




点击上方蓝字关注我们

人们对自然语言大模型ChatGPT等的态度可以说是冰火两重天:一方面大量消费者应用开始接入大模型,好不热闹;
而另一方面,包括包括苹果、亚马逊、Verizon、摩根大通、德意志银行、诺斯鲁普格鲁曼公司、三星和埃森哲等企业却宣布禁止其员工使用。
企业市场对自然语言大模型的要求与消费者市场截然不同,如果大模型的准确度只有90%,企业只能把它当作游戏来玩。
另外一个原因是担心部署像 ChatGPT 这样的外部自然语言大模型,可能导致敏感数据被传输和存储在企业安全环境之外,造成信息泄露。
生成式AI在企业中的有效性取决于在公司自身数据上成功训练大模型(LLM)的能力,包括从电子邮件到财务报表的所有内容,确保AI对话更加准确和相关。
然而,企业数据的私有性以及严格遵守数据隐私、治理和法规遵从性的需求带来了重大挑战。管理不善,可能导致代价高昂的后果,如数据泄露和品牌受损。



1.AGI:企业不能接受的5大理由

一年前的3月15日,随着OpenAI多模态预训练大模型GPT-4的发布,国内包括百度、华为、腾讯等科技巨头,星环科技、百川智能等初创企业,以及智谱AI研究院等研究机构纷纷扬帆起航,投身到人工智能(AI)大模型开发,开启“百模大战”。
据媒体不完全统计,截至今年4月底,国内共计推出了305个大模型。而截至5月16日,只有约140个大模型完成生成式人工智能服务备案,占发布总量的45.9%。
“百模大战”最终留下3~5家通用大模型(AGI),似乎已经成为行业对于这场竞赛最终结局的共识。
对于企业而言,对于像ChatGPT 这样的通用大模型难以接受的理由主要包括:
准确性不高
为了获得准确的结果,使用特定于业务的数据微调AI模型至关重要。
然而,OpenAI目前还没有提供一种直接用这些数据训练ChatGPT的方法。用户必须开发自己的提示,完成针对孤立的 GPT-3.5 模型进行训练,该模型既不能与其他客户共享,也不用于训练其他模型。
在引入大模型之前,必须对微调数据进行适当的分类、准备、标记,如果敏感,则可能去标识化。OpenAI 会无限期保留上传用于微调的数据,直到客户删除文件。
透明度很低
人工智能领域通常坚持高标准的开放性,以促进学习和改进。然而,随着GPT-4 的发布,OpenAI选择将其源代码专用于同行评审,并隐瞒技术细节。
这种缺乏透明度阻碍了研究人员和数据科学家验证和确认结果,这对需要完全透明和开源访问以进行全面评估的企业构成了挑战。

消费者数据隐私不能保障
ChatGPT通过数据隐私协议(DPA)处理消费者数据隐私,以满足GDPR请求。但是,DPA并未完全涵盖关键行业法规所需的更复杂的数据隐私要求,例如医疗保健的PHI/HIPAA、信用卡处理的PCI/DSS,或金融服务的SEC和FINRA。尽管某些法规(如FINRA)禁止某些形式的衍生数据处理,但将衍生数据排除在DPA 保护之外,引发了额外的担忧。
安全性措施跟不上
OpenAI及其云合作伙伴保持高安全标准,但ChatGPT的专有性质及其数据使用引发了对数据泄露和泄露的担忧。
目前,OpenAI不提供企业级安全功能,例如细粒度、基于角色的访问控制和主动“权限管理”解决方案。OpenAI 平台上缺乏端到端加密意味着OpenAI 员工可以访问数据和对话,并且没有数据掩码或敏感数据发现工具等数据混淆解决方案来帮助数据准备。
数据治理负担重
有效的企业数据管理需要遵守广泛的行业和政府法规。除了信息生命周期管理(ILM)和SOC 2合规性之外,企业数据还必须遵守PHI/HIPAA、PCI-DSS、SEC、FINRA、FDA和FISMA等标准。像欧盟2021年的AI法案和美国的AI权利法案这样的AI特定法规不断演变,增加了复杂性。
面对这些挑战,企业正在部署新的基础设施解决方案,以满足生成性AI应用程序的数据驱动需求。为了管理暴露企业数据的风险,必须采取严格的数据保护措施,以确保在利用AI技术的好处的同时,满足消费者数据隐私和安全目标。
各个行业的公司可能需要考虑运行自己的私有LLM,以满足监管合规义务。支持机器学习和高级数据准备以安全训练模型的云数据管理平台变得越来越重要。在这些平台中跟踪工作流、实验、部署和相关工件,可以实现机器学习操作(MLOps)的集中模型注册表,并提供监管监督所需的审计轨迹、可复现性和控制。
AI数据结构需要包括端到端安全、数据隐私、实时处理、数据治理、元数据管理、数据准备和机器学习在内的全套数据工程能力。无论是利用私有LLM,还是像ChatGPT这样的公共模型,集中的MLOps确保数据工程师能够控制整个机器学习生命周期。
企业界对生成式AI和机器学习的兴趣激增,但企业运营将需要数据治理标准和保护措施,以确保企业AI的未来安全无虞。

2.行业大模型:4个营之道
企业将大模型的应用希望放在了行业大模型上。腾讯研究院发布《向AI而行,共筑新质生产力——行业大模型调研报告》,对行业大模型发展中核心问题,都有精彩的解读。
专家观点:
中国工程院院士邬贺铨认为,人工智能大模型正在催生新一轮技术创新与产业变革,也将为工业、金融、广电等行业数字化转型和高质量发展带来新动能。当前市场以基础大模型为主,通识能力强,但缺少行业专业知识。如何将大模型融入千行百业,是下一阶段的发展重点。
腾讯集团高级执行副总裁汤道生说,这几年通用大模型技术快速发展,展现出越来越强的智能,但很多传统行业应用推进得其实并不快,因为企业有大量的具体问题解决不好。
对企业而言,大模型应用需要综合考虑行业专业性、数据安全、持续迭代和综合成本等多种因素。
基于行业大模型,构建自己的专属模型,也许是企业更优的选项,尤其大部分企业的算力、数据等资源有限。
Hugging Face 高级工程师 王铁震则认为,一方面,大公司在算力、数据、资金等方面拥有天然的竞争优势,但是场景理解不足;另一方面,因为通用大模型对算力和数据量的高需求,许多企业无力承担。
不管是技术供给还是需求方的人士,共同推进生成式 AI 模型的能力开放,让普通开发者,也能够通过不同的技术组合,将生成式 AI 应用到产品开发和工作流程中。
发展特点:
行业大模型既有模型,也含应用。通用大模型侧重发展通识能力,行业大型则侧重发展专业能力。从行业实践看,行业大模型不仅指开发一个行业专用的型本身,更多还包括基于通用大模型调整和开发的行业应用。
因此,广义上行业大模型可以归纳为:利用大模型技术,针对特定数据和任务进行训练或优化,形成具备专用知识与能力的大模型及应用。
此外,国际上更多用垂直模型(VerticalModel)或垂直人工智能(Vertical Al)来表示,国内还有用垂类模型、领域模型专属模型等称谓,都可以认为与行业大模型等同或包含在内。
行业大模型大多生长于通用大模型之上。行业大模型大多在通用大模型基础上构建。通过对通用大模型进行提示工程、检索增强生成、精调、继续预训练/后训练等方式,模型能够更好地处理特定数据或任务,从而生成行业大模型的版本(模型有变)或具备行业大模型的功能(模型不变)。
今天市场上很多行业大模型,如金融、法律、教育、传媒、文旅等,大多是在Llama、SD、GLM、Baichuan 等国内外主流开源大模型基础上构建。
行业大模型的本质是解决方案。行业大模型通常需要针对特定数据和任务进行定制开发或调整。行业大模型面向的是 B端客户,每个客户都有独特的业务、数据、流程等,需要用大模型解决的具体问题也普遍存在个性化需求。因此,厂商提供的行业大模型不仅是产品和工具,更需要有定制服务与支持,甚至需要客户参与共建。可以这样理解,行业大型中的产品通常是“毛坯房”,客户需要根据自身用途进行“装修”才能满足需要。

实现方法
行业大模型的构建和应用中,由于需求和目标不同,技术实现复杂性差异也较大通过调研总结,目前机构在使用大模型适配行业应用过程中,从易到难主要有提示工程、检索增强生成、精调、预训练四类方式。
在机构的具体实践中,通常不会只用一种方式,而会组合使用,以实现最佳效果。例如,一个高质量的智能问答系统,会综合使用提示工程、检索增强生成和精调等方式。
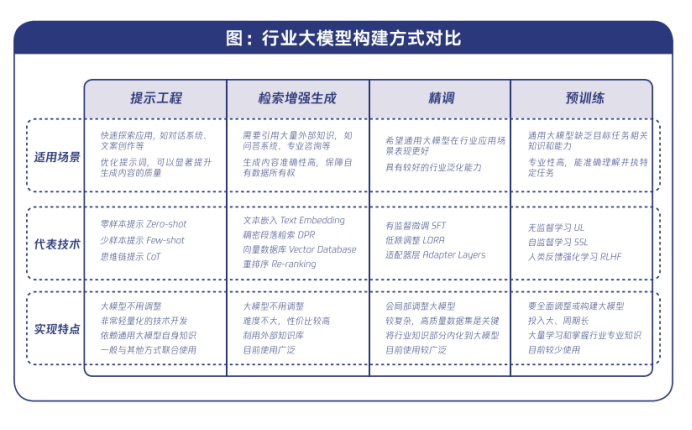
图片来源:《向AI而行,共筑新质生产力——行业大模型调研报告》
未来方面
人工智能+”促进行业大模型应用提速,多模态大模型为数实融合打开新空间,三 Al Agent 有望为各行业注入生产力,行业大模型将出现更多的端侧形态,云智能一体支持行业大模型加速落地。
参考资料:
·https://www.datanami.com/2024/05/10/top-five-reasons-why-chatgpt-is-not-ready-for-the-enterprise/
·https://mp.weixin.qq.com/s/dxtKDqch3wMlW781exb51w
·向AI而行,共筑新质生产力——行业大模型调研报告》
相关文章
·AIGC 洞察系列:首席人工智能官?没错!没有CAIO的公司将更大被动!
·AIGC 洞察系列:会自动写大模型来了代码的AI大模型来了!业务人员将要替代程序员?软件开发革命开始了!
·AIGC 洞察系列:软件接入大模型代表着未来,甲骨文三层策略,微软阿里全产品接入大模型,星环科技兼顾行业大模型和软件,用友金蝶浪潮推企业服务大模型
·AIGC 洞察系列:怎样抓住大模型的尾巴?数据云Snowflake这样做!

识别图中二维码
关注我们
END
