





作者:思勉、宙游
在OLAP的业务场景中,不仅要把数据存起来,还需要把数据处理好。在ClickHouse中,为了提高数据处理性能,使用物化视图(Materialized View)是有效的方法之一。本文主要探讨Materialized View(下文称 MV)的工作原理与最佳实践,并介绍了使用过程中容易踩坑的一些问题和解决方案。
物化视图(Materialized View)可以看做是一种特殊的触发器,当数据被插入时,它将数据上执行SELECT查询的结果存储为到一个目标表中。
其设计初衷可以概括为:通过在数据插入时的预处理来加速查询。
CREATE MATERIALIZED VIEW mv TO destAS SELECT a, b, count() AS cntFROM sourceGROUP BY a, b
在使用MV时,需要谨记以下三个原则:
1. 只有源表插入(Insert)才会触发MV的更新。MV不感知对源表的truncate、 alter delete、alter update、 drop partition、 drop table、 rename等所有其他操作。 需要注意两种特殊场景:ReplicatedMergeTree在副本(replica)之间的数据同步(replication)不会触发MV更新,分布式表(Distributed)向其本地表(Local)转发会触发MV更新。
2. MV不会对源表做查询,只会查询本次插入的数据块(insert block)。有个例外是在创建MV时如果指定了populate会对源表执行一次查询并将结果初始化到MV中。
3.1 用于数据预聚合(pre-aggregate)
-- 创建 SummingMergeTree 引擎的目标表CREATE TABLE wikistat_top_projects(`date` Date,`project` LowCardinality(String),`hits` UInt32) ENGINE = SummingMergeTreeORDER BY (date, project);-- 创建物化视图CREATE MATERIALIZED VIEW wikistat_top_projects_mv TO wikistat_top_projects ASSELECTdate(time) AS date,project,sum(hits) AS hitsFROM wikistatGROUP BY date, project;
3.2 数据冗余以支持不同维度的数据查询
3.3 数据提取转换
3.4 配合Kafka或者RabbitMQ引擎
4.1 数据聚合应该使用SummingMergeTree或者AggregatingMergeTree
考虑如下需求,使用MV对源表数据进行聚合,客户错误地使用非聚合引擎(MergeTree)作为MV的目标表。
 错误范例:使用普通MergeTree引擎做聚合
错误范例:使用普通MergeTree引擎做聚合
CREATE TABLE source (a Int64, b Int64)ENGINE = MergeTree PARTITION BY (a) ORDER BY (a,b);-- 目标表错误的使用 MergeTree 引擎CREATE TABLE dest (a Int64, b Int64, cnt Int64)ENGINE = MergeTree PARTITION BY (a) ORDER BY (a,b);-- 创建基于 dest 表创建物化视图CREATE MATERIALIZED VIEW mv to destAS SELECT a, b, count() as cntFROM source GROUP BY a, b;-- 执行源表插入insert into source(a,b) values(1, 1), (1,1), (1,2);insert into source(a,b) values(1, 1), (1,1), (1,2);-- MV 实际查询结果,不符合预期SELECT a,b,count() FROM dest GROUP BY a, b;┌─a─┬─b─┬─count()─┐│ 1 │ 2 │ 2 ││ 1 │ 1 │ 2 │└───┴───┴─────────┘-- 预期的正确结果SELECT a, b, count() as cnt FROM source GROUP BY a, b┌─a─┬─b─┬─sum─┐│ 1 │ 2 │ 2 ││ 1 │ 1 │ 4 │└───┴───┴─────┘
✅ 正确范例1:使用SummingMergeTree
CREATE TABLE source (a Int64, b Int64)ENGINE = MergeTree PARTITION BY (a) ORDER BY (a,b);-- 创建 SummingMergeTree 引擎目标表-- 需要注意这里通过 ORDER BY(a,b ) 指定 a,b 作为SummingMergeTree的聚合键CREATE TABLE dest_2 (a Int64, b Int64, sum UInt64)ENGINE = SummingMergeTree ORDER BY (a, b);-- 创建 MVCREATE MATERIALIZED VIEW mv_2 to dest_2AS SELECT a, b, sum(a) as sumFROM source GROUP BY a, b;insert into source(a,b) values(1, 1), (1,1), (1,2);insert into source(a,b) values(1, 1), (1,1), (1,2);-- 为什么数据并没有根据a,b聚合?-- 这里是因为 SummingMergeTree 是在后台merge时异步进行聚合的select * from mv_2;┌─a─┬─b─┬─sum─┐│ 1 │ 1 │ 2 ││ 1 │ 2 │ 1 ││ 1 │ 1 │ 2 ││ 1 │ 2 │ 1 │└───┴───┴─────┘-- 因此查询 SummingMergeTree 时,需要添加 group byselect a,b,sum(a) as sum from mv_2 group by a;┌─a─┬─b─┬───sum──┐│ 1 │ 1 │ 2 ││ 1 │ 2 │ 4 │└───┴───┴────────┘-- 或者手动执行 optimize table,手动触发 SummingMergeTree 的聚合optimize table dest_2 final;-- optimize 之后不需要 group byselect * from mv_2;┌─a─┬─b─┬─sum─┐│ 1 │ 1 │ 4 ││ 1 │ 2 │ 2 │└───┴───┴─────┘
✅ 正确范例2:使用AggregatingMergeTree引擎
CREATE TABLE source (a Int64, b Int64)ENGINE = MergeTree PARTITION BY (a) ORDER BY (a,b);-- 创建 AggregatingMergeTree 引擎目标表CREATE TABLE dest_3(a Int64, b Int64,cnt AggregateFunction(count, Int64))ENGINE = AggregatingMergeTree order by (a, b);-- 创建 MVCREATE MATERIALIZED VIEW mv_3 TO dest_3 ASSELECT a, b, countState(a) AS cntFROM source GROUP BY a, binsert into source(a,b) values(1, 1), (1,1), (1,2);insert into source(a,b) values(1, 1), (1,1), (1,2);-- 使用 Merge 进行查询select a,b,countMerge(cnt) from mv_3 group by a,b;┌─a─┬─b─┬─countMerge(cnt)─┐│ 1 │ 2 │ 2 ││ 1 │ 1 │ 4 │└───┴───┴─────────────────┘
4.2 聚合引擎需要注意排序键(ORDER BY)与SQL中聚合键(GROUP BY)保持一致
使用SummingMergeTree时,需要注意其排序键(ORDER BY)和 GROUP BY 聚合字段保持一致。

4.3 始终谨记MV同步只会查询Insert Block,不会查询原表
如下面的MV定义中,每次插入只会对插入的数据执行SELECT查询,而不是查询source整张表。

4.4 MV的字段名需要与查询结果字段完全一致

4.5 MV和ReplicationMergeTree结合
使用过程中需要注意:
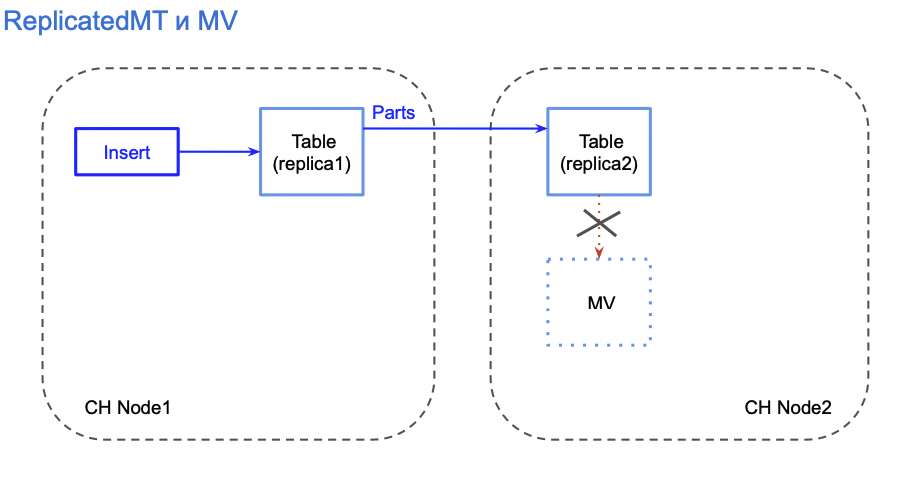
如下图,数据同步的过程如下:
1. 在 Node1 中执行插入,数据写入本副本的Table;
2. Insert 操作同步进行本副本内 MV 的同步;
3. ReplicatedMergeTree 会将数据同步到 Node2 的 Table 中;
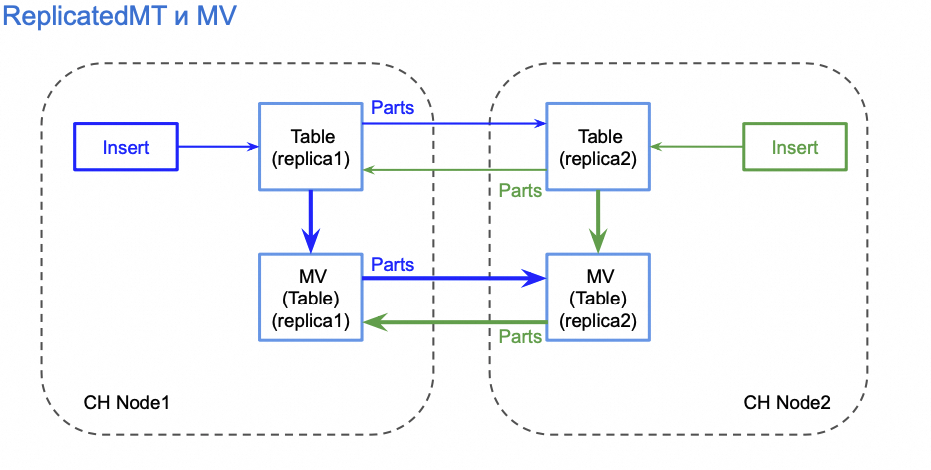
如果对 ReplicatedMergeTree 执行 Populate 操作时,会触发数据重复。
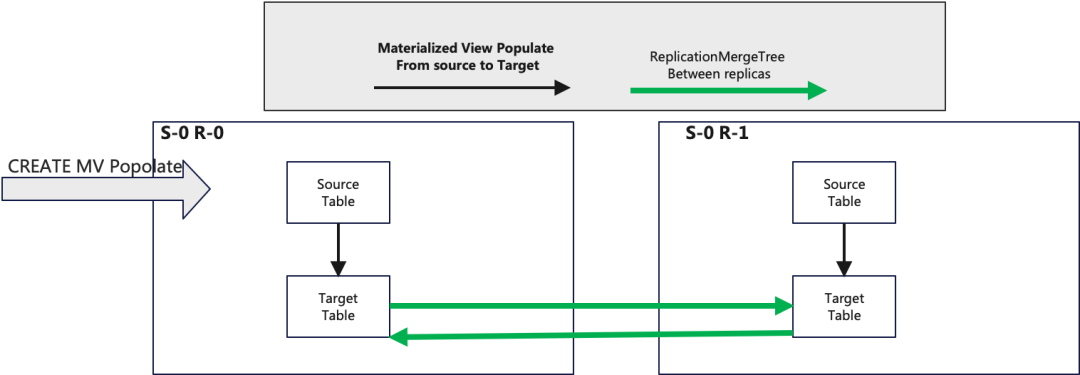
关于该问题细节可以参考 :
4.6 MV和JOIN
CREATE MATERIALIZED VIEW mv1 TO destSELECT ...FROM source left join some_dimension on (...)CREATE MATERIALIZED VIEW mv2 TO destSELECT ...FROM some_dimension right join source on (...)
4.7 MV和Distributed Table
可以分成四种情况分别讨论:
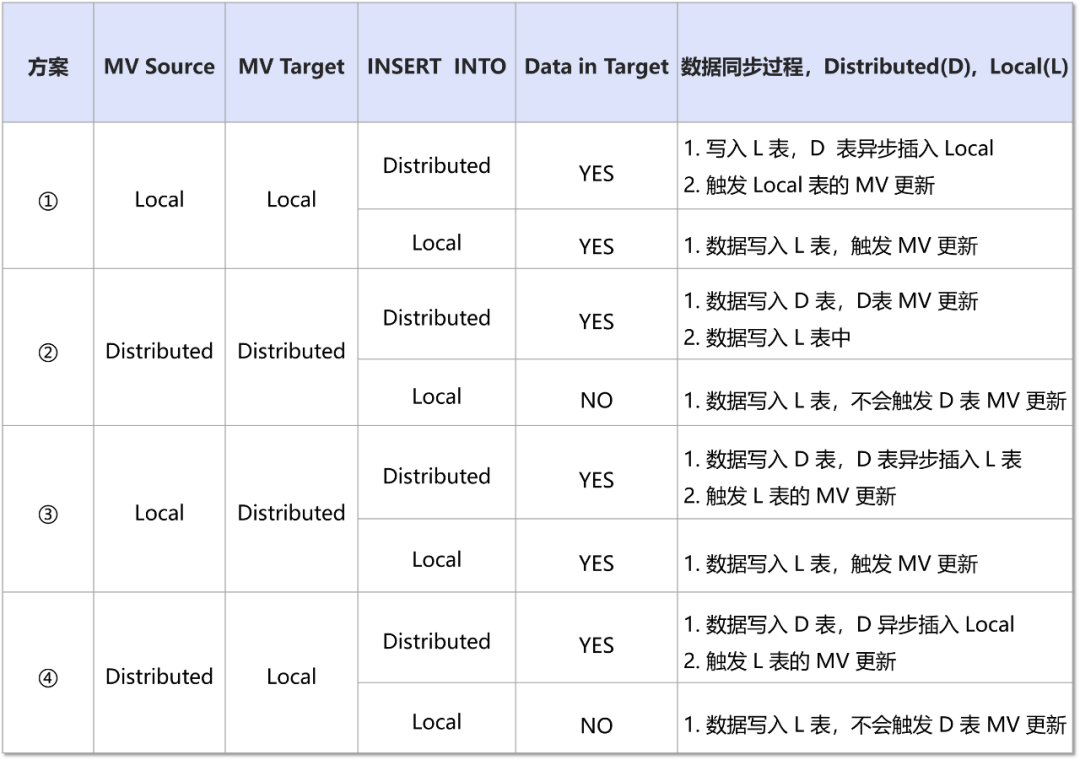
其中方案②如果数据实际执行写入到Local表中,则会导致MV中的数据不同步。
阿里云ClickHouse企业版已于4月26日正式商业化,并推出了指定规格资源包首购优惠的折扣活动:首次购买规格在3000-9500CCU*H的计算包,以及首次购买1个月450G及以下规格的存储包,均可享 0.4折 的超优惠价格!首次计算和存储资源组合购买不超过99.58元,欢迎登录阿里云ClickHouse官网进行选购。
🔍 复制搜索以下链接即刻体验:
计算包:
附录
[1]https://clickhouse.com/blog/using-materialized-views-in-clickhouse
[2]https://developer.aliyun.com/article/1327456
[3]https://dencrane.github.io/Everything_you_should_know_about_materialized_views_commented.pdf
[5]https://github.com/ClickHouse/ClickHouse/issues/8336




 点击了解 云数据库ClickHouse 详情
点击了解 云数据库ClickHouse 详情