





生成式人工智能 (Gen AI) 是未来 5 到 10 年内将改变企业的顶级新兴趋势之一。这波人工智能创新浪潮的核心是处理大量不同数据集的大型语言模型 (LLM)。LLM 让人们可以通过自然语言文本或语音与人工智能模型进行交互。
LLM 研发方面的投资和活动显著增加,导致现有模型更新,并发布了 Gemini(原 Bard)、Llama 2、PaLM 2、DALL-E 等新模型。其中一些是开源的,而另一些则是 Google、Meta 和 OpenAI 等公司的专有模型。在未来几年内,Gen AI 的价值将由针对每个企业和行业独有的微调和定制领域特定模型驱动。使用 LLM 的另一个重大发展是检索增强生成 (RAG),其中 LLM 附加到大型和多样化的数据集,以便企业可以与 LLM 交互数据。Broadcom 旗下的 VMware 提供的软件可对全球最复杂的组织在数据中心、所有云、任何应用程序以及企业边缘的工作负载进行现代化改造、优化和保护。VMware Cloud Foundation 软件可帮助企业创新和转型业务,并采用广泛的 AI 应用和服务。VMware Cloud Foundation 通过自助式自动化 IT 环境提供统一平台来管理所有工作负载,包括虚拟机、容器和 AI 技术。
2023 年 8 月,在拉斯维加斯举行的 VMware Explore 上,我们与 NVIDIA 宣布推出 VMware Private AI 和 VMware Private AI Foundation。
在2024年3月18日的 NVIDIA GTC,我们很高兴地宣布与 NVIDIA 合作推出 VMware Private AI Foundation。
VMware 与 NVIDIA 合作的Private AI Foundation
博通和 NVIDIA 旨在通过与 NVIDIA 联合打造的 GenAI 平台——VMware Private AI Foundation 来释放 Gen AI 的潜力并提高生产力。
在业界领先的私有云平台 VMware Cloud Foundation 上构建和运行,基于 NVIDIA 的 VMware Private AI Foundation 包含全新 NVIDIA NIM 推理微服务、来自 NVIDIA 和社区其他成员的 AI 模型(如 Hugging Face)以及 NVIDIA AI 工具和框架,可通过 NVIDIA AI Enterprise 许可证使用。
该联合 Gen AI 平台使企业能够运行 RAG 工作流、微调和自定义 LLM 模型,并在其数据中心运行推理工作负载,从而解决隐私、选择、成本、性能和合规性问题。它通过提供直观的自动化工具、深度学习 VM 映像、矢量数据库和 GPU 监控功能,简化了企业的 Gen AI 部署。该平台是 VMware Cloud Foundation 上的附加组件。请注意,NVIDIA AI Enterprise 许可证需要单独从 NVIDIA 购买。
主要优势
让我们了解 VMware Private AI Foundation 与 NVIDIA 合作的主要优势:

实现 AI 模型的隐私、安全性和合规性:VMware Private AI Foundation with NVIDIA 为 AI 服务提供了一种架构方法,可实现企业数据的隐私、安全性和控制,以及更集成的安全性和管理。VMware Cloud Foundation 提供高级安全功能,例如安全启动、虚拟 TPM、VM 加密等。NVIDIA AI Enterprise 服务包含用于工作负载和基础架构利用的管理软件,以扩展 AI 模型的开发和部署。AI 软件堆栈包含 4,500 多个开源软件包,其中包括第三方和 NVIDIA 软件。NVIDIA AI Enterprise 服务的一部分包括针对关键和高 CVE(常见漏洞和暴露)的补丁,其中包括生产分支和长期支持分支,以及整个堆栈的 API 兼容性维护。VMware Private AI Foundation with NVIDIA 支持本地部署,为企业提供控制,使其能够轻松应对许多法规合规性挑战,而无需对现有环境进行大规模重新架构。
在任意LLM模型都能获得 GenAI 模型的加速性能:Broadcom 和 NVIDIA 已启用软件和硬件功能,以最大限度地提高 GenAI 模型的性能。这些集成功能内置于 VMware Cloud Foundation 平台中,包括 GPU 监控、实时迁移和负载平衡;即时克隆(能够在几秒钟内部署预加载模型的多节点集群)、GPU 虚拟化和池化以及使用 NVIDIA NVLink 和 NVIDIA NVSwitch 扩展 GPU 输入/输出。最新的基准研究将 VMware + NVIDIA AI-Ready Enterprise Platform 上的 AI 工作负载与裸机进行了比较。结果显示,性能与裸机相似,有时甚至更好。因此,将 AI 工作负载放在虚拟化解决方案上可以保持性能,同时增加虚拟化的优势,例如易于管理和增强安全性。NVIDIA NIM 允许企业在一系列优化的 LLM 上运行推理,从 NVIDIA 模型到社区模型(如 Llama-2)再到开源 LLM(如 Hugging Face),性能卓越。
简化 GenAI 部署并优化成本:VMware Private AI Foundation 与 NVIDIA 相结合,使企业能够简化部署并为其 Gen AI 模型实现经济高效的解决方案。它提供的功能包括用于启用 RAG 工作流的矢量数据库、深度学习虚拟机、快速启动自动化向导,帮助企业获得简化的部署体验。该平台提供统一的管理工具和流程,可大幅降低成本。这种方法可以虚拟化和共享基础架构资源,例如 GPU、CPU、内存和网络,从而大幅降低成本,尤其是对于可能不需要完整 GPU 的推理用例。
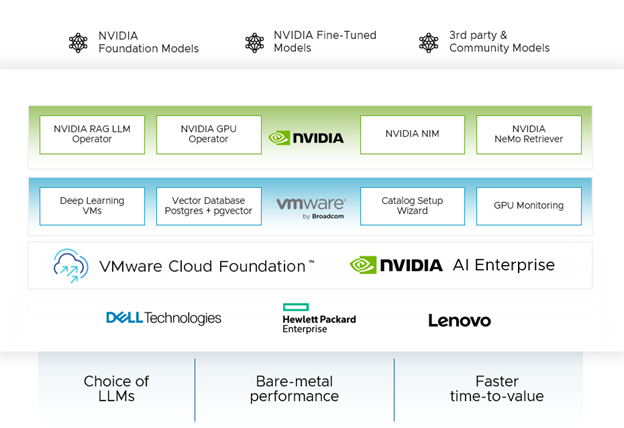
全栈私有云基础架构解决方案 VMware Cloud Foundation 和端到端云原生软件平台 NVIDIA AI Enterprise 构成了 VMware Private AI Foundation with NVIDIA 平台的基石。它们共同为企业提供推出私有且安全的 Gen AI 模型的能力。
需要重点强调的关键功能
VMware 设计的特殊功能
深度学习 VM 模板:配置深度学习 VM 可能是一个复杂且耗时的过程。手动创建可能会导致缺乏一致性,从而导致不同开发环境中的优化机会。带有 NVIDIA 的 VMware Private AI Foundation 提供预先配置了所需软件框架(如 NVIDIA NGC、库和驱动程序)的深度学习 VM,从而减轻了用户设置每个组件的负担。
用于支持 RAG 工作流的矢量数据库:矢量数据库对于 RAG 工作流非常重要。它们支持快速查询数据和实时更新,以增强 LLM 的输出,而无需重新训练这些 LLM,这可能非常昂贵且耗时。这些已成为 GenAI 和 RAG 工作负载的事实标准。VMware 通过利用 PostgreSQL 上的 pgvector 启用了矢量数据库。此功能通过 VMware Cloud Foundation 中数据服务的原生基础架构自动化和管理体验进行管理。数据服务管理器通过单一界面简化了开源和商业数据库的部署和管理。
目录设置向导:AI 项目的基础设施配置涉及几个复杂的步骤。这些步骤由 LOB 管理员执行,他们专门选择和部署适当的 VM 类、Kubernetes 集群、vGPU 和 AI/ML 软件,例如 NGC 目录中的容器。在大多数企业中,数据科学家和 DevOps 花费大量时间来组装 AI/ML 模型开发和生产所需的基础设施。由此产生的基础设施可能不合规且无法跨团队和项目扩展。即使采用精简的 AI/ML 基础设施部署,数据科学家和 DevOps 也可能需要花费大量时间等待 LOB 管理员设计、整理和提供必要的 AI/ML 基础设施目录对象。为了应对这些挑战,VMware Cloud Foundation 引入了目录设置向导,这是一项新的私有 AI 自动化服务功能。在第 0 天,LOB 管理员可以通过 VMware Cloud Foundation 的自助服务门户高效地设计、整理和提供优化的 AI 基础设施目录项。发布后,DevOps 和数据科学家可以轻松访问机器学习 (ML) 目录项并以最少的努力进行部署。目录设置向导通过简化创建可扩展且一致的基础架构的过程,减少了管理员的手动工作量并缩短了 DevOps 和数据科学家的等待时间。
GPU 监控:通过了解 GPU 使用情况和性能指标,组织可以做出明智的决策,以优化性能、确保可靠性并管理 GPU 加速环境中的成本。随着 VMware Private Foundation 与 NVIDIA 的推出,我们很高兴在 VMware Cloud Foundation 中引入 GPU 监控功能。这提供了跨集群和主机的 GPU 资源利用率视图以及现有的主机内存和容量控制台。这使管理员能够 优化 GPU 使用情况,从而优化性能和成本。
NVIDIA AI Enterprise 的精彩功能
NVIDIA NIM:NVIDIA NIM 是一组易于使用的微服务,旨在加速企业中 Gen AI 的部署。这款多功能微服务支持 NVIDIA AI Foundation Models - 范围广泛的模型,从领先的社区模型到 NVIDIA 构建的模型,再到针对 NVIDIA 加速堆栈优化的定制 AI 模型。NVIDIA NIM 建立在 NVIDIA Triton 推理服务器、NVIDIA TensorRT、TensorRT-LLM 和 PyTorch 的基础上,旨在促进大规模无缝 AI 推理,帮助开发人员灵活而有把握地在生产中部署 AI。
NVIDIA Nemo Retriever:NVIDIA NeMo Retriever 是 NVIDIA NeMo 平台的一部分,是 NVIDIA CUDA-X Gen AI 微服务的集合,使组织能够将自定义模型无缝连接到各种业务数据并提供高度准确的响应。NeMo Retriever 提供世界一流的信息检索,具有最低的延迟、最高的吞吐量和最大的数据隐私,使组织能够更好地利用其数据并实时生成业务洞察。NeMo Retriever 通过增强的 RAG 功能增强了 GenAI 应用程序,无论业务数据位于何处,它都可以连接到业务数据。
NVIDIA RAG LLM Operator: NVIDIA RAG LLM Operator 可轻松将 RAG 应用程序部署到生产中。该操作简化了使用 NVIDIA AI 工作流示例开发的 RAG 管道部署到生产中的流程,无需重写代码。
NVIDIA GPU Operator: NVIDIA GPU Operator 可自动管理将 GPU 与 Kubernetes 结合使用所需的软件的生命周期。它可实现高级功能,包括更好的 GPU 性能、利用率和遥测。GPU Operator 使组织能够专注于构建应用程序,而不是管理 Kubernetes 基础架构。
兼容主流OEM服务器
该平台可被戴尔、HPE 和联想等主流服务器OEM所兼容。
