





作者:陈浩、章颖强


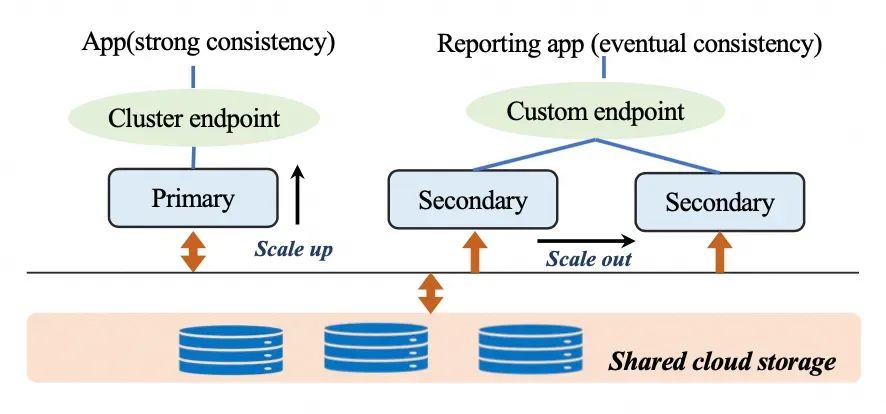
由于Serverless数据库可以提供高弹性并且支持按需付费,最近几年Serverless数据库变得越来越流行。Serverless数据库可以根据用户负载动态地细粒度地调整数据库资源,用户只需要为实际使用的资源付费。这种方式可以为用户节省大量费用。目前主流的商业Serverless数据库(如Aurora Serverless)主要是采用基于共享存储的主从架构。在该架构中,主从节点共享一份数据。所以,因此,新增从节点时不需额外的存储开销。由于只有主节点可以处理写请求,主节点在处理写请求时会生成redo日志并传输至从节点,从节点通过回放redo日志更新其内存中的数据。由于redo日志的传输和回放均为异步操作,从节点的内存数据可能滞后于主节点,导致从节点在处理读请求时可能返回过期的数据。因此,对于需要保证写后读一致性的读请求必须要在主节点上处理。
主从架构的数据库中,由于只有一个主节点可以处理写请求,所以当需要提升写能力时,需要向上弹升主节点。弹升主节点可能会面临一个问题,当前物理主机上没有足够的空闲资源来完成当前实例的向上弹升。这个时候需要将该实例迁移至另外一个有足够空闲资源的物理主机,以完成向上弹升。然而,实例迁移通常导致服务暂时不可用,这在应用的高峰期尤其不可接受,特别是向上弹升通常发生在应用的业务高峰期。为了避免实例迁移或者降低触发迁移的概率,一部分Serverless数据库会给物理机预留大量的空闲资源以应对潜在的迁移,但是这样会造成资源的浪费。还有一部分Serverless数据库通过限制单个实例的最大规格来减少迁移触发的概率,但是这样就违背的Serverless的基本原则,无法在应用业务压力变大时,弹升实例以提供更高的吞吐。
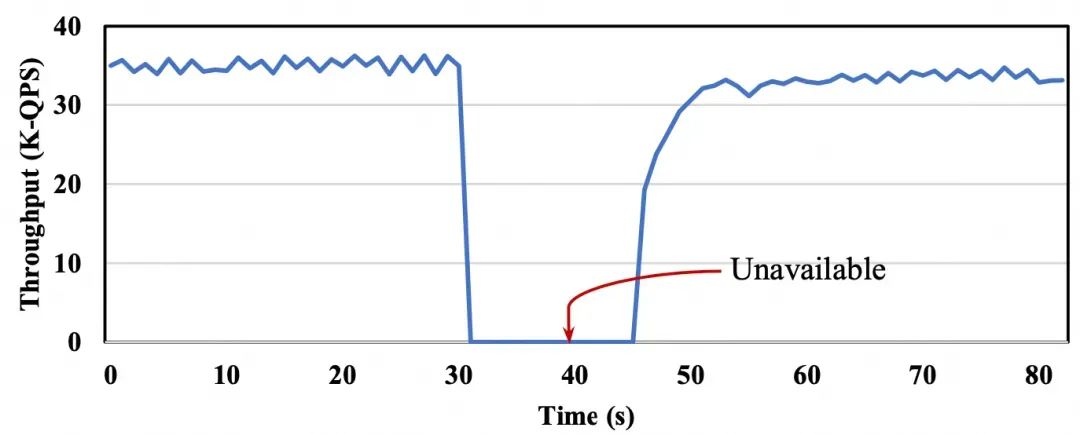
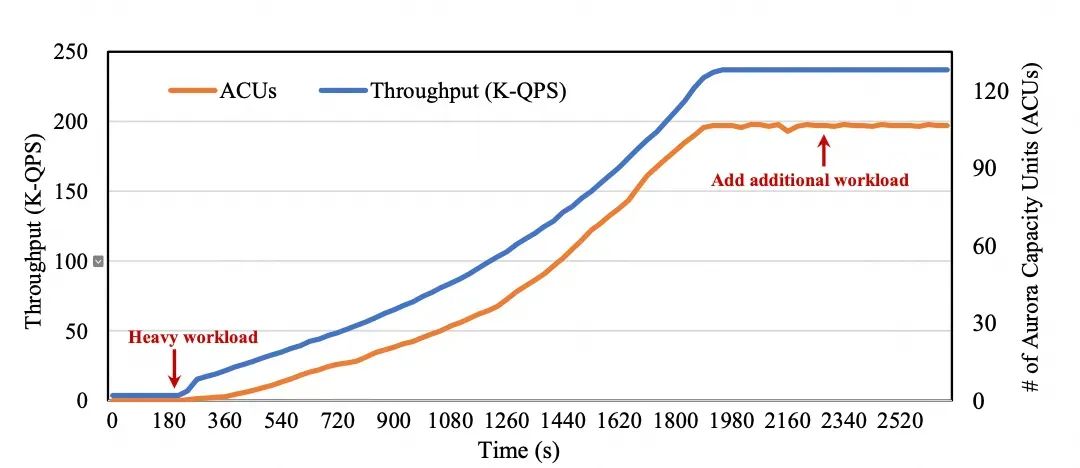
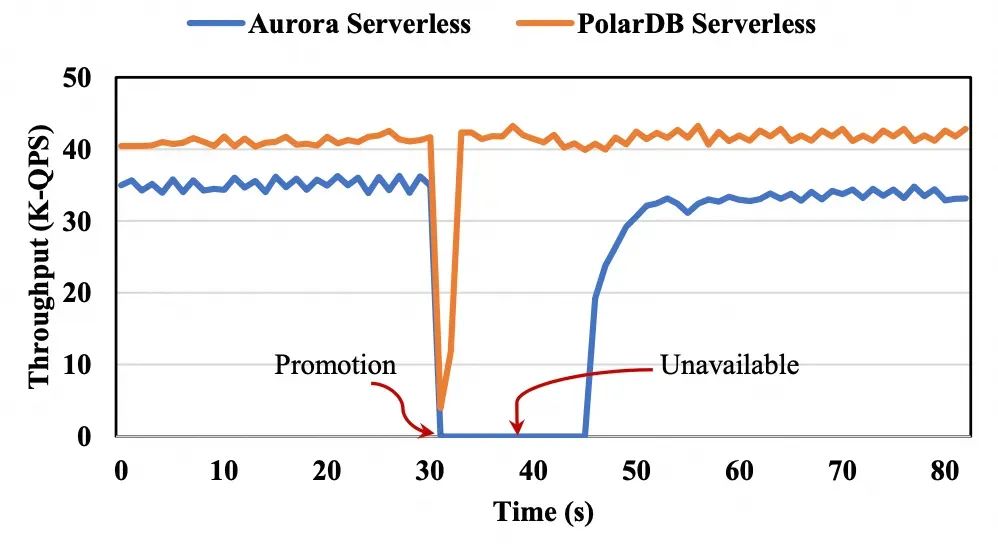
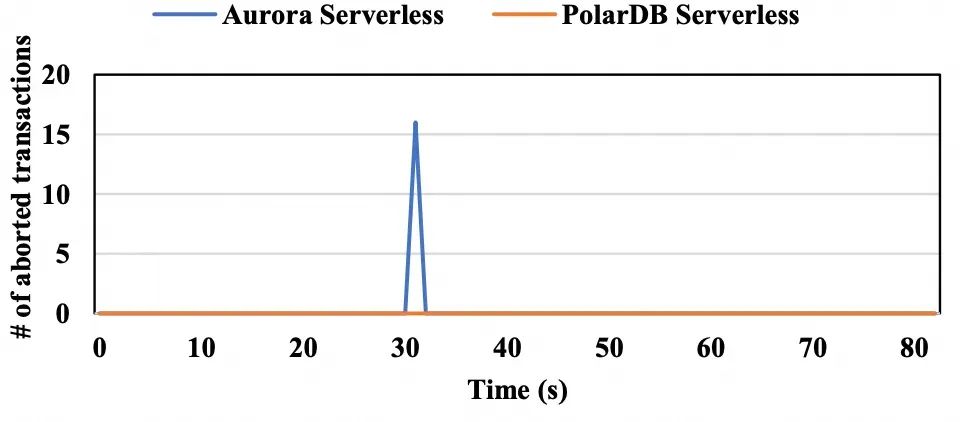
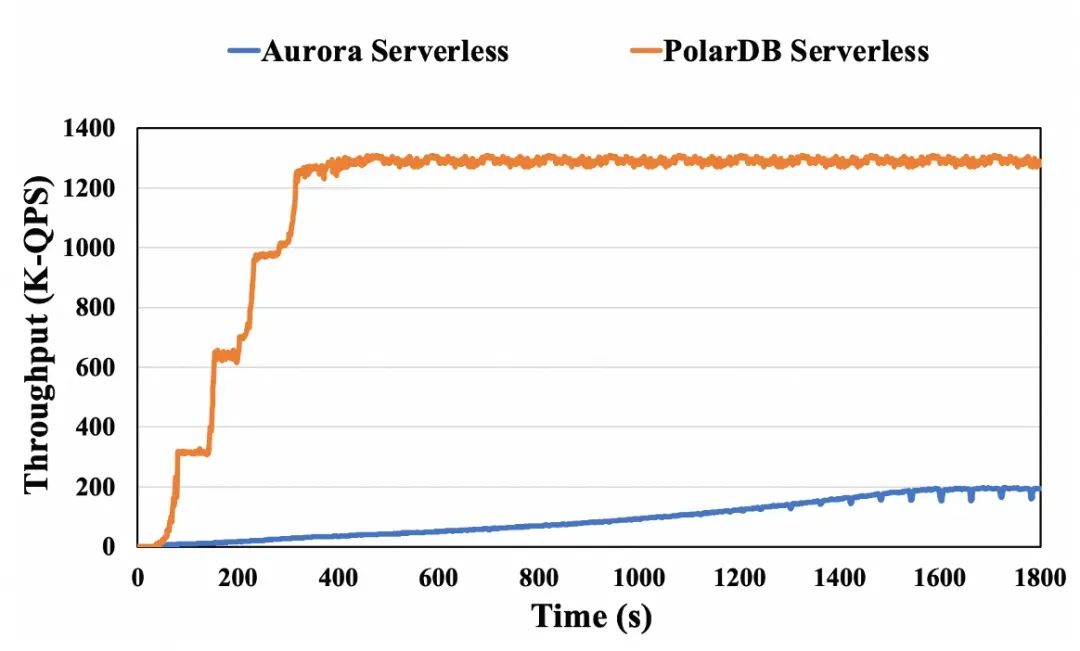
在这种设计中,当读压力加重时,必须要扩展主节点而不是扩展从节点。由于分配给一个实例的资源通常有一个上限,读压力变大时(需要强一致性的情况)可能将主节点扩展到最大规格,从而导致性能无法进一步提高,同时从节点节点的扩展能力并未得到利用。我们再次使用Aurora Serverless作为例子展示在以读为主工作负载下从节点的自动扩展能力,如下图所示。在180秒时,由于需要强一致性,在主节点上启动了大量的只读工作负载。随后,实例分配的资源(ACU)的数量开始增加,最终稳定在其最大容量128,同时,这段时间QPS也在一直增加,最后稳定。我们继续增加额外的工作负载。然而,ACU的数量不再增加,因为它已经达到了其最大限制,进而吞吐量也没有进一步改善。如果这类数据库扩展其对从节点的强一致性支持,则可以通过扩展从节点来处理更重的读工作负载,从而提升性能。
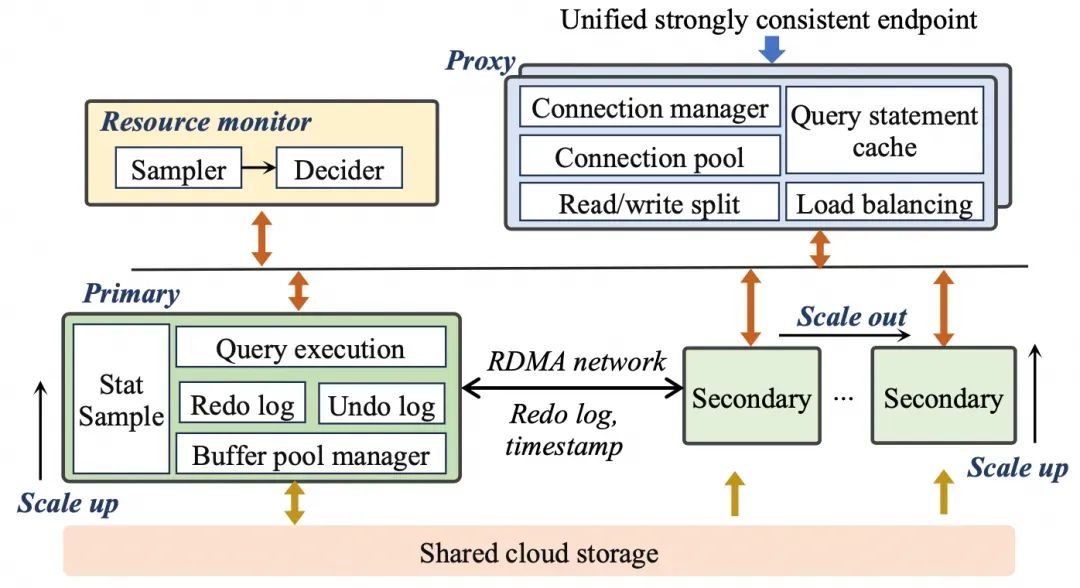
PolarDB Serverless是基于PolarDB构建的,因此与PolarDB有类似的架构,如图5所示,采用了分离的共享存储架构。同样地,PolarDB Serverless也有一个代理节点,该节点位于主节点和从节点之上。代理节点提供读写分离和负载平衡等功能,以及各种与Serverless相关的功能,包括连接管理和查询语句缓存。PolarDB Serverless以PolarDB Capacity Units(PCUs)为单位管理资源,其中一个PCU代表1个vCPU、2GB内存及相应的网络和I/O资源。PolarDB Serverless资源分配和回收的粒度为0.5个PCU。值得注意的是,PolarDB Serverless相对其他Serverless数据库有两个创新的特点:(1)PolarDB Serverless支持无感的跨机迁移,可以在0.5秒内完成实例迁移,且对应用完全透明。(2)从节点支持强一致读,可以支持从节点的横向扩展来提升读性能。
PolarDB Serverless的设计和实现
连接保持是实现无感跨机迁移的一个重要基础,其目标是在实例迁移期间保持应用的连接不中断,并无感地将用户连接从旧实例迁移到新实例,使用户无法察觉到迁移发生。PolarDB Serverless利用了代理节点来实现这个功能。代理节点负责管理连接访问。所有应用程序都直接连接到代理节点。代理节点验证应用程序连接的访问权限,并为它们建立对应的数据库实例连接。在数据库迁移期间,代理节点会建立到新实例的新连接,并在退出旧实例后切断与旧实例连接。随后,将应用程序的连接重新映射到新实例。因此,应用程序与代理节点之间的连接保持活跃,没有任何中断。
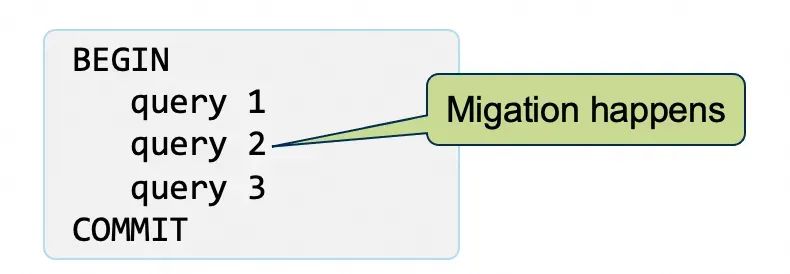
连接保持只是无感跨机迁移的一个基本要求,无感跨机迁移的一个最重要的需求是能够将活跃事务迁移到新的实例上。假设有这样一个事务,包含3个query。如果迁移发生在query2的执行过程中。那么迁移后需要在这个新实例上继续这个事务,需要恢复原事务已经完成的修改,并进行后续的query执行,在这个例子中query 1已经完成了并返回给了应用,但是query 1的修改可能还没有持久化到存储。所以在新实例上需要恢复query1的修改。迁移时query2正在执行,query2的部分修改可能已经被持久化了,所以在新实例需要回滚query2的修改,并重新执行query2。
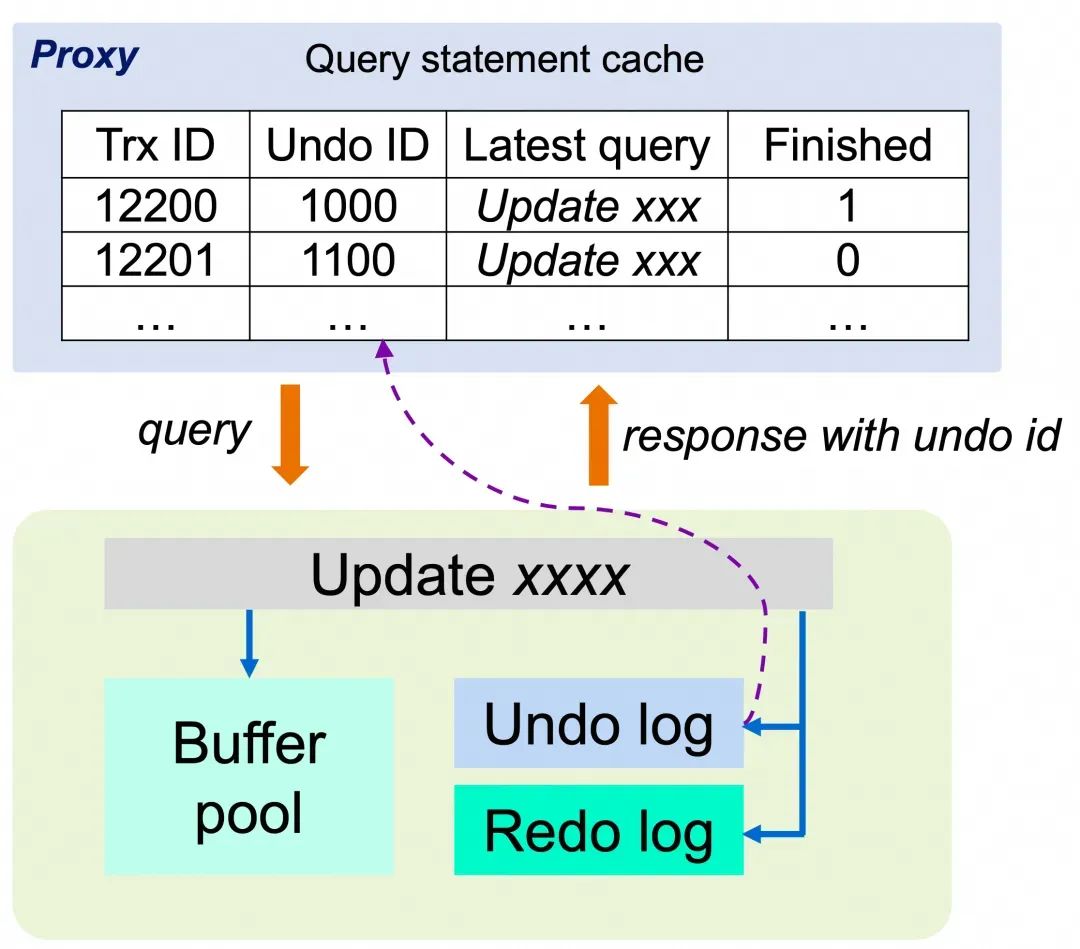
当代理节点收到一个query时,会先将query缓存,并标记为未完成的状态。随后query会被发送到数据库实例,数据库在处理query时会产生相应的undo和redo日志,在处理完query后,数据库会给代理节点返回结果,同时会将该query执行产生的最大的undo log id返回给代理节点。代理节点会缓存这个undo log id并将query执行结果返回给客户端,同时会将这个query标记为完成。这个代理节点缓存的undo log id表明了,当前事务在这个undo log id之前的修改已经响应给客户端了。在迁移到新实例时,通过回滚最新的undo log到这个undo log id就可以回滚所有没有响应给客户端的修改。
事务迁移可以避免向应用抛出事务中断的异常,并降低在新实例上回滚未提交事务的相关开销。然而,进一步降低迁移开销的重要性也是至关重要的。PolarDB Serverless使用两种策略加速迁移过程。首先是基于RDMA的数据迁移。RDMA网络已经是阿里云的基础设施,与PolarDB高度协同设计。在迁移过程中,相关的内存数据(例如redo日志、binlog和必要的元数据)通过RDMA接口传输到新实例。另一种是提前预热新实例,包括从存储中预加载必要的日志数据,并在可能的情况下提前解析它们。这可以在迁移过程中节省大量I/O开销和CPU开销。
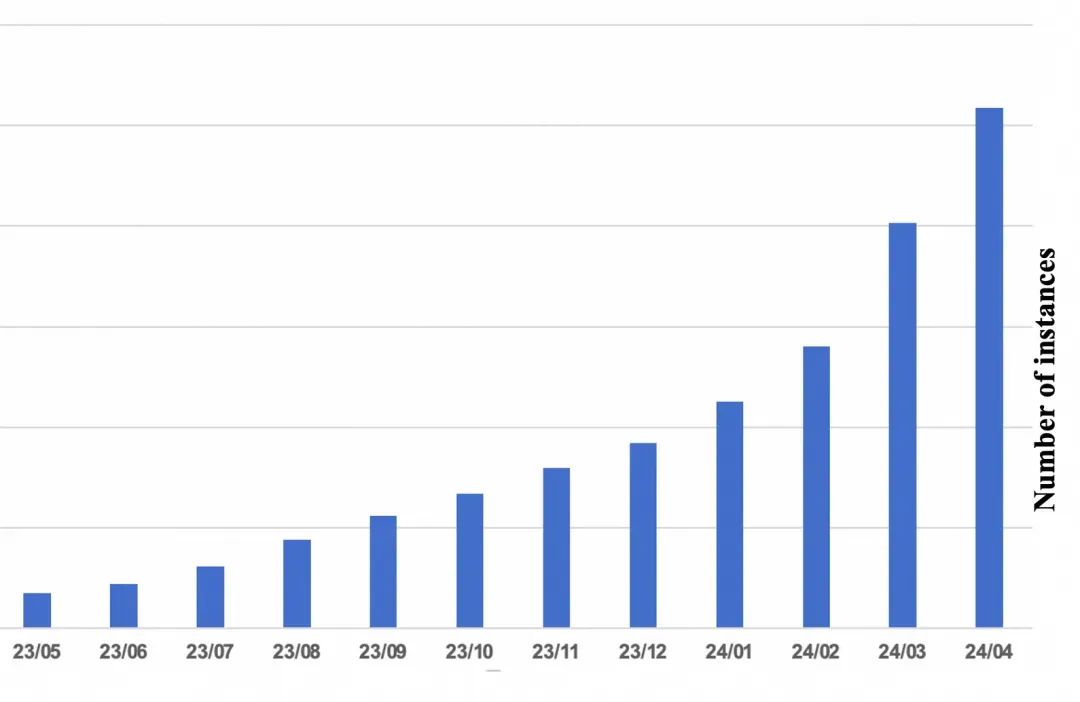
PolarDB Serverless的商业化情况
PolarDB Serverless自从2023年5月份商业化以来,用户量一直保持高速增长,目前总实例数突破1万个,按年增长率突破12倍。目前Serverless逐渐成为PolarDB售卖的主要形态。




 点击了解 云原生数据库PolarDB
点击了解 云原生数据库PolarDB
