TiDB 恢复利器:Lightning 工具的深入应用与实战解析
一、TiDB Lightning 工具简介
TiDB Lightning 是一个专为 TiDB/TiKV 集群设计的快速数据恢复工具。它基于 TiDB 的 MyDumper 协议,能够高效兼容 MySQL mysqldump/mydumper 导出的数据文件格式。通过多线程并发导入数据,TiDB Lightning 极大地提高了数据恢复的速度,为用户提供了便捷、高效的数据恢复解决方案。
TiDB Lightning 工具全量数据高速导入到 TiDB 集群,速度可达到传统执行 SQL 导入方式的 3 倍以上、大约每小时 300 GB。
Lightning 有以下两个主要的使用场景:一是大量新数据的快速导入、二是全量数据的备份恢复。
二、TiDB Lightning 整体架构
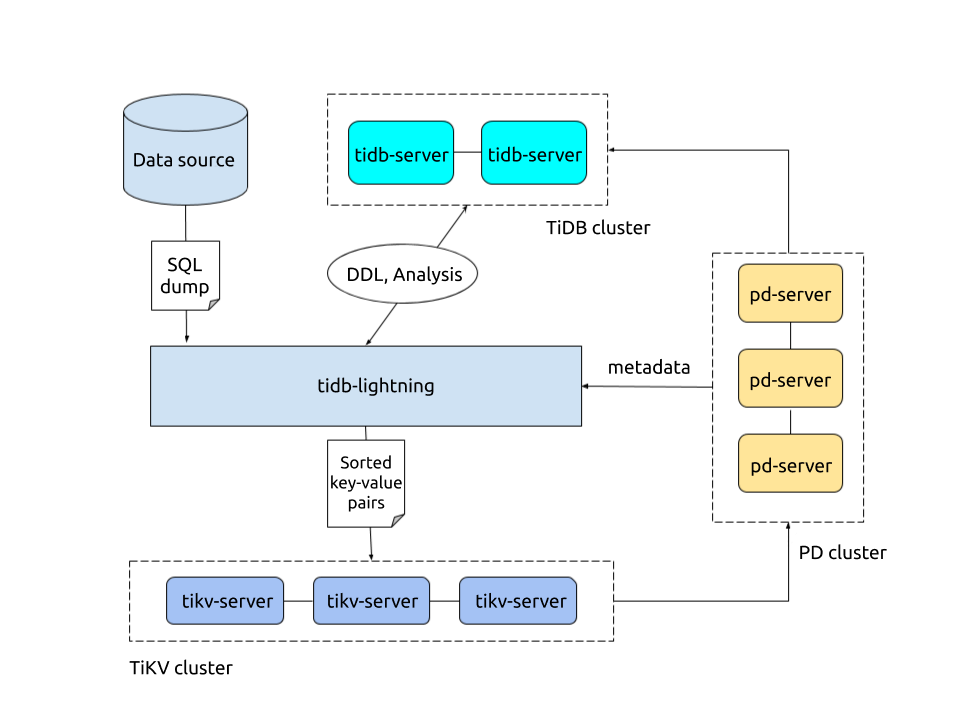
TiDB Lightning目前支持两种导入方式,通过 backend 配置区分。不同的模式决定 TiDB Lightning 如何将数据导入到目标 TiDB 集群。
物理导入模式:TiDB Lightning 首先将数据编码成键值对并排序存储在本地临时目录,然后将这些键值对上传到各个 TiKV 节点,最后调用TiKV Ingest接口将数据插入到TiKV的 RocksDB 中。如果用于初始化导入,请优先考虑使用物理导入模式,其拥有较高的导入速度。物理导入模式对应的后端模式为 local。
逻辑导入模式:TiDB Lightning 先将数据编码成SQL,然后直接运行这些SQL语句进行数据导入。如果需要导入的集群为生产环境线上集群,或需要导入的目标表中已包含有数据,则应使用逻辑导入模式。逻辑导入模式对应的后端模式为tidb。
- physical import mode(Local-backend)--面向的初始化导入(目标库,不能有相关表)
- logical import mode(TiDB-backend) --直接连接TiDB数据库执行SQL
三、TiDB Lightning 导入模式(import mode)原理
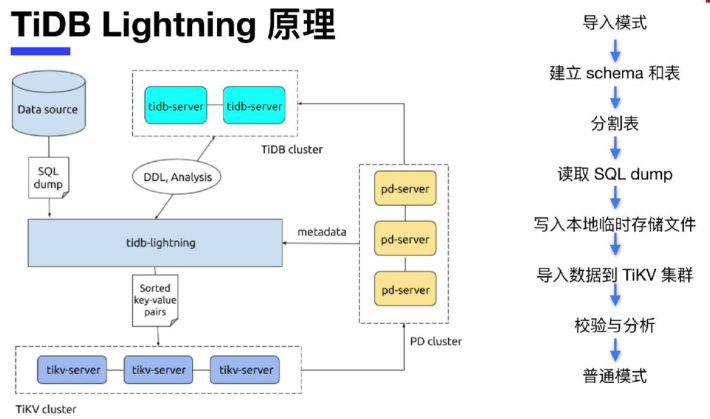
第一步、TiKV进入导入模式(import mode)
注意:在导入数据之前,tidb-lightning 会自动将 TiKV 节点切换为“导入模式” (import mode),优化写入效率并停止自动压缩。物理导入对线上业务有影响,注意操作时间窗口。
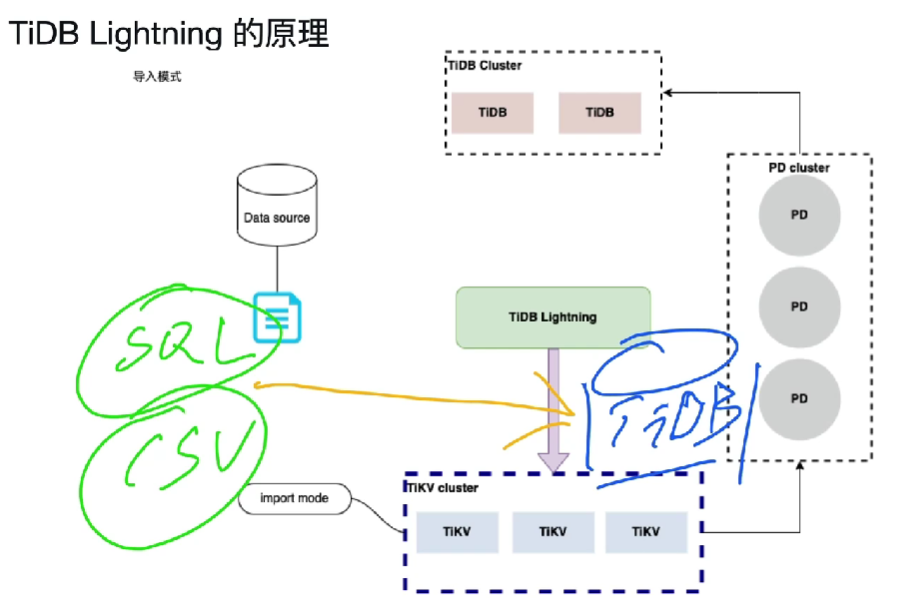
第二步、建立schema和表(创建)
通过连接TiDB Server连接目标库自动创建相关schema和表
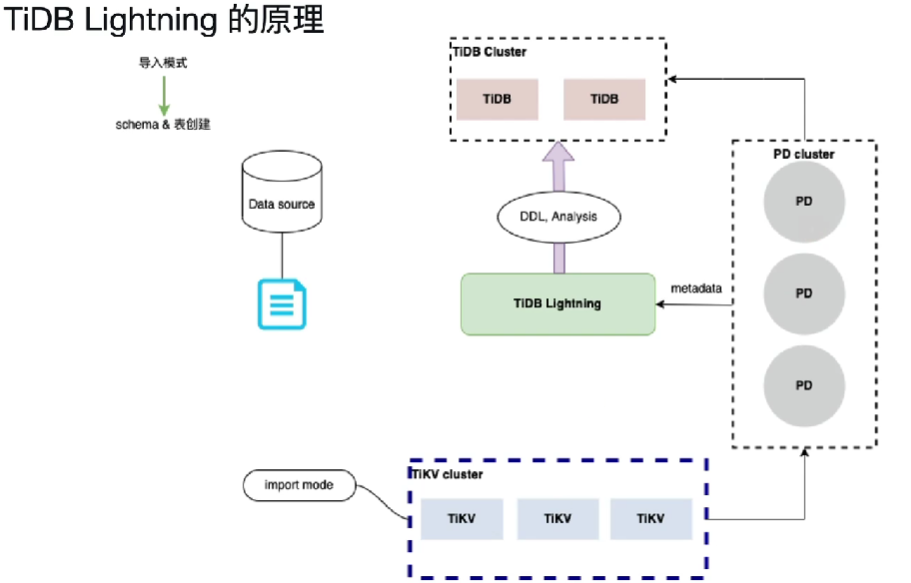
第三步、分割源数据
切分表数据来为下一步实现并行导入数据提高导入效率做准备。
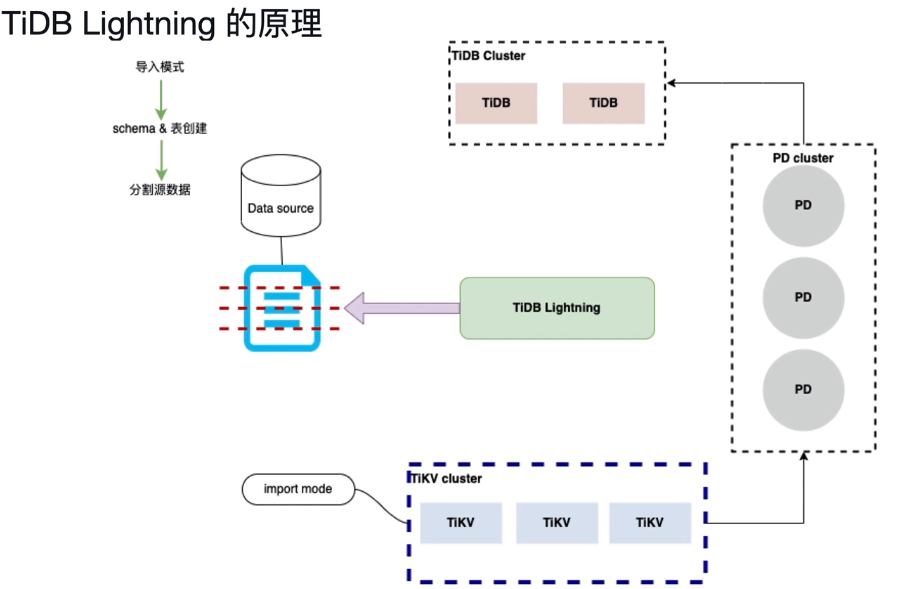
第四步、读取dump文件,转存到本地(SQL/CSV 🡺 key-value键值对),切片之后并发读取,排序之后成为一个一个键值对
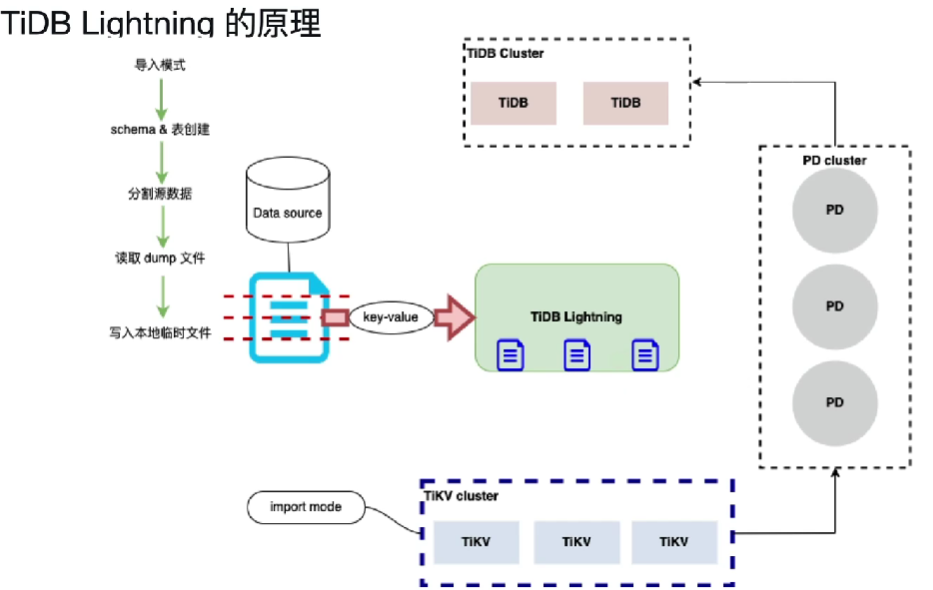
第五步、导入临时文件到TiKV集群
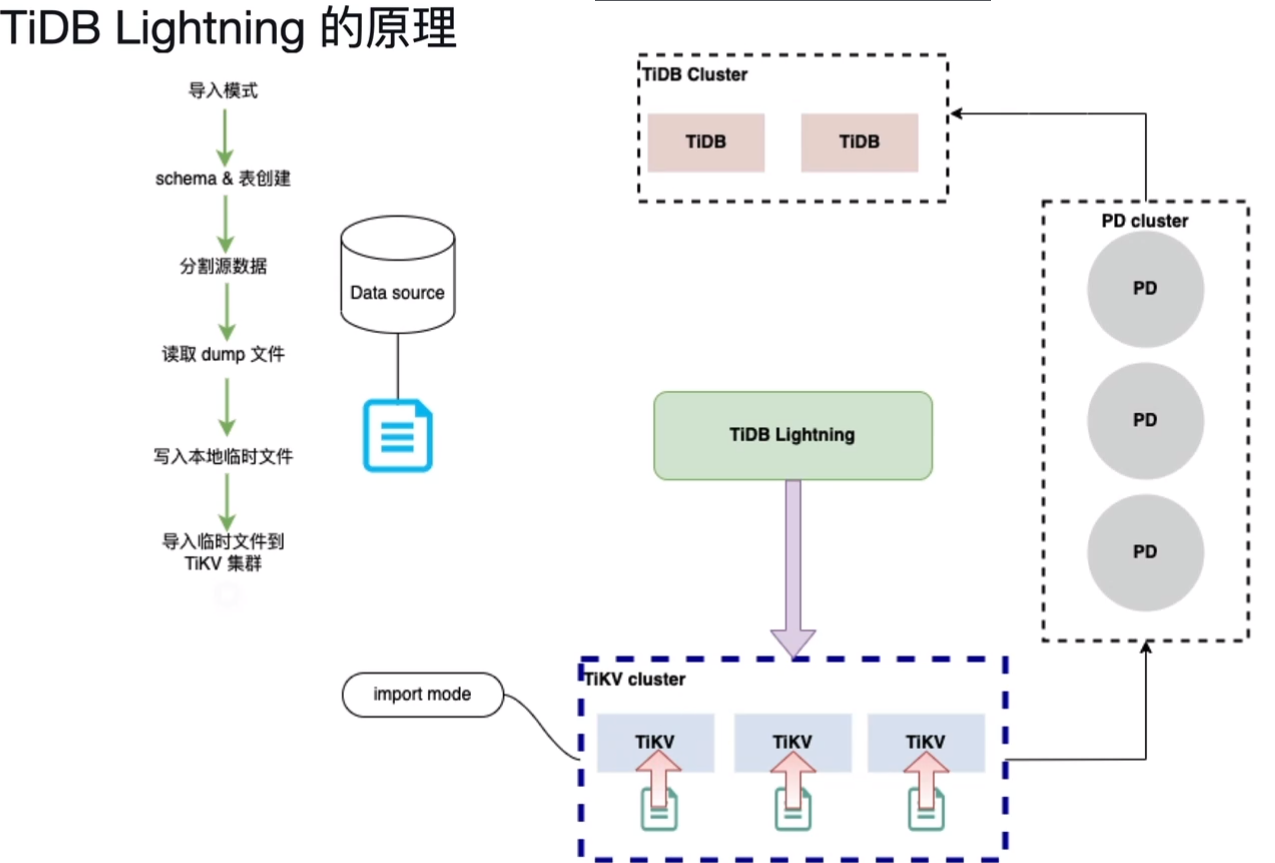
第六步、检验和分析(之后统计信息的收集,自增列等工作)
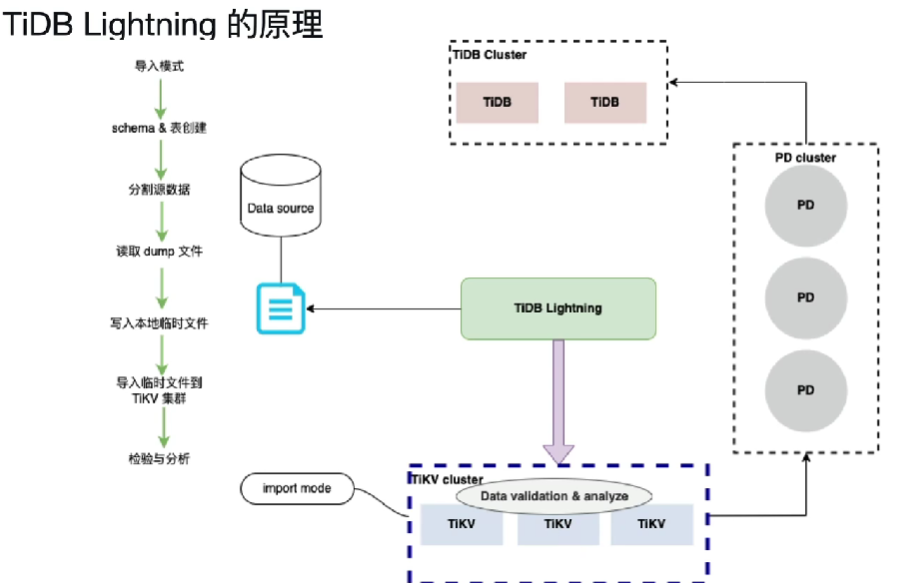
第七步、导入模式切换到普通模式
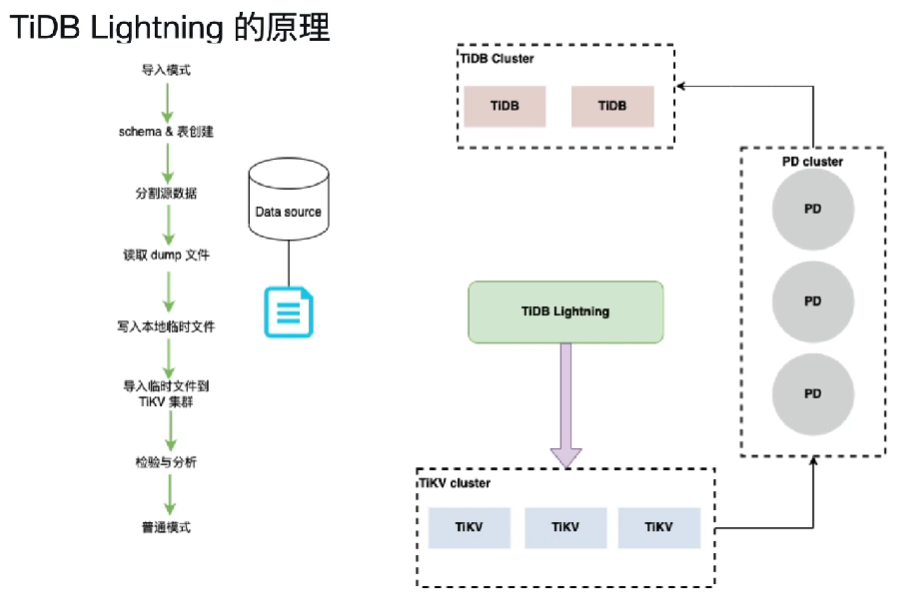
四、TiDB Lightning 导入模式(import mode)特点对比
后端 | Physical import mode | logical import mode |
速度 | 快(~500 GB/小时) | 慢(~50 GB/小时) |
资源使用率 | 高 | 低 |
占用网络带宽 | 高 | 低 |
导入时是否满足ACID | 否 | 是 |
目标表 | 必须为空 | 可以不为空 |
支持 TiDB 集群版本 | >=v4.0.0 | 全部 |
TiDB是否可以提供服务 | 否 | 是 |
适合场景 | 准备上线系统初始化阶段 | 生产系统 |
五、TiDB Lightning 适用场景
- 应用场景
- 快速大量数据初始化(Physical lmport Mode)
- 逻辑备份恢复
- 文件格式
- 导入 Dumpling、CSV 或 Amazon Aurora Parquet 输出格式的数据源
- 从本地盘或 Amazon S3 读取数据
六、TiDB Lightning 数据迁移工具特性
使用场景 | 用于将数据全量导入到 TiDB |
|---|---|
上游(输入源文件) | TiDB Dumpling 输出的文件 从 Amazon Aurora 或 Apache Hive 导出的 Parquet 文件 CSV 文件 从本地盘或 Amazon S3 云盘读取数据 |
下游 | TiDB |
主要优势 | 支持快速导入大量数据,实现快速初始化 TiDB 集群的指定表 支持断点续传 支持数据过滤 |
使用限制 | 如果使用物理导入模式进行数据导入,TiDB Lightning运行后,TiDB集群将无法正常对外提供服务。 如果你不希望TiDB集群的对外服务受到影响,可以参考TiDB Lightning 逻辑导入模式中的硬件需求与部署方式进行数据导入。 |
七、TiDB Lightning 限制
- 如果与Tiflash一起使用,导入时间会延迟
- 如果表的字符集为GBK,TiDB V5.4版本之后才支持
- 如果源数据是Apache Parquet文件,目前只支持从Amazon Aurora导出的Parquet 文件
八、TiDB Lightning 工具部署与使用
1、硬件需求
- 建议单独部署(没有条件可以设置region-concurency=1限制CPU使用)
- 建议CPU、内存
- Physical lmport Mode 模式下:32核以上CPU + 64 GB 以上内存
- Logical lmport Mode 模式下:4核以上CPU+8 GB 以上内存
- 建议独占 IO 并采用闪存等高性能存储介质
- 建议网络带宽大于等于 10 Gbps
2、前置检查
- 集群版本/状态是否正常
- 是否有权限读取数据
- 导入空间是否足够
- Region 分布状态
- 数据文件是否有大 CSV 文件
- 是否可以从断点恢复
- 是否可以导入数据到已存在的数据表中
- 导入的目标表是否为空
3、目标(下游)数据库权限
对象 | 导入模式 | 所需权限 |
目标表 | ALL | CREATE,SELECT,INSERT,UPDATE,DELETE,DROP,ALTER |
目标 database | ALL | SELECT |
information_schema.columns | Logical Import Mode | SELECT |
mysql.tidb | Physical Import Mode | SELECT |
系统 | Physical Import Mode | SUPER |
4、并行导入限制(v5.3.0之后)
- 只支持空表
- 建议physical import mode模式
- 不可同时使用physical import mode和logical import mode导入一个tidb集群
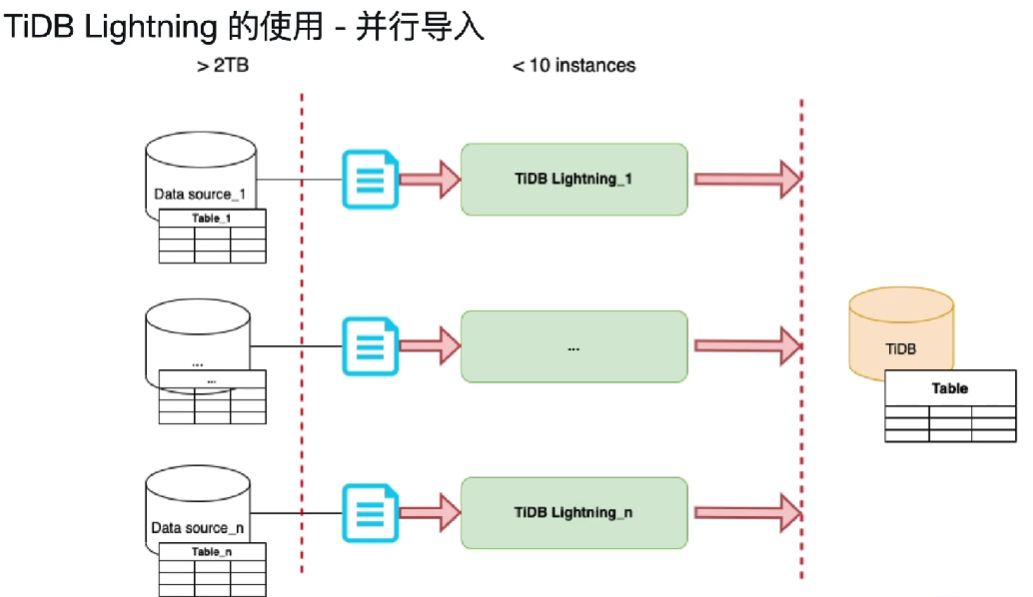
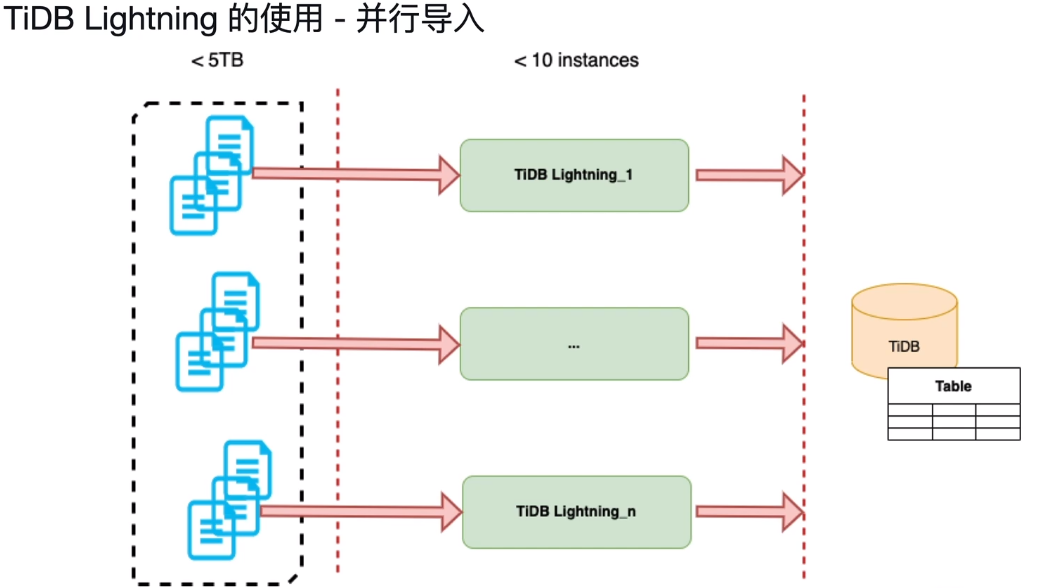
5、并行导入场景
1.分库分表场景下tidb lightning不宜超过10个
2.单数据源下,数据库不超过5TB,tidb lightning不宜超过10个
6、TiDB Lightning 的部署
方法一、使用TiUP 执行tiup install lightning 命令
查看已安装的组件

查看能安装的组件
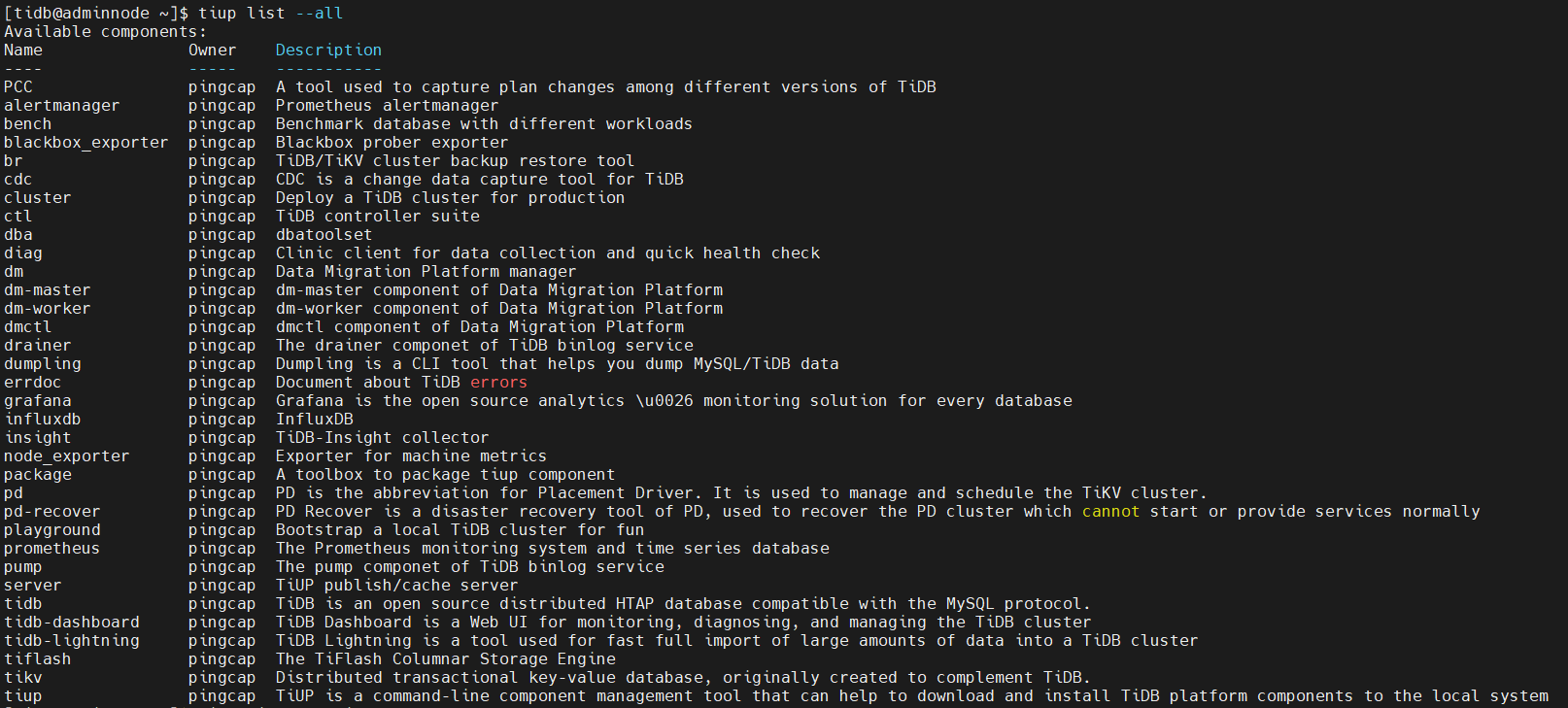
查看能安装的tidb-lightning版本

安装tidb-lightning组件

查看安装的信息

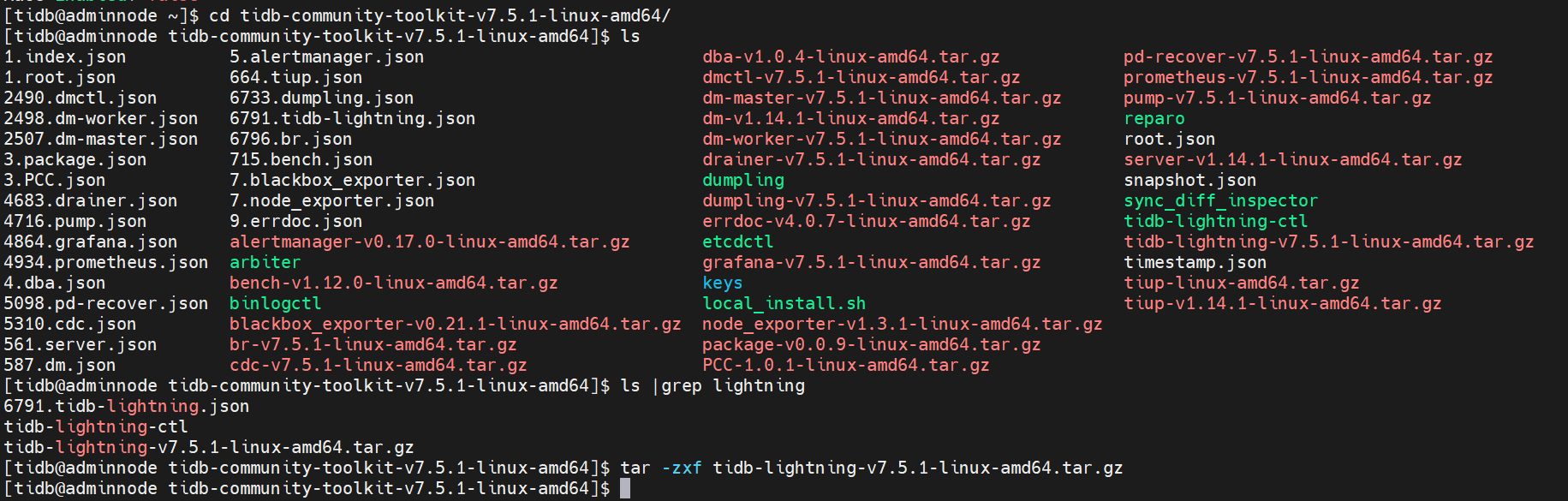
方法二、tidb-commun ity-toolkit安装包
下载相关toolkit工具包并配置环境变量
- 解压工具包
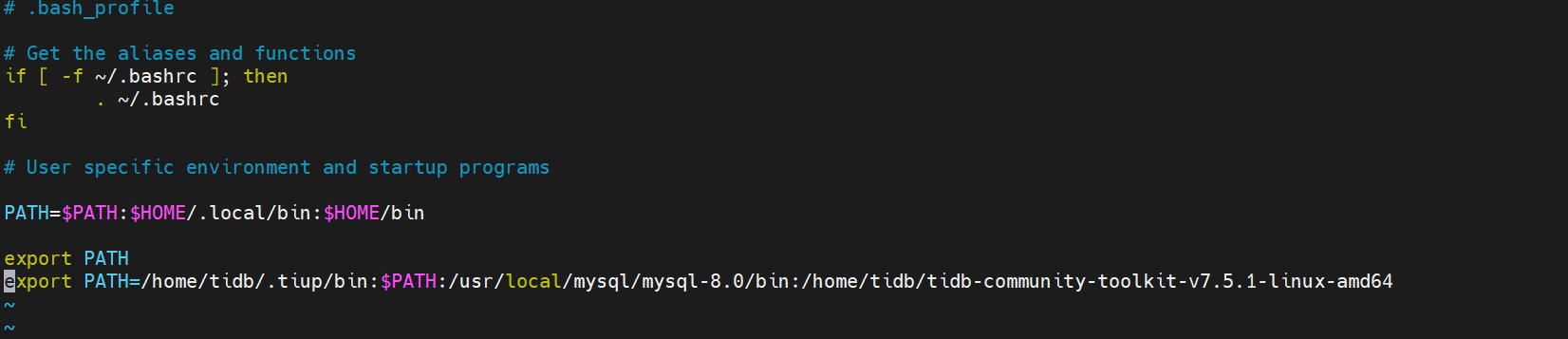
- 配置环境变量
$vi .bash_profile
添加如下:
export PATH=/home/tidb/.tiup/bin:$PATH:/usr/local/mysql/mysql-8.0/bin:/home/tidb/tidb-community-toolkit-v7.5.1-linux-amd64
$source .bash_profile
- 查看tidb-lightning版本信息

7、TiDB Lightning 的配置
- TiDB Lightning 配置参数
你可以使用配置文件或命令行配置 TiDB Lightning。
TiDB Lightning 的配置文件分为“全局”和“任务”两种类别,二者在结构上兼容。只有当服务器模式开启时,全局配置和任务配置才会有区别;默认情况下,服务器模式为禁用状态,此时 TiDB Lightning 只会执行一个任务,且全局和任务配置使用同一配置文件。
- 冲突数据检测
冲突数据是指两条或两条以上记录中存在主键或唯一键列数据重复。TiDB Lightning 的逻辑导入模式通过 conflict.strategy 配置冲突数据的处理行为,使用不同的 SQL 语句进行导入。
策略 | 冲突时默认行为 | 对应 SQL 语句 |
|---|---|---|
"replace" | 新数据替代旧数据 | REPLACE INTO ... |
"ignore" | 保留旧数据,忽略新数据 | INSERT IGNORE INTO ... |
"error" | 终止导入 | INSERT INTO ... |
"" | 不进行冲突检查和处理,但如果存在有主键和唯一键冲突的数据,会在后续步骤报错 | 无 |
1.物理导入模式 (Physical Import Mode)
物理导入模式对应的后端模式为 local。可以在配置文件 tidb-lightning.toml 中修改:
[lightning]
# 日志
level = "info"
file = "tidb-lightning.log"
max-size = 128 # MB
max-days = 28
max-backups = 14
# 启动之前检查集群是否满足最低需求。
check-requirements = true
[mydumper]
# 本地源数据目录或外部存储 URI。关于外部存储 URI 详情可参考 https://docs.pingcap.com/zh/tidb/v6.6/backup-and-restore-storages#uri-%E6%A0%BC%E5%BC%8F。
data-source-dir = "/data/my_database"
[conflict]
# 从 v7.3.0 开始引入的新版冲突数据处理策略。默认值为 ""。
# - "":不进行冲突数据检测和处理。如果源文件存在主键或唯一键冲突的记录,后续步骤会报错
# - "error":检测到导入的数据存在主键或唯一键冲突的数据时,终止导入并报错
# - "replace":遇到主键或唯一键冲突的数据时,保留新的数据,覆盖旧的数据
# - "ignore":遇到主键或唯一键冲突的数据时,保留旧的数据,忽略新的数据
# 目前不能与 tikv-importer.duplicate-resolution(旧版冲突检测处理策略)同时使用
strategy = ""
# threshold = 9223372036854775807
# max-record-rows = 100
[tikv-importer]
# 导入模式配置,设为 local 即使用物理导入模式
backend = "local"
# 冲突数据处理方式
duplicate-resolution = 'remove'
# 本地进行 KV 排序的路径。
sorted-kv-dir = "./some-dir"
# 限制 TiDB Lightning 向每个 TiKV 节点写入的带宽大小,默认为 0,表示不限制。
# store-write-bwlimit = "128MiB"
# 物理导入模式是否通过 SQL 方式添加索引。默认为 `false`,表示 TiDB Lightning 会将行数据以及索引数据都编码成 KV pairs 后一同导入 TiKV,实现机制和历史版本保持一致。如果设置为 `true`,即 TiDB Lightning 会导完数据后,再使用 add index 的 SQL 来添加索引。
# 通过 SQL 方式添加索引的优点是将导入数据与导入索引分开,可以快速导入数据,即使导入数据后,索引添加失败,也不会影响数据的一致性。
# add-index-by-sql = false
[tidb]
# 目标集群的信息。tidb-server 的地址,填一个即可。
host = "192.168.126.201"
port = 4000
user = "root"
# 设置连接 TiDB 的密码,可为明文或 Base64 编码。
password = "tidb123"
# 必须配置。表结构信息从 TiDB 的“status-port”获取。
status-port = 10080
# 必须配置。pd-server 的地址,填一个即可。
pd-addr = "192.168.126.204:2379"
# tidb-lightning 引用了 TiDB 库,并生成产生一些日志。
# 设置 TiDB 库的日志等级。
log-level = "error"
[post-restore]
# 配置是否在导入完成后对每一个表执行 `ADMIN CHECKSUM TABLE <table>` 操作来验证数据的完整性。
# 可选的配置项:
# - "required"(默认)。在导入完成后执行 CHECKSUM 检查,如果 CHECKSUM 检查失败,则会报错退出。
# - "optional"。在导入完成后执行 CHECKSUM 检查,如果报错,会输出一条 WARN 日志并忽略错误。
# - "off"。导入结束后不执行 CHECKSUM 检查。
# 默认值为 "required"。从 v4.0.8 开始,checksum 的默认值由此前的 "true" 改为 "required"。
#
# 注意:
# 1. Checksum 对比失败通常表示导入异常(数据丢失或数据不一致),因此建议总是开启 Checksum。
# 2. 考虑到与旧版本的兼容性,依然可以在本配置项设置 `true` 和 `false` 两个布尔值,其效果与 `required` 和 `off` 相同。
checksum = "required"
# 配置是否在 CHECKSUM 结束后对所有表逐个执行 `ANALYZE TABLE <table>` 操作。
# 此配置的可选配置项与 `checksum` 相同,但默认值为 "optional"。
analyze = "optional"
2.逻辑导入模式对应的后端模式为 tidb。
可以通过以下配置文件使用逻辑导入模式执行数据导入:
[lightning]
# 日志
level = "info"
file = "tidb-lightning.log"
max-size = 128 # MB
max-days = 28
max-backups = 14
# 启动之前检查集群是否满足最低需求。
check-requirements = true
[mydumper]
# 本地源数据目录或外部存储 URI。关于外部存储 URI 详情可参考 https://docs.pingcap.com/zh/tidb/v6.6/backup-and-restore-storages#uri-%E6%A0%BC%E5%BC%8F。
data-source-dir = "/data/my_database"
[tikv-importer]
# 导入模式配置,设为 tidb 即使用逻辑导入模式
backend = "tidb"
[tidb]
# 目标集群的信息。tidb-server 的地址,填一个即可。
host = "192.168.126.201"
port = 4000
user = "root"
# 设置连接 TiDB 的密码,可为明文或 Base64 编码。
password = "tidb123"
# tidb-lightning 引用了 TiDB 库,并生成产生一些日志。
# 设置 TiDB 库的日志等级。
log-level = "error"
8、配置环境检查
逻辑导入
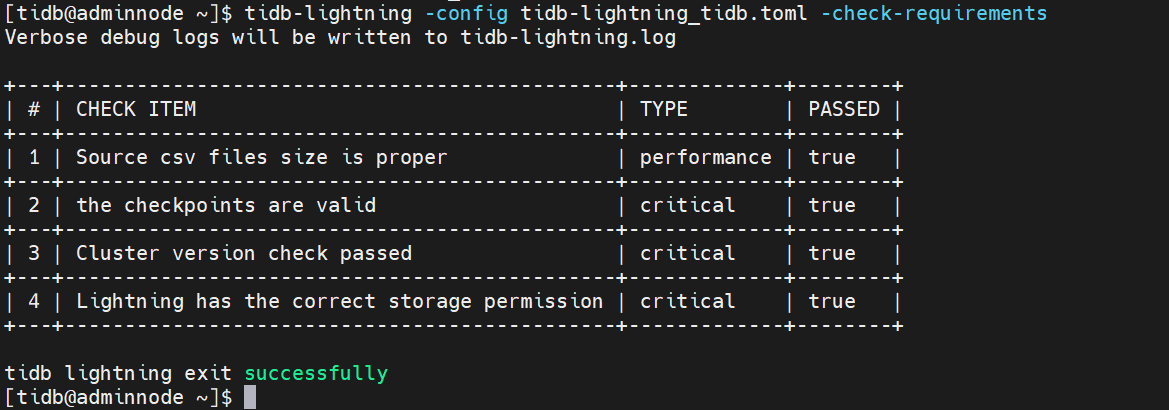
物理导入
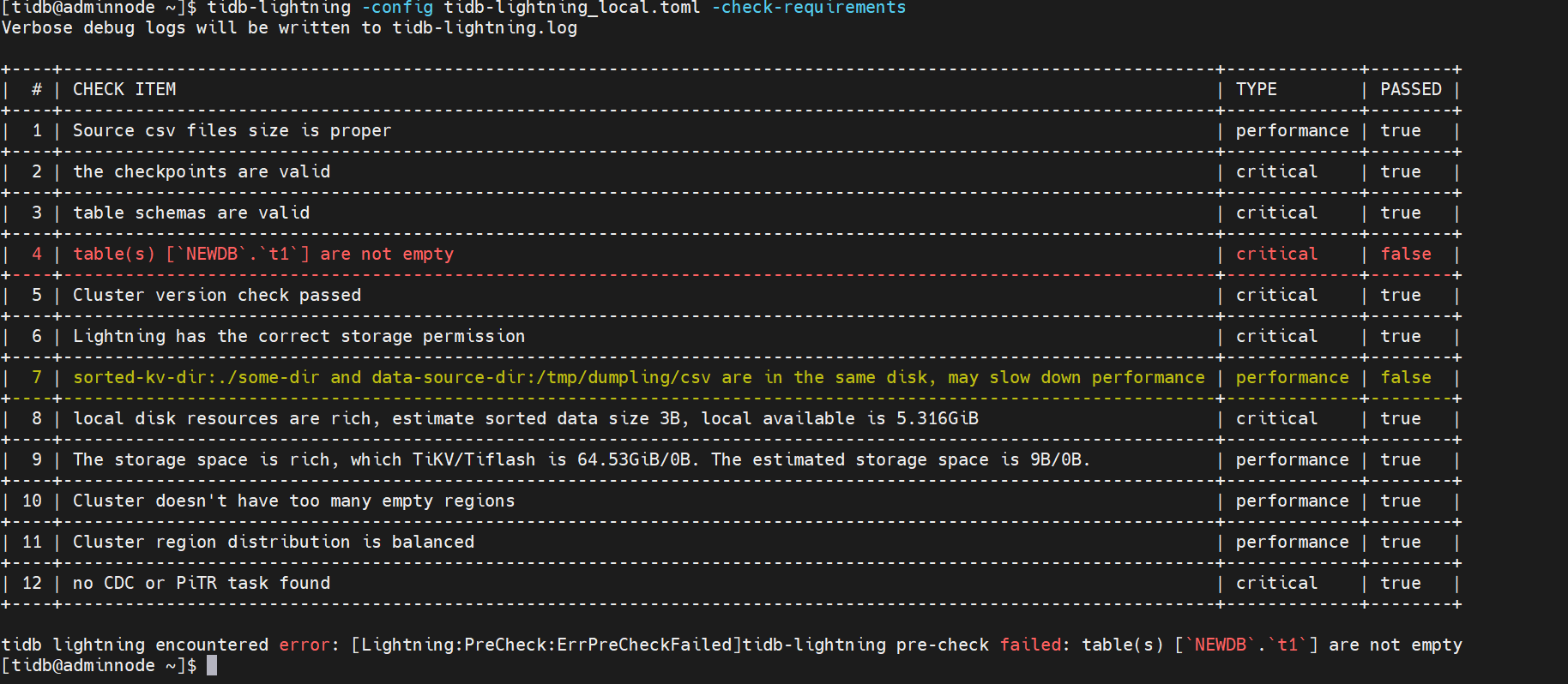
提示有不为空的表,需要清理相关表
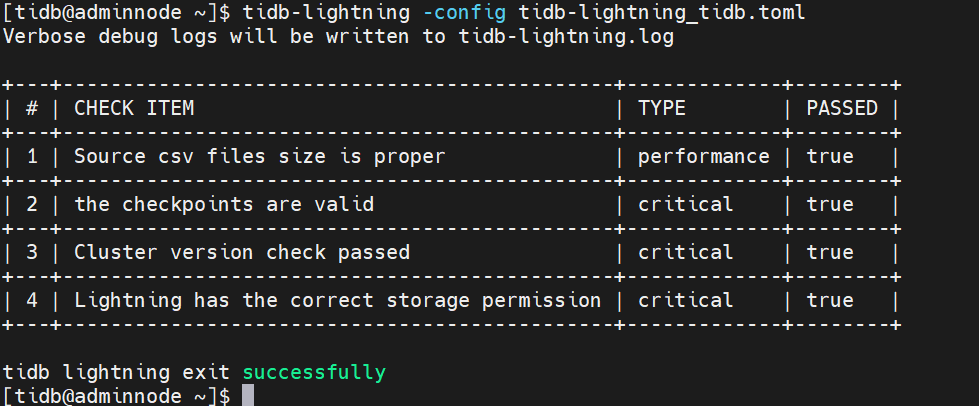
9、启动与退出 TiDB Lightning
#!/bin/bash
nohup ./tidb-lightning -config tidb-lightning.toml > nohup.out &
导入完毕后, TiDB Lightning 会自动退出。
举例:
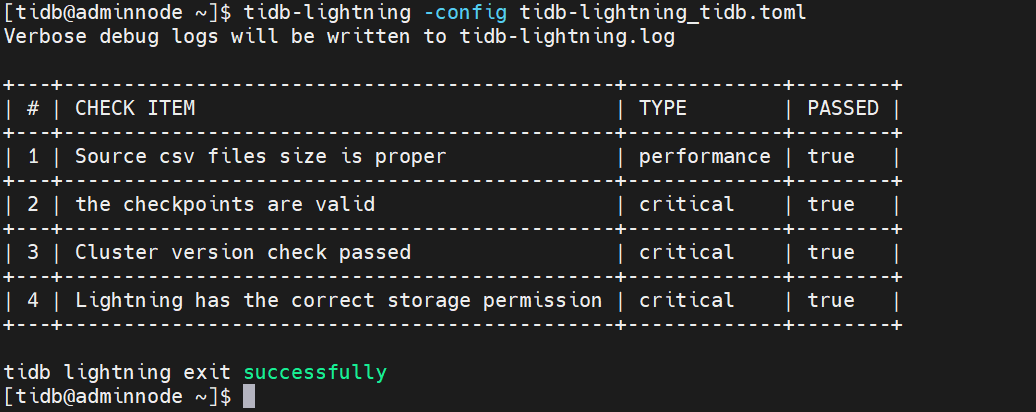
导入前
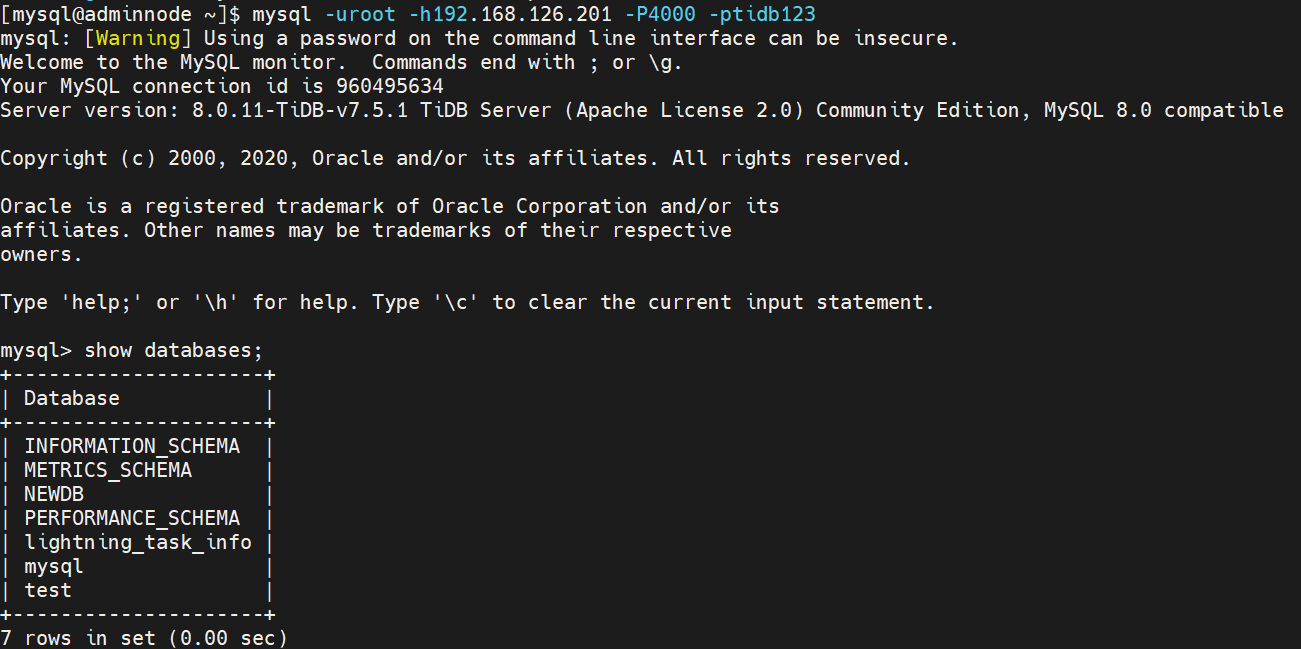

导入数据如下:
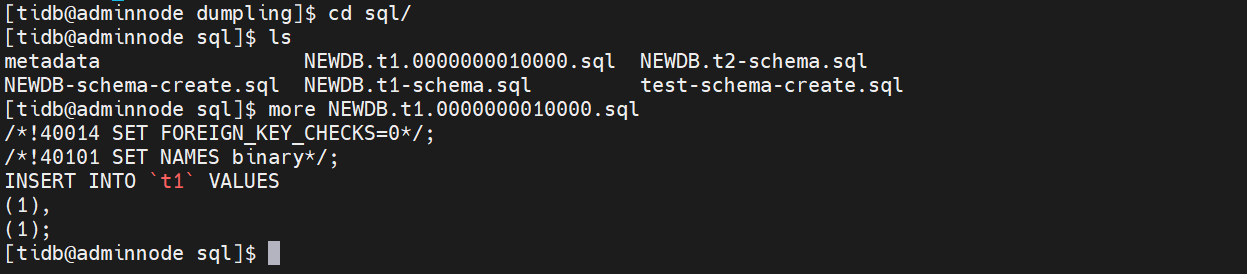
导入后

查看日志导入成功无报错
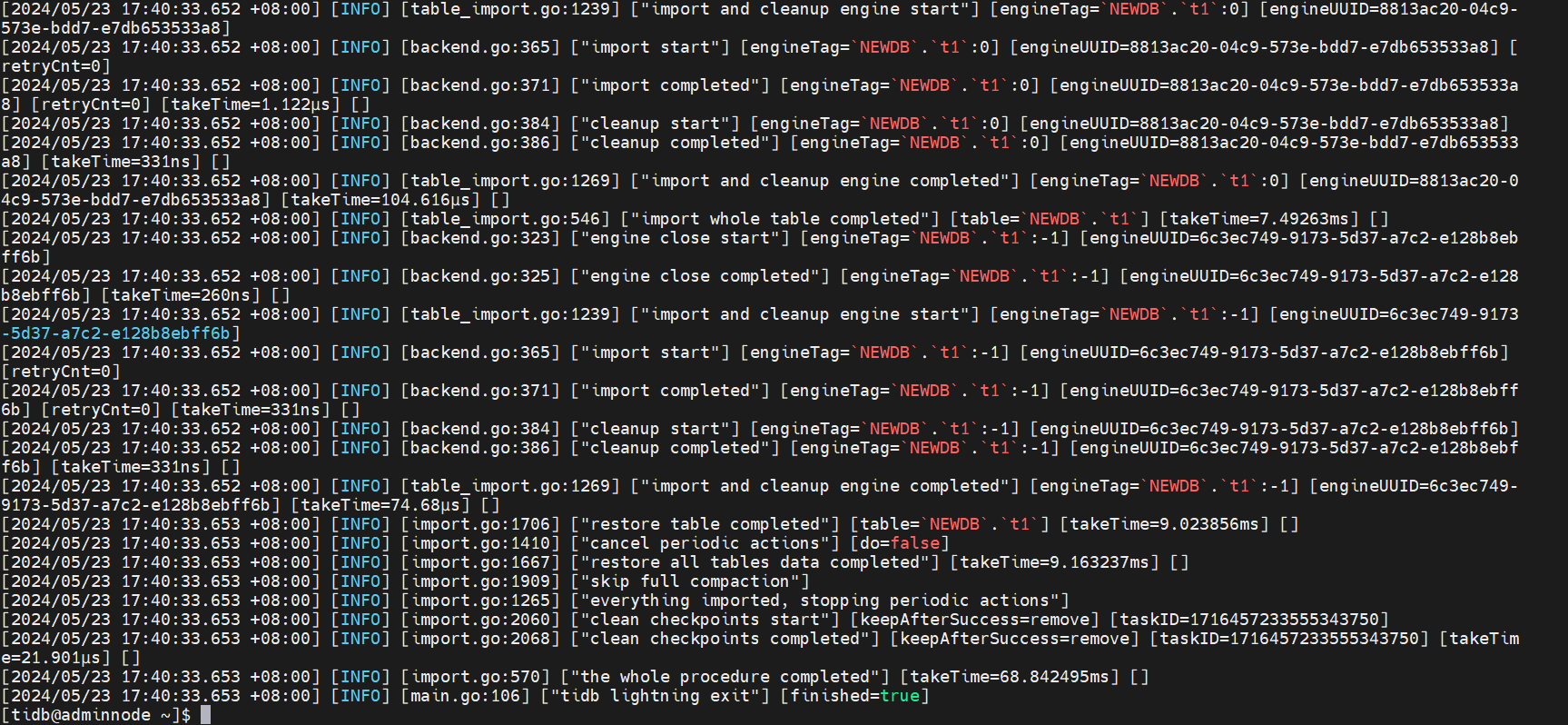
10、TiDB Lightning 数据过滤
- 命令行
./tidb-lightning -f 'foo*.*' -f 'bar*.*' -d /tmp/data/ --backend tidb
- TOML配置文件
[mydumper]
filter = ['foo*.*','bar*.*']
11、TiDB Lightning 断点续传
1.断点续传的启用与配置
[checkpoint]
# 启用断点续传。
#导入时, TiDB Lightning 会记录当前进度。
# 若TiDB Lightning 或其他组件异常退出,在重启时可以避免重复再导入已完成的数据。
enable = true
2.断点的存储
# 存储断点的方式
# - file: 存放在本地文件系统 (要求 v2.1.1 或以上)
# -mysql: 存放在兼容 MySQL 的数据库服务器
driver = "file"
# 若 driver ="mysql",此参数为数据库连接参数 (DSN),格式为“用户:密码@tcp(地址:端口)/”
# 默认会重用 [tidb]设置目标数据库来存储断点。
# 为避免加重目标集群的压力,建议另外使用一个兼容 MySQL的数据库服务器。
#dsn=“/tmp/tidb_lightning_checkpoint.pb"
# 导入成功后是否保留断点。默认为删除。
# 保留断点可用于调试,但有可能泄漏数据源的元数据,
#keep-after-success =false
3.断点续传的控制
tidb-lightning-ctl --checkpoint-error-destroy='`schema`.`table`' / all
tidb-lightning-ctl --checkpoint-error-ignore='`schema`.`table`' / all
tidb-lightning-ctl --checkpoint-remove='`schema`.`table`' / all
--checkpoint-error-destroy: 该命令会让失败的表从头开始整个导入过程。
--checkpoint-error-ignore:这条命令会清除出错状态,忽略之前的错误进行继续导入。传入"all" 会对所有表进行上述操作。
--checkpoint-remove: 无论是否有出错, 把表的断点清除。
12、TiDB Lightning 的 Web 可视化界面管理
TiDB Lightning 支持在网页上查看导入进度或执行一些简单任务管理,这就是 TiDB Lightning 的服务器模式。
启用服务器模式的方式有如下几种:
- 在启动 tidb-lightning 时加上命令行参数 --server-mode。
tiup tidb-lightning --server-mode --status-addr :8289
- 在配置文件中设置 lightning.server-mode。
[lightning]
server-mode = true
status-addr = ':8289'
TiDB Lightning 启动后,可以访问 http://127.0.0.1:8289 来管理程序(实际的 URL 取决于你的 status-addr 设置)。
服务器模式下,TiDB Lightning 不会立即开始运行,而是通过用户在 web 页面提交(多个)任务来导入数据。
第一步:启动服务
命令行参数--server-mode
./tidb-lightning --server-mode --status-add r :8289
配置文件
[lightning]
server-mode = true
status-addr = ':8289'
第二步:提交任务
第三步:查看导入进度
第四步:管理任务

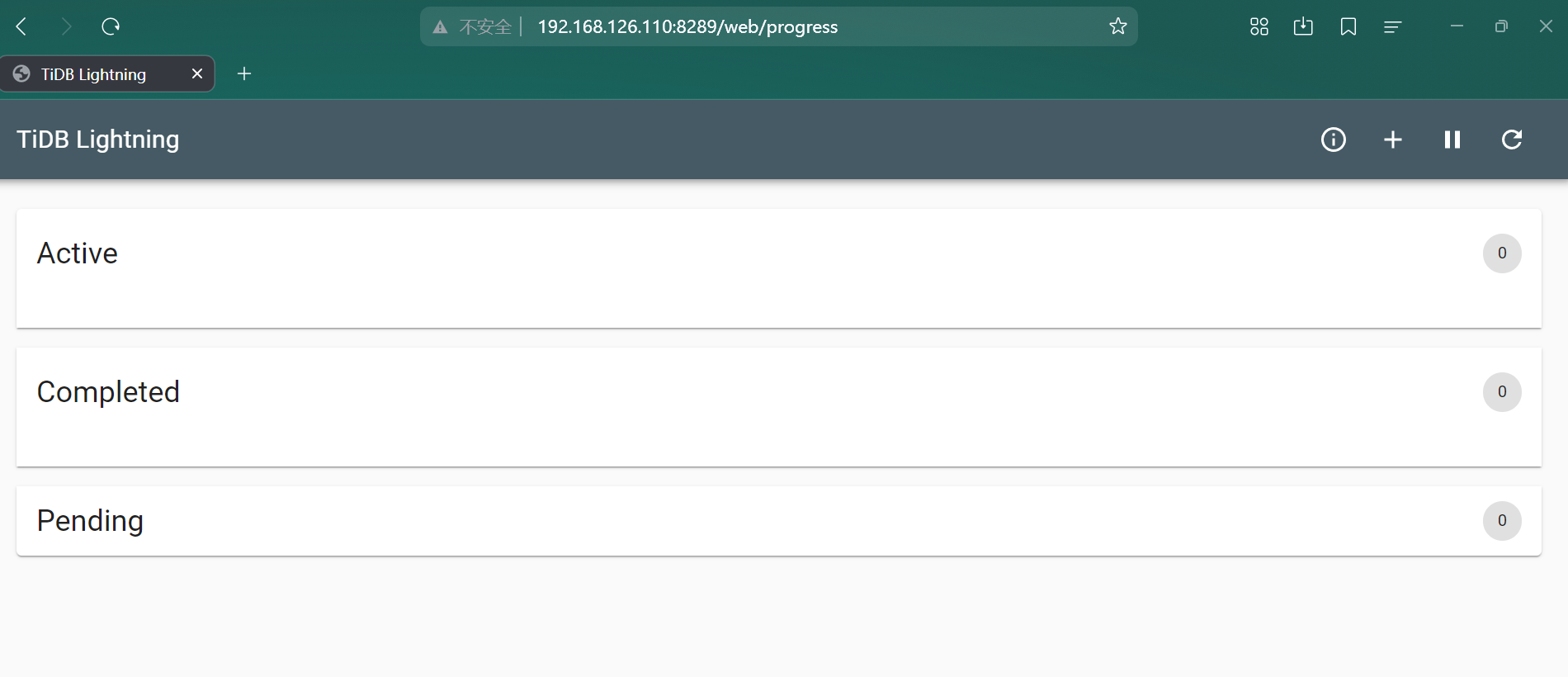
没有大量数据导入本次暂不测试web管理。
九、问题整理
物理导入和逻辑导入一起使用导致报错如下:
tidb lightning encountered error: [Lightning:Checkpoint:ErrInvalidCheckpoint]config 'tikv-importer.backend' value 'tidb' different from checkpoint value 'local', please delete the file '/tmp/tidb_lightning_checkpoint.pb' and remove all restored tables and try again
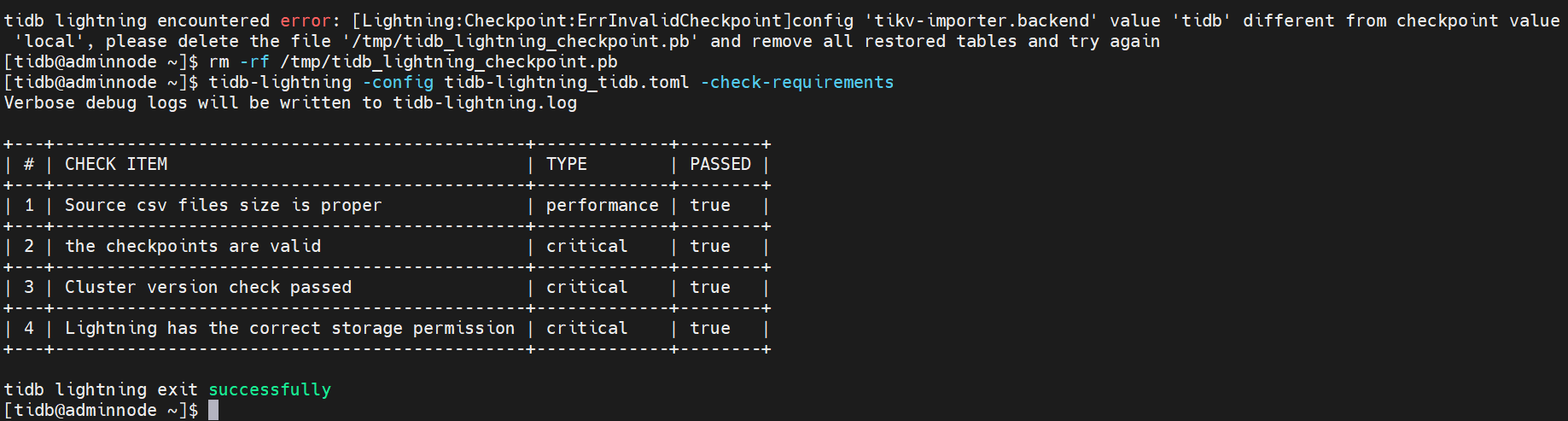
注意:不可同时使用physical import mode和logical import mode导入一个tidb集群
解决办法:
删除Checkpoint文件