务,根据业务构造相关SQL
create index pageT_prd_id_idx ON pageT (prdid) ;
king8=# select * from pageT where prdid >40000000 and prdid <= 40000005 order by t1 ;
id | t1 | prdid | price | prdName
----------+---------------------+----------+------------+----------------------------------
40000001 | 2024-05-17 17:33:18 | 40000001 | 0.37001383 | 1147823a1f390eb1ae06ee2fa4b85569
40000002 | 2024-05-17 17:33:18 | 40000002 | 0.12508851 | c7a495986f09a879c68066a365f30a73
40000003 | 2024-05-17 17:33:18 | 40000003 | 0.7382892 | ed6393332141722075dcd37340a6fcab
40000004 | 2024-05-17 17:33:18 | 40000004 | 0.9076735 | a9c8b8c0c1aa7478a92e442101685588
40000005 | 2024-05-17 17:33:18 | 40000005 | 0.8114186 | 2c06b862775b275e2e13e755a28f0efe
(5 rows)
Time: 12.097 ms
添加with
# 通过with 查出查询页记录的边界范围 ,避开全表扫描,此举SQL较复杂
king8=# with t1 as (
king8(# select * from pageT as p where prdid > 40000000
king8(# )
king8-# select * from t1 limit 5;
id | t1 | prdid | price | prdName
----------+---------------------+----------+------------+----------------------------------
40000001 | 2024-05-17 17:33:18 | 40000001 | 0.37001383 | 1147823a1f390eb1ae06ee2fa4b85569
40000002 | 2024-05-17 17:33:18 | 40000002 | 0.12508851 | c7a495986f09a879c68066a365f30a73
40000003 | 2024-05-17 17:33:18 | 40000003 | 0.7382892 | ed6393332141722075dcd37340a6fcab
40000004 | 2024-05-17 17:33:18 | 40000004 | 0.9076735 | a9c8b8c0c1aa7478a92e442101685588
40000005 | 2024-05-17 17:33:18 | 40000005 | 0.8114186 | 2c06b862775b275e2e13e755a28f0efe
(5 rows)
Time: 1.166 ms
king8=# with recursive t2 as (
king8(# select * from pageT as p where prdid = 40000000
king8(# union all
king8(# select * from pageT as p where prdid > 40000000
king8(#
king8(# )
king8-# select * from t2 limit 5;
id | t1 | prdid | price | prdName
----------+---------------------+----------+------------+----------------------------------
40000000 | 2024-05-17 17:33:18 | 40000000 | 0.46968618 | 9c748418777134f8bef66082bf98885f
40000001 | 2024-05-17 17:33:18 | 40000001 | 0.37001383 | 1147823a1f390eb1ae06ee2fa4b85569
40000002 | 2024-05-17 17:33:18 | 40000002 | 0.12508851 | c7a495986f09a879c68066a365f30a73
40000003 | 2024-05-17 17:33:18 | 40000003 | 0.7382892 | ed6393332141722075dcd37340a6fcab
40000004 | 2024-05-17 17:33:18 | 40000004 | 0.9076735 | a9c8b8c0c1aa7478a92e442101685588
(5 rows)
Time: 2.257 ms
ALTER TABLE pageT ADD COLUMN page_id BIGINT NOT NULL DEFAULT nextval('page_sequence');
CREATE INDEX idx_page_id ON pageT(page_id);
king8=# ALTER TABLE pageT ADD COLUMN page_id BIGINT NOT NULL DEFAULT nextval('page_sequence');
ALTER TABLE
Time: 318388.827 ms (05:18.389)
SELECT * FROM pageT
WHERE page_id BETWEEN (page_size * (current_page - 1)) + 1
AND page_size * current_page
ORDER BY t1;
SELECT * FROM pageT
WHERE page_id BETWEEN 40000000
AND 40000005
ORDER BY t1;
SELECT * FROM pageT
WHERE prdid BETWEEN 40000000
AND 40000005
ORDER BY t1;
其它查询方法
除了游标、索引、with方法,笔者还验证网上介绍的覆盖索引、with方法子索引,但是这两个查询效果不如人意
覆盖索引
#构建覆盖索引
king8=# CREATE INDEX pageT_t1_id_idx ON public.pageT USING btree (t1,prdid);
CREATE INDEX
Time: 43859.306 ms (00:43.859)
# 这样已经是二元计算了,两表关联还拿了Nested Loop
king8=# select * from pageT a join (select p.prdid from pageT as p where prdid > 40000000) b on a.prdid = b.prdid order by a.t1 limit 5;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------
---------------------
Limit (cost=1.13..161.90 rows=5 width=12) (actual time=45254.518..45254.547 rows=5 loops=1)
-> Nested Loop (cost=1.13..320403696.38 rows=9964717 width=12) (actual time=45254.516..45254.542 rows=5 loops=1)
-> Index Only Scan using pageT_t1_id_idx on pageT a (cost=0.56..54936656.38 rows=50000000 width=12) (actual time=0.060..22824.959 ro
ws=40000005 loops=1)
Heap Fetches: 40000005
-> Index Only Scan using pageT_prd_id_idx on pageT p (cost=0.56..5.30 rows=1 width=4) (actual time=0.000..0.000 rows=0 loops=4000000
5)
Index Cond: ((prdid = a.prdid) AND (prdid > 40000000))
Heap Fetches: 5
Planning Time: 0.854 ms
Execution Time: 45254.617 ms
(9 rows)
with方法子查询
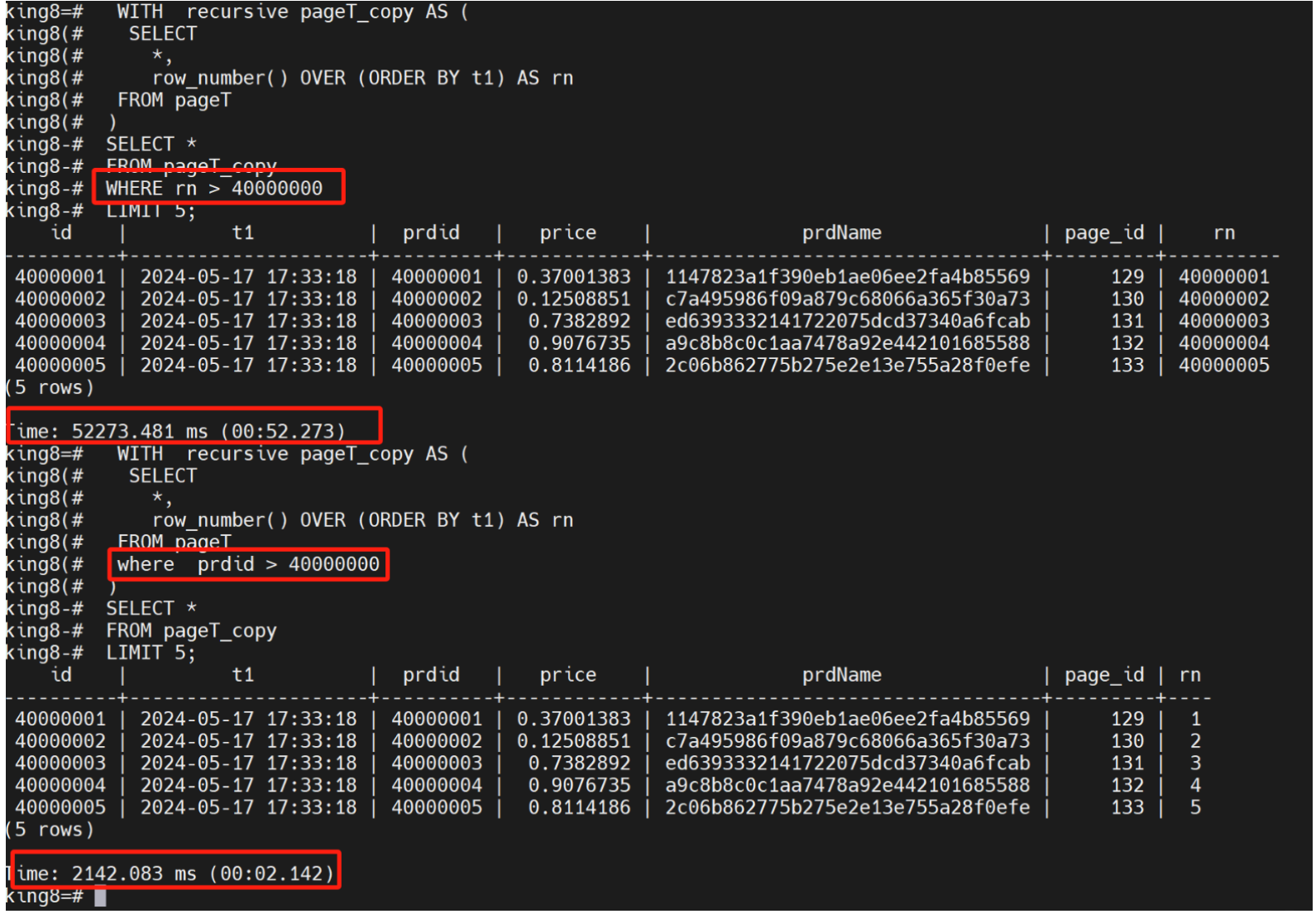
# 该方法建立一个子查询,由于子查询没有索引【rn不是索引】,还是要耗费大量的时候
king8=# explain analyze WITH recursive pageT_copy AS (
king8(# SELECT
king8(# *,
king8(# row_number() OVER (ORDER BY t1) AS rn
king8(# FROM pageT
king8(# )
king8-# SELECT *
king8-# FROM pageT_copy
king8-# WHERE rn > 40000000
king8-# LIMIT 5;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------
--------------------
Limit (cost=0.56..9.81 rows=5 width=61) (actual time=60030.415..60030.419 rows=5 loops=1)
-> Subquery Scan on pageT_copy (cost=0.56..30829874.88 rows=16666667 width=61) (actual time=60030.414..60030.416 rows=5 loops=1)
Filter: (pageT_copy.rn > 40000000)
Rows Removed by Filter: 40000000
-> WindowAgg (cost=0.56..30204874.88 rows=50000000 width=61) (actual time=4.445..55562.036 rows=40000005 loops=1)
-> Index Scan using pageT_t1_id_idx on pageT (cost=0.56..29454874.88 rows=50000000 width=53) (actual time=0.149..21638.113 row
s=40005000 loops=1)
Planning Time: 0.156 ms
Execution Time: 60030.554 ms
(8 rows)
Time: 60033.054 ms (01:00.033)
深分页总结
标准的offset limit翻页越多,性能越差,唯一的好处,就是书写简单。不适合在生产业务场 景
游标固然可以提速深分页,但是杀敌一千,自伤八百,深分页多发生在WEB应用开发,使用游标需要占有大量资源,同时也要考虑释放资源,游标还是使用在AP数据分析的场景较合适。
索引有助于解决深分页,使用索引后会产生大量的空间,注意后续维护工作要对碎片 进行清理,否则查询性能会越来越慢 ,建立围绕页码、页记录的相关索引是标准解决深分页的方式。
添加with在本质也是在索引的基础上,通过 with加载数据入临时段,可以更丰富分页的不同需求。这样可以完成深分页的复杂功能需求。
覆盖索引和with方法子查询 慢的原因在于覆盖索引用了两表关联,又因为数据大跑了嵌套连接,所以查询 慢,而with方法子查询,临时数据集没有索引,因此查询就降低了。把过滤查询的条件换个地方 就提升性能了,如下。