




01
01
版本综述
新增 Deletion Vectors,近实时更新与极速查询 调整 Bucket 默认值为 -1,提升新学者的易用性 新增通用文件索引机制,提升 OLAP 查询性能 优化读写流程的内存及性能,减少 IO 访问次数 Changelog 文件单独管理机制以延长其生命周期 新增基于文件系统的权限系统,管理读写权限
02
01
Deletion Vectors
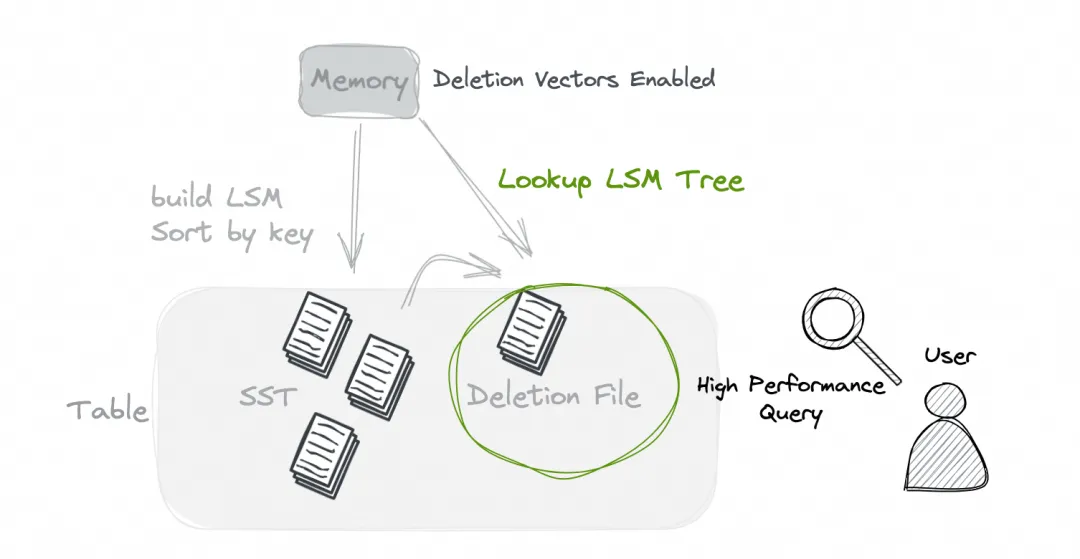
03
01
Bucket 默认值
CREATE TABLE T (k INT PRIMARY KEY NOT ENFORCED,v0 INT,v1 INT);
对于主键表:bucket 为 -1 使用动态 bucket 模式,这会比固定 bucket 值多一些写入的消耗,不过它以方便的配置带来了分布式的处理。 对于 Append 表:bucket 为 -1 是可伸缩的模式,它有更好更方便的分布式处理。
04
01
通用文件索引
此版本前,你可以使用 ORC 自带的索引机制来加速查询,但是它只支持 Bloomfilter 等少数索引,而且你只能在写入文件时生成好对应的索引。
不止支持字段的索引,还支持对 Map Key 的索引构建。 计划支持随时构建已存在文件的索引,这可以避免你新增索引时去重写数据文件。 计划在后续的版本中,新增 Bitmap,N-Gram BloomFilter,倒排等索引。
05
01
读写性能优化
Write 性能优化: 优化了写入时的序列化性能,对于整体写有着 10-20% 的性能提升 大幅提升了 Append Table 多分区写入 (超过5个分区) 的性能问题 加大了 'num-sorted-run.stop-trigger' 的默认值,它会减缓反压 优化了动态 Bucket 写入的启动性能 Commit 性能优化: 大幅降低 Commit 节点的内存占用 去除了 Commit 里面无用的检查,write-only 的提交会快很多 Partition Expire 的性能得到大幅提升 查询性能优化: 大幅降低生成 Plan 时的内存占用 降低了 Plan 以及 Read 阶段对文件系统 Namenode 的访问,这也有利于对象存储的 OLAP 性能 Codegen 支持了 Cache,这将有效提升短查询的性能 通过序列化 Table 对象,Hive 查询大幅降低了访问文件系统 Namenode 的频率 大幅提升了 first_row merge-engine 的查询性能
06
01
Changelog 生命周期
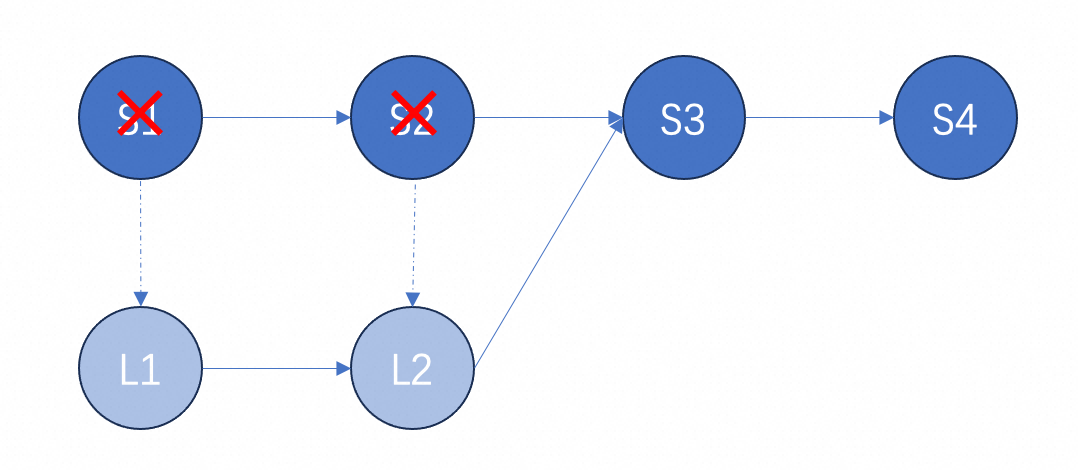
CREATE TABLE T (k INT PRIMARY KEY NOT ENFORCED,...) WITH ('changelog-producer'='input','changelog.time-retained' = '1 d')
07
01
权限管理系统
CREATE CATALOG `my-catalog` WITH ('type' = 'paimon',-- ...'user' = 'root','password' = 'mypassword');-- create a user authenticated by the specified password-- change 'user' and 'password' to the username and-- password you wantCALL sys.create_privileged_user('user', 'password');-- you can change 'user' to the username you want, and-- 'SELECT' to other privilege you want-- grant 'user' with privilege 'SELECT' on the whole-- catalogCALL sys.grant_privilege_to_user('user', 'SELECT');-- grant 'user' with privilege 'SELECT' on database my_dbCALL sys.grant_privilege_to_user('user', 'SELECT', 'my_db');-- grant 'user' with privilege 'SELECT' on table my_db.my_tblCALL sys.grant_privilege_to_user('user', 'SELECT', 'my_db', 'my_tbl');
08
01
其余核心功能
支持创建 Tag 时的 TTL 指定,这可以让你更随意的创建 Tag 来进行安全的批读 新增记录级别 TTL 配置 (record-level.expire-time),数据的 Expire 会在 Compaction 时进行,这可以通过淘汰过期数据来有效减少 Compaction 的压力 聚合函数 collect, merge_map, last_value, nested_update 支持了 retraction (DELETE / UPDATE_BEFORE) 消息的输入,具体使用请结合你的场景来测试 Sequence Field 重新设计,当两条数据的 Sequence Field 相等时,使用进入 Paimon 的先后顺序来决定顺序 新增了一种 Time Travel 方式,可以指定 Watermark 的批读 文档调整:Flink 和 Spark 有单独目录,包括和读、写、表管理等页面,希望大家喜欢 系统表:大幅提升了 files & snapshots & partitions 系统表的查询性能和稳定性 ORC:大幅提升 ORC 复杂类型 (array, map) 的写入性能;支持了 zstd 压缩,这是我们非常推荐的高压缩的算法
09
01
Flink
DataStream API
FlinkSinkBuilder: 构建 DataStream Sink FlinkSourceBuilder:构建 DataStream Source
Lookup Join
Flink Lookup Join 在此版本中使用 Hash Lookup 来获取数据,这可以避免 RocksDB 的数据插入带来的开销。 此版本也继续提升了 Hash Lookup,支持了压缩,并且默认为 lz4,changelog-producer 为 Lookup 也会由此受益。 并且 Flink Lookup Join 引入了 max_pt 模式,这是一种有趣的模式,它只会去 Join 最新的分区数据,这比较适配每个分区都是全量数据的维表。
其它 Flink 改动
批读分区表的性能得到大幅提升,之前由于设计问题,导致每次批会去扫描所有分区,目前已移除 Metrics 系统重新设计,移除了分区及 Bucket 级别的 Metrics,这会导致 Flink JobManager 长时间运行会发生 OOM 引入 commit.force-create-snapshot,强制生成 snapshot,这可以让某些业务强依赖 Snapshot 的生成 增强 Sort:引入 Hilbert Sort,这种 Sort 在字段超过5个时仍然会有一定效果,而 z-order 只推荐排序字段在5个内;Sort 新增 Range 策略,这可以避免由于行大小不一致导致的排序倾斜问题
CDC Ingestion 的时间函数支持了对 Epoch Time 的处理 优化了 Flink 指定 consumer-id 流读的扩展性以支持多分区的流读 对接了 Flink 1.19,COMPACT Procedure 支持了 Named Argument,我们遗憾的决定,由于维护了超过5个版本,不再支持 Flink 1.14,推荐使用 Flink 1.17+ 版本
10
01
Spark
Spark Generic Catalog 支持了 function 相关功能 Delete Tag Procedure 支持了删除多个 Tags 的能力 遗憾的决定,由于维护了超过5个版本,不再支持 Spark 2,推荐使用 Spark 3.3+ 版本
11
01
生态与关联项目
Hive 迁移:支持了迁移整个 Hive Database 库到 Paimon 引入 Jdbc Catalog,这可以让你的业务摆脱 Hive Metastore 的依赖 Hive Writer 支持了 Tez-mr 引擎,我们目前只推荐 Hive Writer 在小数据量时使用 Paimon-Trino 最新版本只支持了 Trino 420+ 的版本,但是查询 orc 的性能得到大幅提升。 Paimon-Webui 项目研发有了比较大的进展,即将发布。
12
01
关于 Paimon
微信公众号:Apache Paimon ,了解行业实践与最新动态 官网:https://paimon.apache.org/ 查询文档和关注项目 希望大家都去项目 Github 页面点个 Star,你的支持是 Paimon 社区研发的动力
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
