本文整理于Klustron社区论坛的技术答疑。
为促进团队内外的沟通联系,我们Klustron团队的bbs论坛已经线,欢迎各位同学交流答疑。
论坛链接:https://forum.klustron.com/,或者点击文末“阅读原文”,即可跳转。
关键词:MySQL、buffer pool、InnoDB、存储
01 
- 数据库版本: MySQL 8.0.25/MySQL 5.7.21
- innodb_buffer_pool_size=32G
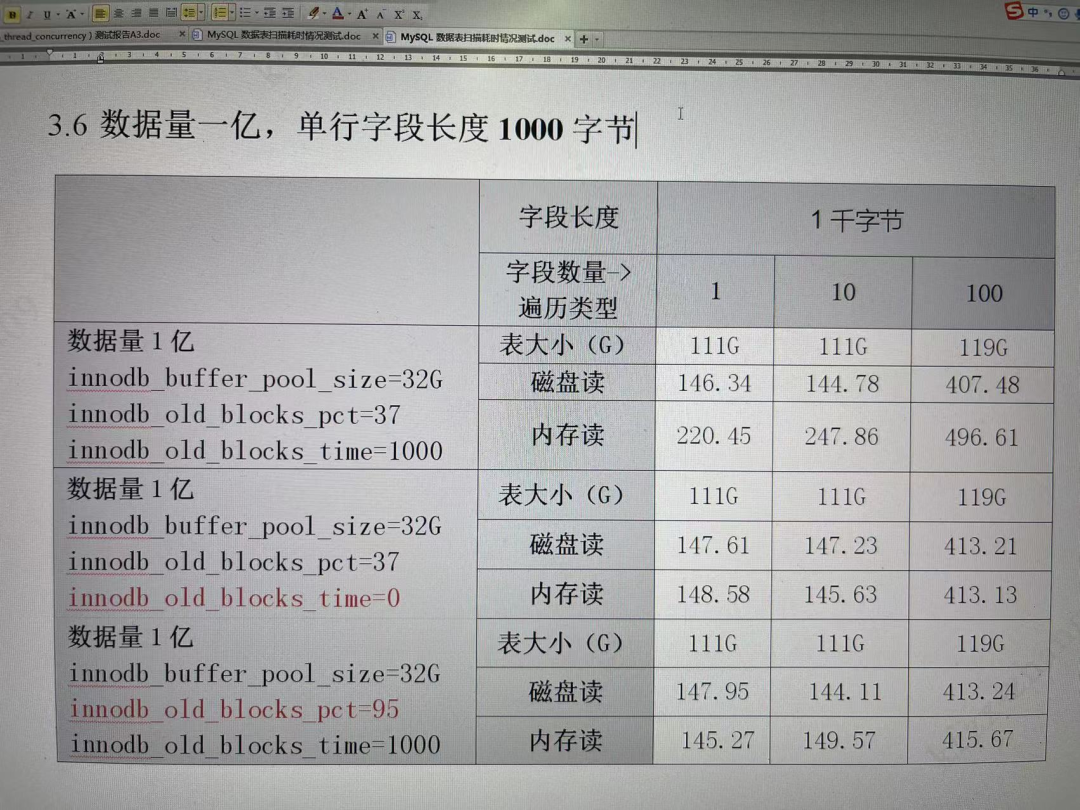
表数据为新insert数据,无delete、无update,数据量为1亿,在数据库服务器本地用mysql自带客户端测试全表扫描在磁盘读与缓存读的执行耗时差异(测试期间仅运行select全表扫描,无其他并发sql交叉影响)。- mysql一个数据量为1亿的表,有1个字段,每个字段存1000个字母,idb大小为111G。
- mysql一个数据量为1亿的表,有10个字段,每个字段存100个字母,idb大小为111G。
- mysql一个数据量为1亿的表,有100个字段,每个字段存10个字母,idb大小为119G。
mysql一个数据量为1亿的表,有1个字段,每个字段存1000个字母 建表语句如下:CREATE TABLE `t_user_1_10000_10000` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c_name` varchar(10000) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
) CHARSET=utf8mb4;
在innodb_buffer_pool_size=32G,关闭innodb_buffer_pool_dump_at_shutdown = off, 在mysql重启后,全表扫描该表,出现缓存读(非第一次执行)执行耗时 大于 磁盘读(第一次执行)耗时 的原因是什么?ps: 相同表结构与数据,缓存读(非第一次执行)执行耗时 大于 磁盘读(第一次执行)耗时 在机械盘无法复现,在ssd能稳定复现。为什么调整 innodb_old_blocks_pct=95 或者 innodb_old_blocks_time=0 后,缓存读(非第一次执行)执行耗时 **几乎等于** 磁盘读(第一次执行)耗时?关闭 innodb_buffer_pool_dump_at_shutdown = off ,当idb大于 innodb_buffer_pool_size 大小,以全表扫描 第一次执行 与 非第一次执行 使用innodb buffer pool有什么区别?02 这个提问涉及到InnoDB的buffer pool的工作原理,在官网文档有详细介绍,本文不赘述。首先这里的提问和该表的列的数量无关,与该表文件的size有关,3个表的文件size非常接近,因此下文的讨论忽略3个表的不同。InnoDB buffer pool 是32GB,数据文件是111GB,也就是buffer pool 的3倍以上,做单线程全表扫描,每个叶节点page 被IO读取一次,内节点不会被访问到,无其他并发连接干扰。此表的行按照id递增顺序被插入,全表扫描这个表的顺序与灌入这个表的顺序相同,所以每个被预读的extent中所有的page都会被扫描到,并且不会一次预读多个extent,而是接近扫描完一个extent再预读下一个extent,也就是说每次预读不会导致超过一个extent数量的page被evict。对于问题2,innodb_old_blocks_pct=95表示一个extent的所有page被预读入buffer pool后放到LRU头部5%的位置,此项设置中innodb_old_blocks_time=1000。所以如果一个page被scan了,那么它不会被立刻放到LRU队头而是要等1秒,一般来说一秒内这个page已经被scan完毕了,因此这个page其实是不会被放到队头的。随着更多页面被读入buffer pool,LRU list中这些被读入的page无论是否被scan了,都会从距离队头5%的位置被逐步推到LRU队尾,最终被evict出去。问题3的配置,预取页面就把它放到LRU list距离LRU队尾3/8(此配置中innodb_old_blocks_pct=37)的位置,innodb_old_blocks_time=0表示如果一个page被首次scan就立刻放到队头。由于上述原因,每个被预读的page都会被扫描到,然后从队头被逐步推到队尾然后被evict出去。问题2,3 相当于用一个小窗口(32GB的buffer pool) 扫过一条长卷(110多GB的数据文件),每个extent都需要一次read IO的开销,并且其中所有页面停留在buffer pool中直到接近32GB的页面被依次读入之后才被排出。这种情况用不用buffer pool没有区别,buffer pool的作用彻底消失了,因为并不存在重复多次的内存读,也就是不存在 “需要重复scan一个page多次,后面几次能从buffer pool找到” 这种情况。当这两种情况scan完毕一遍之后,buffer pool中残留的是该表最后(id 递增顺序) 32GB的数据,下次在全表scan时,要从头(id=1)开始扫描,buffer pool中上次全表扫描残留的该表的页面一定没有任何一页是下次全表扫描时能够直接用到的page,scan每一页都需要它被IO read到buffer pool中。实测也验证了上述分析,这与提问者的观察也是相同的。问题1的情况,该表的前面32GB填充满了buffer pool之后,因为innodb_old_blocks_pct=37并且innodb_old_blocks_time=1000,也就是预取的page放到距离LRU队尾3/8的位置,并且scan一个page几乎不会把它放到LRU队头,也就是buffer pool被填满之后,就只有3/8也就是12GB的buffer pool可用,其余20GB留存的是这个表的最前面(id递增的顺序)20GB数据。LRU 队尾3/8的每个page,被读取一次到buffer pool, scan 完毕后就不再被本次全表扫描访问到,并且最终被evict出去。这样的话,12GB的buffer pool虽然小了很多,但是其实并不会影响首次全表扫描的速度,它与问题2/3的全表扫描的速度应该是非常接近的。我们实测也确实如此,但是问题1的后续的每次全表扫描中,由于该表的前20GB数据已经在buffer pool中了,因此无需再次IO读取,省去了近20% (20/110)的IO的时间。因为后面每次的缓存读能够有接近20%的数据从buffer pool中直接找到page并scan它。并且这些page被scan一遍之后仍然会停留在LRU list的前5/8的原位,因此不会被evict出去。头20GB后面的page在每次缓存读时也和首次scan一样,会从被读入时位于距离队尾3/8开始逐步被推到队尾然后被evict出去。因此首次select应该比后面的scan更慢,而不是更快,这与提问者的观察结果完全相反。我们实测的结果与我们的分析结果相同。至于缓存读可以快多少,要看page已经在内存中的情况下scan执行的开销,本例中由于缓存读的IO减少了接近20%的时间,那么缓存读的全表scan总体减少的时间的比例要再低一些,我们实测是6%~10% 这个范围。并且后面每次缓存读的全表扫描的时耗应该很接近,实测也确实如此。欢迎大家下载和安装Klustron数据库集群,并免费使用(无需注册码)。http://downloads.klustron.com/如需购买请邮箱联系sales_vip@klustron.com,有相关问题欢迎添加下方小助手微信联系🌹https://doc.klustron.com/zh/Klustron_Instruction_Manual.htmlhttps://doc.klustron.com/zh/Klustron_Quickly_Guide.htmlhttps://doc.klustron.com/zh/Klustron-function-experience-example.htmlhttps://doc.klustron.com/zh/product-usage-and-evaluation-guidelines.html