





图解
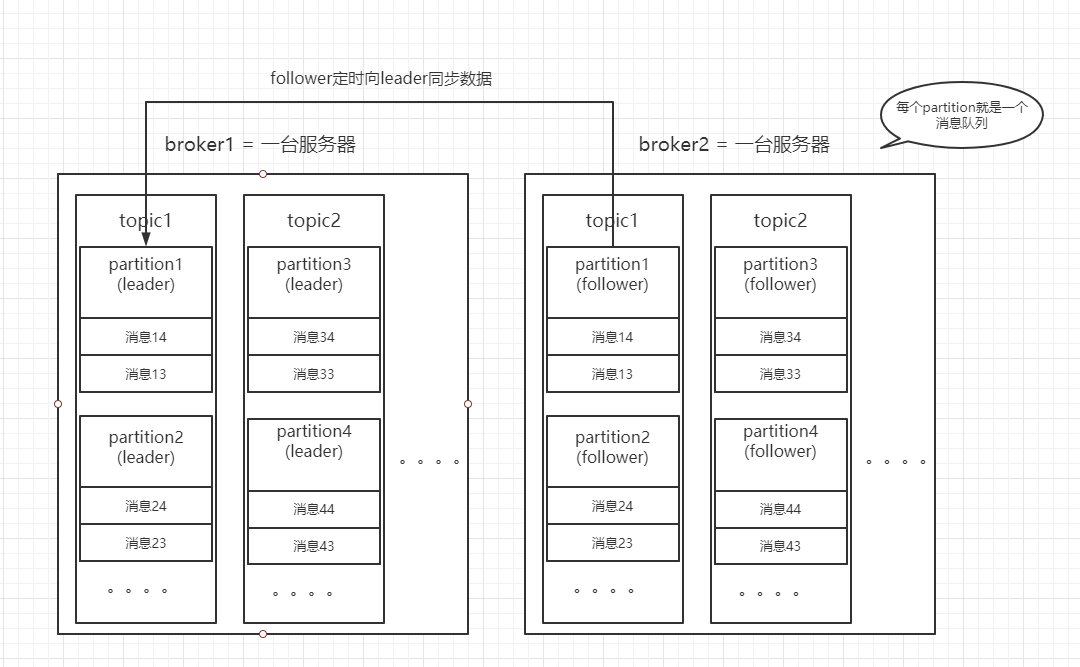
1.broker、partition的关系
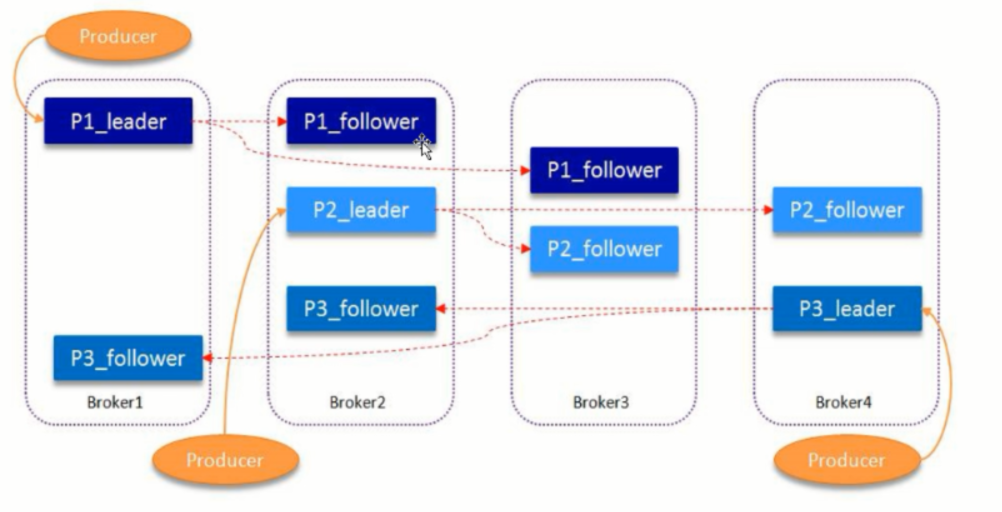
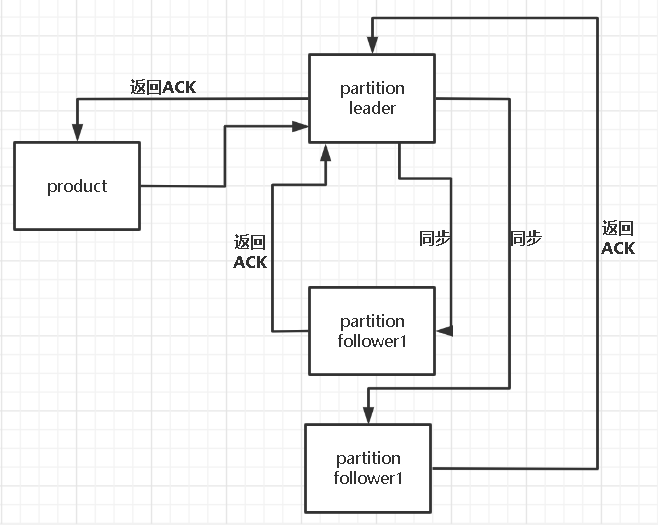
2.partition中leader和follower
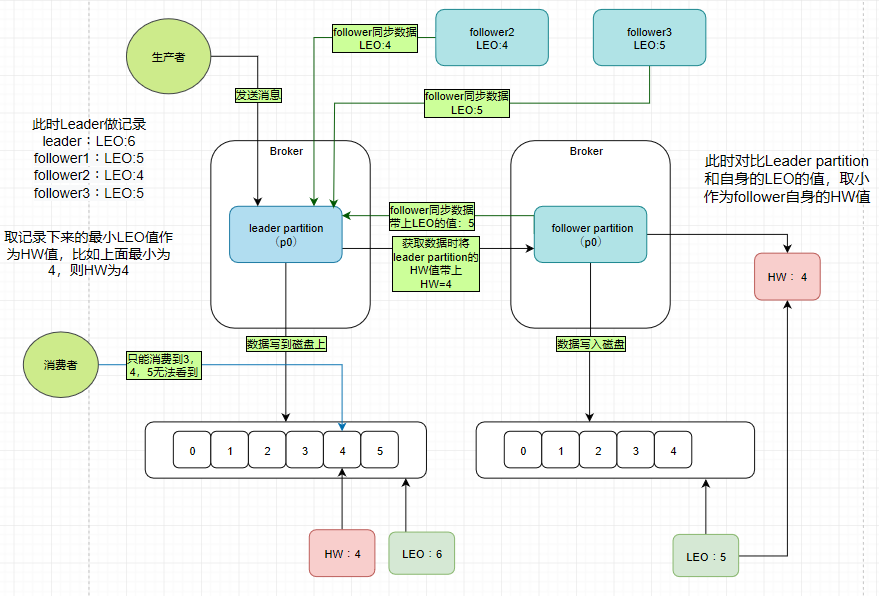
3.HW&LEO(LEO(last end offset)日志末端偏移量;HW(highwatermark),高水印值)
Kafka的HW,LEO更新原理及运行流程总结
https://juejin.im/post/6844904008189116424
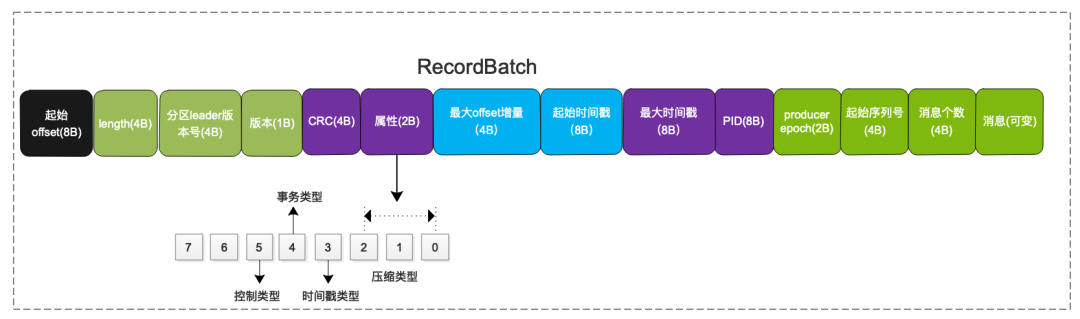
4.消息的格式
5.LogSegment文件命名的规则和日志


6.零拷贝
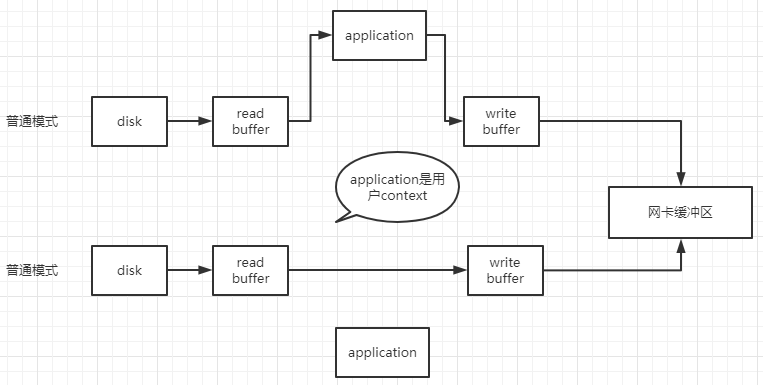
7.保证消息不丢失
关键词
Broker:
一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic,各Broker之间地位平等。
Topic:
每个message属于一个Topic,收到的message进行load balance,均匀的分布在这个topic下的不同的partition上
Partition:
分片,分为leader和follower,一个topic中包含多个Partition,物理上是一个文件夹;1个partition只能被同组的一个consumer消费;分区内的消息具有顺序性,分区间的数据无序性;
Replica:
副本,Partition含有N个Replica,其中一个replica为leader,其他为follower;follower定期去同步leader数据;
Message:
消息,是通信的基本单位;消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的;
Offset:
消息在Topic的Partiton中的位置,同一个Partition中的消息随着消息的写入,其对应的Offset也自增
LogSegment:
日志段,一个日志又被划分为多个日志段,一个日志段对应一个具体的日志文件和两个索引文件(日志文件以“.log”为后缀,两个索引文件分别以“.index”和“.timeindex”),表示消息偏移量索引文件和消息时间戳索引文件
ISR:
保存同步的副本列表。Kafka在zookeeper中动态维护了一个ISR(In-sync-Replica)即保存同步的副本列表,保存的是与Leader副本保持消息同步的所有副本对应的代理节点id。如果一个Follower副本宕机或者落后太多,则该Follower副本节点将从ISR列表中移除。
Controller
Kafka集群中的其中一个Broker会被选举为Controller,主要负责Partition管理和副本状态管理,也会执行类似于重分配Partition之类的管理任务。
如果当前的Controller失败,会从其他正常的Broker中重新选举Controller。
Producer
消息生产者
Consumer
消息消费者,每个Consumer属于一个Consumer Group;每个Consumer Group中可以包含多个Consumer;一个Partiotn只会被Consumer Group中一个Consumer消费
安装步骤
1.zookeeper安装
# 下载连接# https://zookeeper.apache.org/releases.html#downloadwget https://mirrors.bfsu.edu.cn/apache/zookeeper/zookeeper-3.6.2/apache-zookeeper-3.6.2-bin.tar.gztar -zxvf apache-zookeeper-3.6.2-bin.tar.gzmv apache-zookeeper-3.6.2-bin /usr/localcd /usr/localmv apache-zookeeper-3.6.2-bin zookeeper3.6.2cd zookeeper3.6.2/confmv zoo_sample.cfg zoo.cfg# 启动./bin/zkServer.sh start
2.kafka安装
# 下载连接# http://kafka.apache.org/downloadswget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.6.0/kafka_2.12-2.6.0.tgztar -zxvf kafka_2.12-2.6.0.tgcd kafka_2.12-2.6.0mv kafka_2.12-2.6.0 /usr/localcd /usr/local/kafka_2.12-2.6.0/confvim server.properties##zoopeeker.connect=127.0.0.1:3000,127.0.0.1:3001
3.Scala安装
# 下载链接# https://www.scala-lang.org/download/2.12.12.html# https://downloads.lightbend.com/scala/2.12.12/scala-2.12.12.tgzwget https://downloads.lightbend.com/scala/2.12.12/scala-2.12.12.tgztar -zxvf scala-2.12.12.tgzmv scala-2.12.12 /usr/localcd /usr/local# 环境变量设置vi /etc/profile# 修改export SCALA_HOME=/usr/local/scalaexport PATH=${SCALA_HOME}/bin:$PATH# 环境变量生效操作source /etc/profile
知识点介绍
1.有Leader和follower,为什么Kafka不支持读写分离?
生产者写入消息、消费者读取消息的操作都是与 leader 副本进行交互的,是主写主读的生产消费模型(1)数据一致性问题。数据从主节点转到从节点必然会有一个延时的时间,这段时间会导致主从节点之间的数据不一致。(2)延时问题。主从同步数据需要经 历网络→主节点内存→网络→从节点内存这几个阶段,整个过程会耗费一定的时间
2.怎么保证kafka数据不丢失
1.生产者request.required.acks=-1 (leader和follower都确认成功之后才返回成功)retries=Integer.MAX_VALUE (发送失败重试的次数,捕获异常)2.消费者enable.auto.commit=false,手动提交3.brockerreplication.factor >= 2 (副本数)min.insync.replicas = 2 (ISR中副本数)unclean.leader.election.enable = false (下面有介绍)
3.kafka为什么这么快?
(1)Cache Filesystem Cache PageCache缓存(2)顺序写 由于现代的操作系统提供了预读和写技术,磁盘的顺序写大多数情况下比随机写内存还要快。(3)Zero-copy 零拷⻉,少了一次内存交换。(4)Batching of Messages 批量量处理。合并小的请求,然后以流的方式进行交互,直顶网络上限。(5)Pull 拉模式 使用拉模式进行消息的获取消费,与消费端处理能力相符。
4.如果leader crash时,ISR为空怎么办
kafka在Broker端提供了一个配置参数:unclean.leader.election.enable,这个参数有两个值:true(默认):允许不同步副本成为leader,由于不同步副本的消息较为滞后,此时成为leader,可能会出现消息不一致的情况。false:不允许不同步副本成为leader,此时如果发生ISR列表为空,会一直等待旧leader恢复,降低了可用性。
5.什么情况下一个 broker 会从 isr中踢出去
leader会维护一个与其基本保持同步的Replica列表,该列表称为ISR(in-sync Replica)每个Partition都会有一个ISR,而且是由leader动态维护如果一个follower比一个leader落后太多,或者超过一定时间未发起数据复制请求则leader将其重ISR中移除
核心参数
1.producer
1.常见异常处理(1)retries:重新发送数据的次数(默认为0,表示不重试)(2)retry.backoff.ms:两次重试之间的时间间隔(默认为100ms)2.提升消息吞吐量buffer.memory:设置发送消息的缓冲区,默认值是33554432,就是32MBcompression.type: 用于压缩数据的压缩类型。默认是none表示无压缩。可以指定gzip、snappybatch.size: 批处理消息记录,以减少请求次数(默认是16384Bytes,即16kB,满了16kB就发送出去)linger.ms: 消息延迟的最大时间(默认是0,即立即发出)一般设置一个100毫秒之类的,这样的话就是说,这个消息被发送出去后进入一个batch,如果100毫秒内,这个batch满了16kB,自然就会发送出去。但是如果100毫秒内,batch没满,那么也必须把消息发送出去了,不能让消息的发送延迟时间太长,也避免给内存造成过大的一个压力。3.请求超时max.request.size:控制发送出去的消息的大小,默认是1048576字节,也就1mb,一般设成10mbrequest.timeout.ms:发送消息超时的时间限制,默认是30秒,超过会报TimeoutException4.ACK参数request.required.acks:消息的持久化机制(1)=0:不管消息是否写入成功到broker中,直接发送下一条数据到batch中,数据丢失的风险最高,但吞吐量最大(2)=1: 只要leader写入成功,就认为消息成功了.如果刚写入leader,leader就挂了,此时数据必然丢了(3)=-1/all: leader写入成功 + follower写入成功。数据安全,性能最差
2.consumer
heartbeat.interval.ms consumer心跳时间 (默认值:3000)session.timeout.ms kafka多长时间感知不到一个consumer就认为他故障了,默认是10秒max.poll.interval.ms 如果在两次poll操作之间,超过了这个时间,会被踢出消费组fetch.max.bytes 获取一条消息最大的字节数 (默认值:1048576)max.poll.records 一次poll返回消息的最大条数(默认值:500条)connections.max.idle.ms consumer跟broker的socket建立连接的超时时间,建议设置成-1 不超时(默认值:540000)auto.offset.reset:earliest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费latest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从当前位置开始消费none topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常注:我们生产里面一般设置的是latestenable.auto.commit 设置为自动提交offset (默认值:true)auto.commit.interval.ms 每隔多久更新一下偏移量 (默认值:60 * 1000)
Kafka常用topic操作命令汇总
Kafka常用topic操作命令汇总
行无际 https://www.cnblogs.com/itwild/p/12287850.html
offset相关# 最大offsetbin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic test_topic --time -1# 最小offsetbin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic test_topic --time -2# offsetbin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic test_topictopic相关# 列出当前kafka所有的topicbin/kafka-topics.sh --zookeeper localhost:2181 --list# 创建topicbin/kafka-topics.sh --create --zookeeper localhost:2181 --topic test_topic --replication-factor 1 --partitions 1bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic test_topic --replication-factor 3 --partitions 10 --config cleanup.policy=compactbin/kafka-topics.sh --create --zookeeper localhost:2181 --topic test_topic --partitions 1 --replication-factor 1 --config max.message.bytes=64000 --config flush.messages=1# 查看某topic具体情况bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic test_topic# 修改topic(分区数、特殊配置如compact属性、数据保留时间等)bin/kafka-topics.sh --zookeeper localhost:2181 --alter --partitions 3 --config cleanup.policy=compact --topic test_topic# 修改topic(也可以用这种)bin/kafka-configs.sh --alter --zookeeper localhost:2181 --entity-name test_topic --entity-type topics --add-config cleanup.policy=compactbin/kafka-configs.sh --alter --zookeeper localhost:2181 --entity-name test_topic --entity-type topics --delete-config cleanup.policyconsumer-group相关# 查看某消费组(consumer_group)具体消费情况(活跃的消费者以及lag情况等等)bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group test_group --describe# 列出当前所有的消费组bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list# 旧版bin/kafka-consumer-groups.sh --zookeeper 127.0.0.1:2181 --group test_group --describeconsumer相关# 消费数据(从latest消费)bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_topic# 消费数据(从头开始消费)bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_topic --from-beginning# 消费数据(最多消费多少条就自动退出消费)bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_topic --max-messages 1# 消费数据(同时把key打印出来)bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_topic --property print.key=true# 旧版bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test_topicproducer相关# 生产数据bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test_topic# 生产数据(写入带有key的message)bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test_topic --property "parse.key=true" --property "key.separator=:"
错误处理
1. Uninitialized object exists on backward branch 50
# jdk版本不匹配,需要更新版本,现在一般用openjdk#命令如下:yum install java-1.8.0-openjdk# 执行完后,验证:java -version# openjdk version "1.8.0_262"# OpenJDK Runtime Environment (build 1.8.0_262-b10)# OpenJDK 64-Bit Server VM (build 25.262-b10, mixed mode)# 上述操作还不能解决问题的话,最好重启哈linux
