




近期遇到需要将一个阿里云上的AnalyticDB PostgreSQL版(简称ADB)的数据,从阿里云迁移到本地,这可难道我了,云上备份无法导出,按工单给出的提示,并不能很好的去实现整库的数据同步
按照以往经验,接下来看看具体怎么处理吧~
1. 迁移难点
提交工单后,给出的指导建议:
(1) 目前adbpg还不支持在本地部署,您这边本地可以使用postgresql进行测试
(2) 通过copy导出数据请参考:https://help.aliyun.com/zh/analyticdb-for-postgresql/user-guide/use-the-copy-command-to-export-data-to-your-computer?spm=a2c4g.11186623.0.i9
(3) 通过OSS中转处理:https://help.aliyun.com/zh/analyticdb-for-postgresql/user-guide/use-oss-external-tables-to-export-data-to-oss?spm=a2c4g.11186623.0.0.7e204934dwmuRj
按工单上的建议,细品发现,只能按表处理,整库600+表,这个处理,太麻烦了,放弃。。
2. 迁移方案选定
那么问题来了:一个是本地用什么库来存储,再者是通过什么工具来处理,数据量几千万,说大不大;说小:单表导出再导入也有点难(中转是csv或者txt)
(1)目标库选择:
由于本地未postgreSQL,鉴于ADB的语法与ORACLE兼容性很高,于是决定用oracle 11G
(2)工具选择:
那就试试常用的navicat吧
3. navicat 数据传输工具
3.1 连接ADB
想起平常也用navicat做些简单的数据同步,测试后,该工具可以使用postgreSQL的驱动连接上ADB,惊喜~~

3.2 数据传输
工具 -> 数据传输 -> 选择源端 -> 选择目标端 -> 选择需要同步的表(由于是全量迁移,直接全选)
“选项” 按钮(如图):注意:需要创建表及索引和约束,转换对象为“大写”,别问我为什么,若是不设置的话,会发现对象都变成了小写,每次查询对象要增加双引号,麻烦且给后期带了很多的隐患

PS:考虑是全量迁移,为了保证数据的完整性,不勾选“遇到错误时继续”;不勾选“创建前删除目标对象”,这样遇到错误就停下来,处理完报错后再继续
3.3 迁移过程【辛酸泪】
(1)报错1: ORA-01400: 无法将 NULL 插入 (“virdb”.“T1”.“code”)
比对了目标端和源端的表结构,没有问题,但是设置不允许NULL值的字段,在源端确实出现了NULL值
处理措施:将目标端不允许NULL设置为NULL,清空表后再同步
(2)报错2:ORA-01727: 数字精度说明符超出范围 (1 到 38)
建表语句中,字段"XFJE" NUMBER(53,0) 触发精度问题
处理措施:查看源端数据,评估后,将目标端精度设置为 “XFJE” NUMBER(38,0)
(3)ORA-00904: “SUBMIT_USER_ID”: 标识符无效
这就是上面提到的对象要转为"大写”,不然过去都是小写,找不到字段和表
(4)ORA-00972: 标识符过长
ADB表名长度34个字符,而目标端只支持30字符表名
解决方案:这不好搞呀,表名不能变;后想到19C,测试后,果断将目标端换成了19C,问题解决,后面更长的表名也支持
(5)数ERROR: canceling statement due to statement timeout
据量多超时问题,查看剩下最后2张表,合计数据6量千万行,这navicat工具无解了
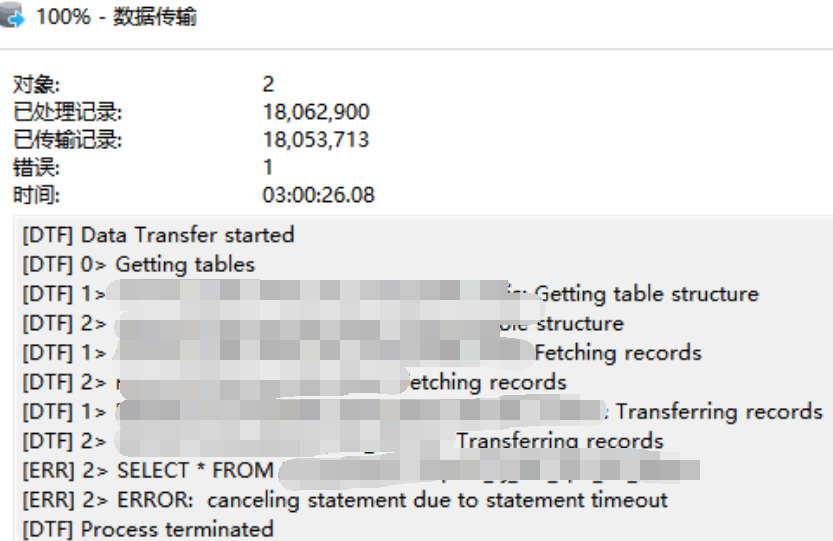
总结:navicat工具,完成了所有表结构创建,及99%张表的迁移,剩下最后2张,由于数据量大,历时3个小时,传输1800万数据后以失败告终
于是又想起另外一个常用的工具。。。,下面具体来看
4. python3 实现数据同步
python安装这就不说了,直接进入主题吧
4.1 安装py连接到postgreSQL的驱动
-- 打开终端,执行安装
pip install psycopg2
4.2 py连接ADB的方式
conn_pg = psycopg2.connect(database='virdb', user='user1', password='888888', host='gp-xxx.aliyuncs.com', port='5432')
4.3 py脚本开发并执行:实现查询源端ADB,并插入到目标端
由于数据量较大,安装业务表的特性,按时间切割查询,并插入到目标端
# coding=utf-8
# -*- coding: utf-8 -*-
import pymysql
from apscheduler.schedulers.background import BackgroundScheduler
from xgj.class_py import log
import psycopg2
import cx_Oracle
import datetime
import time
if __name__ == '__main__':
print("开始执行")
logger = log.Log(path='D:/日志/')
def select_adb_ins_t1():
连接到源端ADB
conn_pg = psycopg2.connect(database='virdb', user='user1', password='888888', host='gp-xxx.aliyuncs.com', port='5432')
cursor_pg = conn_pg.cursor()
# 连接到目标数据库
conn_b = cx_Oracle.connect("user1", "888888", "10.10.10.1:1521/virdb", encoding="UTF-8", nencoding="UTF-8")
cursor_b = conn_b.cursor()
# 查询和插入语句
sql = ["select * from t1 where ctime between :stime and :etime"]
insert_sql = "insert into t1 VALUES (:1, :2, :3, :4, :5, :6, :7, :8, :9, :10, :11, :12, :13, :14, :15, :16, :17, :18, :19, :20, :21, :22, :23)"
# 参数设置
now1 = datetime.datetime.now()
one_day = datetime.timedelta(days=1)
try:
# 按时间段查询插入(查询原表最小日期到最大日期间隔天数,按天查询和插入
for i in range(120):
stime = datetime.datetime(year=2024, month=1, day=5, hour=0, minute=0, second=0) + i * one_day
etime = datetime.datetime(year=2024, month=1, day=5, hour=23, minute=59, second=59) + i * one_day
sql_item = sql[0].replace(':stime', "'" + str(stime) + "'::timestamp").replace(':etime', "'" +str(etime) + "'::timestamp")
cursor_pg.execute(sql_item)
results = cursor_pg.fetchall()
if not results:
print("查无数据")
else:
list_result = list(results)
cursor_b.executemany(insert_sql, list_result)
inserted_rows1 = cursor_b.rowcount
conn_b.commit()
print("插入t1表:" + str(inserted_rows1) + '行')
print("表t1插入完成")
except Exception as e:
print("An error occurred:" + str(e))
# 关闭连接
conn_pg.close()
conn_b.close()
# 执行函数
select_adb_ins_t1()
5. 数据验证
思路:
(1)比对源端及目标端所有表的行数,是否一致
(2)抽查部分表,查看数据的是否会出现乱码等现象
(3)使用相关查询SQL(涉及面大的),比对查询结果是否一致
至此,本次的全量同步就完成。
