




背景
纵观数据库领域数十年来的发展,关系型数据库脱颖而出的一个重要原因是,它支持用户灵活地定义和修改“数据模型”。PolarDB-X 作为一款云原生关系型数据库,同样支持通过各种 DDL 语句对数据模型进行修改,以满足用户业务的不断发展,例如:可以使用 ALTER TABLE 语句对表进行添加列,删除列,修改列类型等操作。然而,PolarDB-X 作为一款分布式数据库,其一张逻辑表通常通过某种分区方式将数据划分成多个分片(又称为物理表),并且这些分片分布在不同的数据节点中[1][2],这使得 DDL 语句的实现会更加复杂。
本文以列类型变更为例,简单介绍在 PolarDB-X 中如何执行 ALTER TABLE 语句。首先,列类型变更分为两种:一种是变更分区键列类型,另一种是变更非分区键列类型。对于非分区键的列类型变更,可以直接将逻辑 DDL 拆分成多个物理 DDL,直接下推到对应分片上执行;对于分区键的列类型变更,则相对复杂,在修改列类型的同时,还需要对数据进行重分布,因为分区键列类型修改会影响到分片的路由,如果只是简单的下推执行,会导致使用分区键进行查询时,查询不到数据。实际上,作为一款分布式数据库,变更表的列类型,无论变更的是不是分区键,都需要保证各个分片以及元数据的一致性,因此对于非分区键的列类型变更也不只是简简单单的下推执行就可以的,后续会有专门的文章做详细的阐述,而本文主要阐述的是如何对分区键的列类型做变更。
传统实现
传统分布式数据库中间件采用分库分表的方式对表进行拆分,通常是不允许对拆分键列类型进行变更,如果想要做变更,一般需要重新建一张表,并且停写之后重新导入数据。如果想要变更的时候不停写,则需要在导入存量数据的同时,自行维护一套双写的逻辑,例如,在业务应用层实现双写、数据库触发器双写或者使用 binlog 同步增量数据等。在分布式系统中,这种操作方式不仅十分复杂,而且双写过程中的数据一致性难以保证,也很难校验结果的正确性,最终很容易导致数据不一致的问题。
PolarDB-X 实现
在前文中介绍了PolarDB-X拆分规则变更的实现原理[3],该变更过程同样需要对数据进行重分布。作为数据重分布的经典案例,拆分规则变更过程需经历建新表、双写、导入存量数据、数据校验、流量切换等步骤,并通过基于 TSO 的分布式事务来保证数据的一致性,整个流程已经非常成熟,建议没看过的同学可以先看一遍这篇文章以及 Online Schema Change 论文[4]。
变更分区键列类型和拆分规则变更一样都需要对数据进行重分布,那么变更分区键列类型可以同样基于拆分规则变更的流程来完成吗?需要考虑哪些方面?
了解过 pt-osc 以及 gh-ost 等 DDL 工具的小伙伴应该知道,这些工具便是通过建新表然后导入数据的方式实现表结构变更的。在 PolarDB-X 中,变更分区键列类型同样可以通过类似数据重分布的方式完成,但是需要额外考虑以下几点内容:
- 修改分区键列类型,新表的表结构会与源表不同,存量数据和增量数据导入存在类型转换,如何保证分区路由的正确性;
- 如何保证最终结果与 MySQL 修改列类型转换结果一致,以及如何进行数据校验;
- 如果需要变更的表上存在全局二级该如何处理;
- 修改拆分键列类型一定会影响路由吗?一定需要建的新表吗?
下面将分几个小节,依次解答上述问题。
创建新表与数据导入
对于拆分规则变更而言,该功能只会修改分区规则,并不会修改列定义,因此新建表的表结构与原表完全一致,列定义不会做修改。而分区键列类型变更需要修改分区键的列定义,因此新建表的表结构与原表不完全一致。
因为新表的列定义与原表的列定义不一致,所以原有的增量数据双写以及存量数据同步流程写入的数据都存在类型隐式转换,那么隐式转换不会不会影响结果的准确性?在一般情况下是不会影响的,原因有以下两点:
- 对于分区键而言,在 CN(计算节点)上兼容了 DN(数据节点)的类型隐式转换,就算数据写入时发生隐式类型转换或者数据截断等问题,也能够保证使用隐式转换前的数据和隐式转换后的数据都可以路由到同一个分片中,不需要担心路由问题;
- 熟悉 MySQL 的同学可能知道在 MySQL 中,ALTER TABLE MODIFY COLUMN 的类型转换和 DML 隐式类型转换使用的是一样的函数,因此存量数据和增量数据写入后的结果理论上跟 MySQL 上直接修改列类型转换的结果一致,这也是变更分区键列类型最重要的理论依据。
值得注意的是,第二点分析中存在一个前提条件,那就是 DML 需要严格按照源表的类型进行写入,否则不能严格保证双写时隐式转换结果的准确性。例如,原类型是 VARCHAR 类型,需要变更为 INT 类型,用户一直使用 binary 方式对该字段进行写入,假如用户写入的数据 x'61',对应字符 'a',那么对于 VARCHAR 类型来说,写入的就是字符 'a';但是对于 INT 类型,写入的却是 97,显然不是字符 'a' 转换成 INT 对应的数值,正确的数值应该是 0 。因此,对最终结果进行数据校验是非常有必要的。
数据校验
为了保证变更的正确性,在创建新表、开启增量数据双写以及存量数据同步都完成之后,需要穿插一个物理数据校验步骤,数据校验通过之后,才是流量切换以及原表优雅下线过程。这里先简单介绍一下数据校验的逻辑,首先我们在 DN 端实现了一种顺序无关的哈希算法并将其封装称为 UDF,在 CN 开始进行校验时,首先利用 TSO 事务获取到源表和目标表的一致性快照[5],然后分别对源表和目标表对应的 DN 端每个分片进行全表的 hashcheck 计算(并行),并将结果拉取到 CN 节点汇总,计算出源表的 checksum 和目标表的 checksum,最后进行比较。
同构表(分片间并行):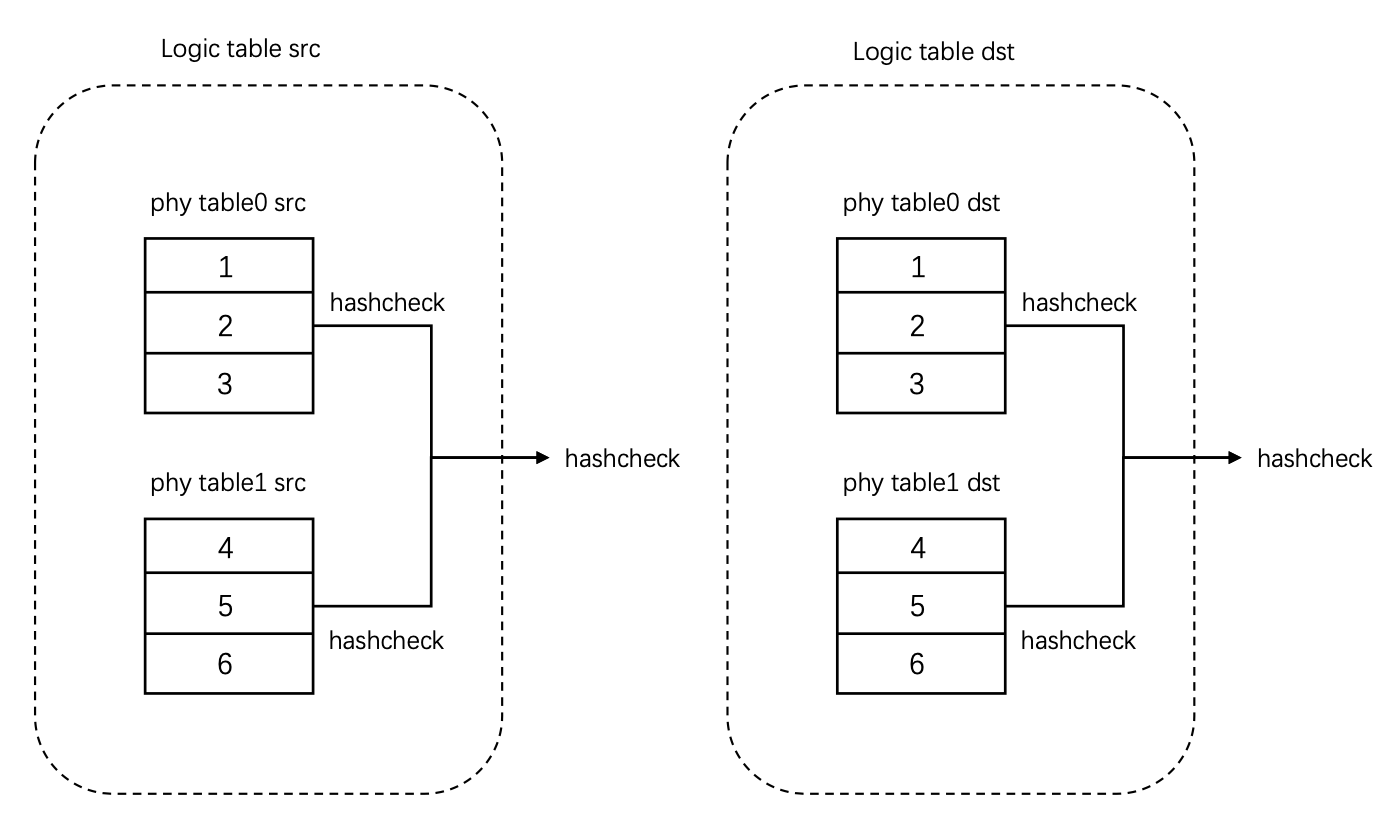
异构表(分片间并行):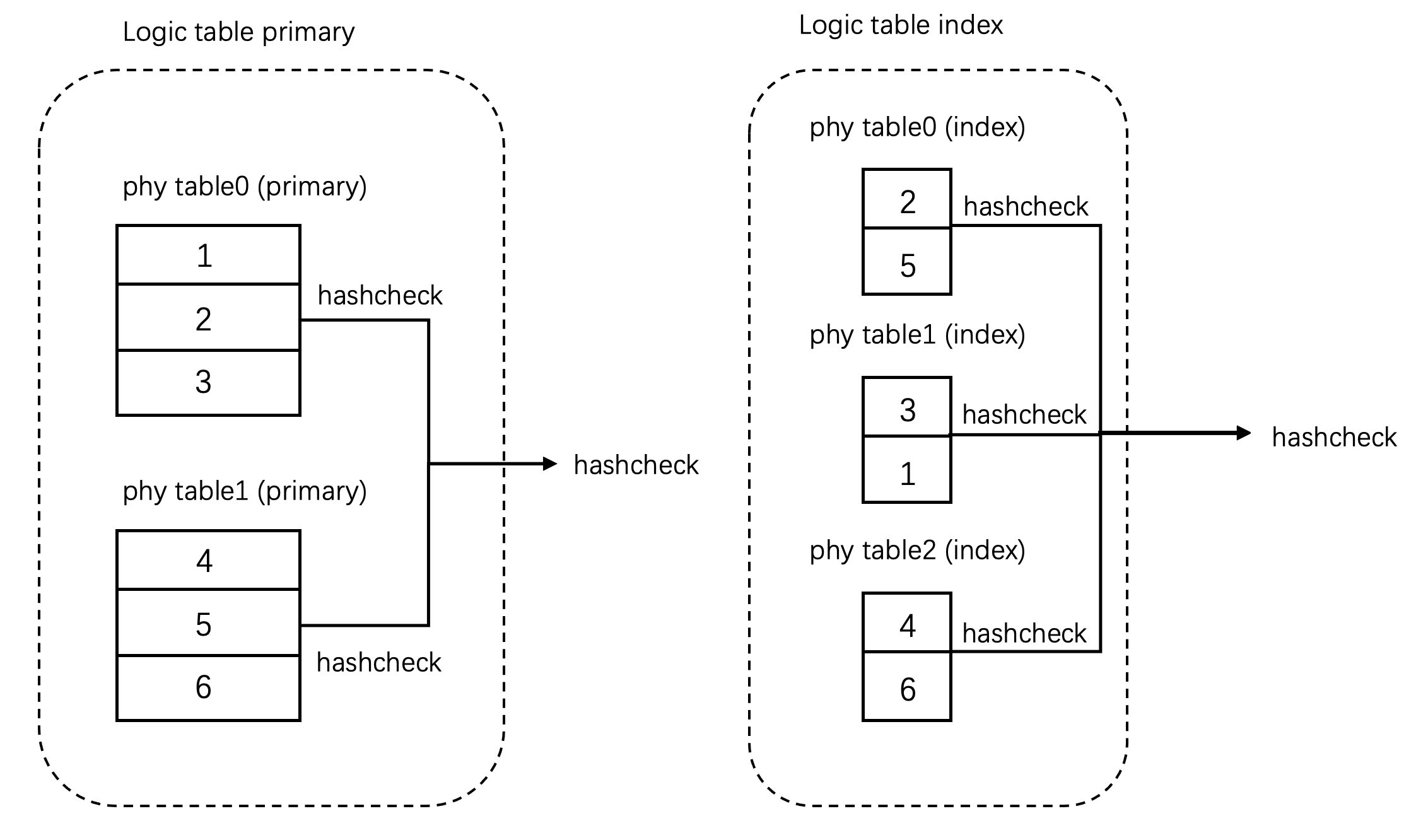
对于分区键列类型变更而言,分区键列定义在源表和目标表上是不一致的,数据的物理值一般也是不一致的,那么直接进行 hashcheck 校验肯定会导致校验失败,并且也没办法判断类型转换的准确性。
这里举一个例子,假如源表分区键列类型是 VARCHAR,存在一条数据是'123abc',现将分区键列类型修改为 INT,那么目标表分区键对应的数据则转换成了 123,123 和'123abc'的 hashcheck 值自然是不一样的,因此校验会失败,另外也不能完全确认在 MySQL 中字符串 '123abc' 从 VARVAHR 转换到 INT 的结果就是 123。
为了解决上述两个问题,在创建新表后,会为源表添加一个仅用于数据校验虚拟列(对外不可见),并且该虚拟列是在分区键列的基础上调用列类型转换函数。例如,在上面的例子中,对源表添加一个虚拟列,那么该虚拟列的值即为'123abc'调用转换函数后的结果123,结果与目标表一致,如下图所示。

利用上述添加虚拟列的方式,即可完成数据校验,并且该虚拟列调用的列类型转换函数与 MySQL 中 ALTER TABLE MODIFY COLUMN 转换的处理逻辑一致,因此还可以校验出 DML 隐式转换与 ALTER TABLE MODIFY COLUMN 转换不一致的情况。
全局二级索引处理
在文章中介绍了 PolarDB-X 的全局二级索引[6],全局二级索引为了方便回表查询,默认包含了主表的主键以及分区键作为 Cover 列。为了保证 GSI 和主表数据的一致性,在变更主表分区键列类型时,所有 GSI 的对应 Cover 列的类型也需要同时做变更,因此变更主表的分区键列类型其实会将GSI表的数据也进行重分布。如果主表的分区键和 GSI 的分区键不一致,且对 GSI 的分区键列类型做变更,为了保证数据的一致性,还是需要走相同流程。
查看DDL执行计划
分区键列类型变更并不是一定需要数据重分布,例如对于字符串列类型来说,如果只是想变长,并不修改字符串的 CHARSET 和 COLLATE,那么其实是不需要进行数据重分布的,执行过程与非分区键列类型变更相似。另外,用户可能刚好修改的是 GSI 的分区键列类型,不是主表的分区键,这样仍然会产生数据重分布。可以看到列类型变更其实存在好几种场景,为了便于用户快速区分列类型变更具体是走的什么流程,我们提供了类似 explian 的操作给 DDL语句来使用,下面以sysbench 表举几个例子进行说明。
建表语句:
例1,修改非分区键列类型:
例2,修改分区键列类型,并且需要数据重分布:
其中 CREATE TABLE 为创建新表,DROP TABLE 则为完成校验之后删除旧表,ALTER TABLE 为添加虚拟列用于数据校验。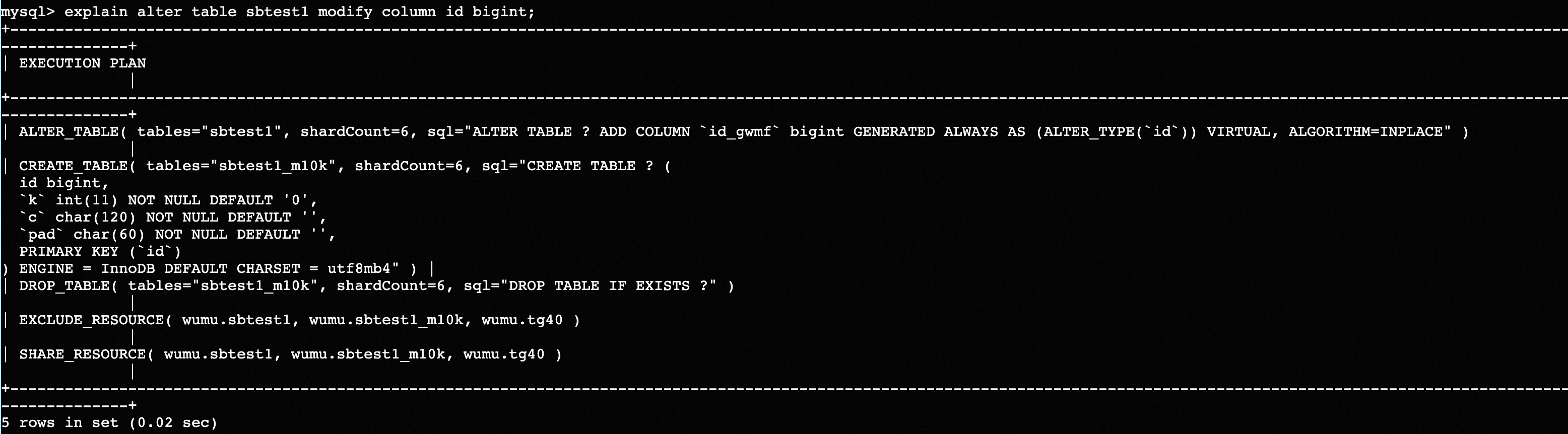
例3,修改分区键列类型,无需数据重分布:
首先将分区键id列修改为 varchar(30),该过程需要数据重分布,然后再将其类型修改为 varchar(60),explain 结果如下,可以看到无需数据重分布(不需要建表删表)。
总结
灵活的对表列类型变更是分布式数据库的重要特性。PolarDB-X 支持了分区键列类型变更的同时,保证了数据的强一致、高可用、对业务透明、去除了分布式带来的限制并且使用起来非常方便。本文在 PolarDB-X 拆分规则变更的基础上,简单阐述了实现分区键列类型变更过程中使用到的各项技术点,PolarDB-X 之所以能够支持该功能,使用到了很多诸如 TSO 事务之类的特性,这也是分布式数据库区别于分布式数据库中间件的重要特性之一。
参考文献
[1] PolarDB-X 数据分布解读(一)
[2] PolarDB-X 数据分布解读(二) :Hash vs Range
[3] PolarDB-X 拆分规则变更
[4] Online, Asynchronous Schema Change in F1
[5] PolarDB-X 分布式事务的实现(一)
[6] PolarDB-X 全局二级索引
