





普通集群配置
查看日志目录
[root@rabbitmq2 rabbitmq]# tail -f /var/log/rabbitmq/rabbit@rabbitmq2.log
1.配置注意事项
集群中个节点目录/var/lib/rabbitmq/.erlang.cookie中的内容有保持一致集群中删除节点时,既要执行子节点操作,又要在主节点上执行删除节点操作,不然主节点日志会一直报:down: connection_closed
2.主节点上的命令(我这里是是rabbitmq1)
# 查看集群状态[root@rabbitmq1 ~]# rabbitmqctl cluster_status其中Cluster name 表示集群名称我这里是:rabbit@rabbitmq1
3.子节点加入集群步骤
# 启动[root@rabbitmq2 rabbitmq]# service rabbitmq-server start# 停止应用 -- 必须执行的[root@rabbitmq2 rabbitmq]# rabbitmqctl stop_app# 加入集群[root@rabbitmq2 rabbitmq]# rabbitmqctl join_cluster rabbit@rabbitmq1# 启动应用[root@rabbitmq2 rabbitmq]# rabbitmqctl start_app
4.子节点退出集群步骤(子节点上执行)
# 停止应用 -- 必须执行的[root@rabbitmq2 rabbitmq]# rabbitmqctl stop_app# 刷新[root@rabbitmq2 rabbitmq]# rabbitmqctl reset
5.主节点上删除集群节点
[root@rabbitmq2 rabbitmq]# rabbitmqctl -n rabbit@rabbitmq1 forget_cluster_node rabbit@rabbitmq2
6.上述命令是增加硬盘节点,还有一种内存节点,至少有一个磁盘节点,否则无法写入新的队列元数据信息,命令如下
ram --- 内存节点;disc --- 磁盘节点# 只要在命令join_cluster后面增加ram就是内存节点[root@rabbitmq2 rabbitmq]# rabbitmqctl join_cluster --ram rabbit@rabbitmq1# 修改其中中的对象类型的步骤[root@rabbitmq2 rabbitmq]# rabbitmqctl stop_app[root@rabbitmq2 rabbitmq]# rabbitmqctl change_cluster_node_type disc[root@rabbitmq2 rabbitmq]# rabbitmqctl start_app
7.查看集群状态:rabbitmqctl cluster_status
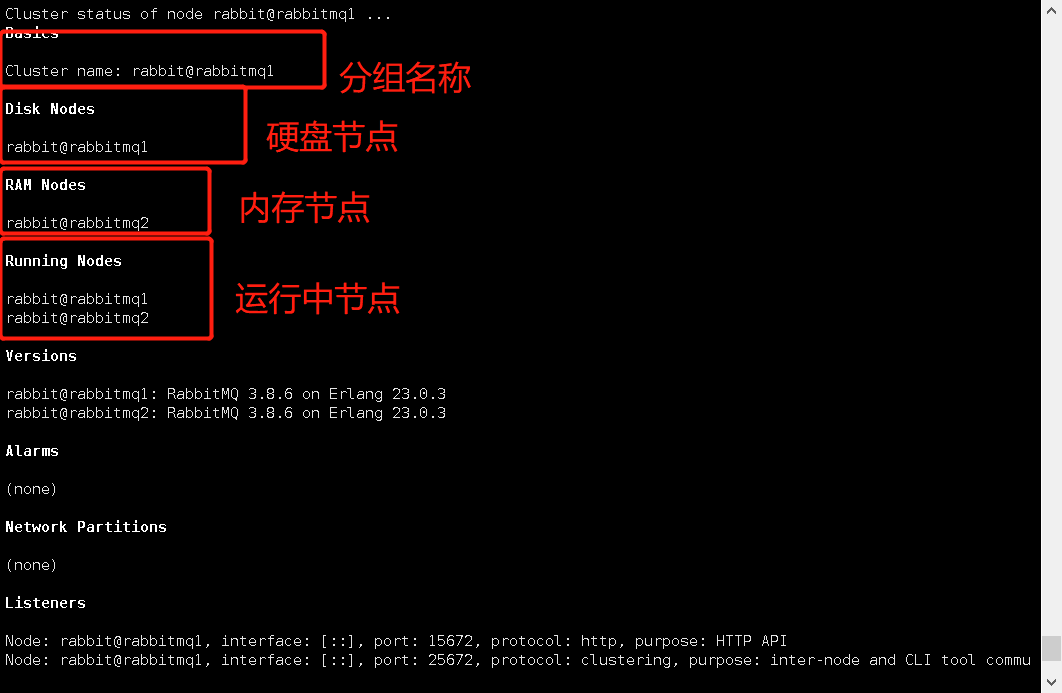
镜像集群
该模式在上面集群模式下配置的,以达到高可用的目,需要在rabbitmq管理后台中执行操作,操作如下:
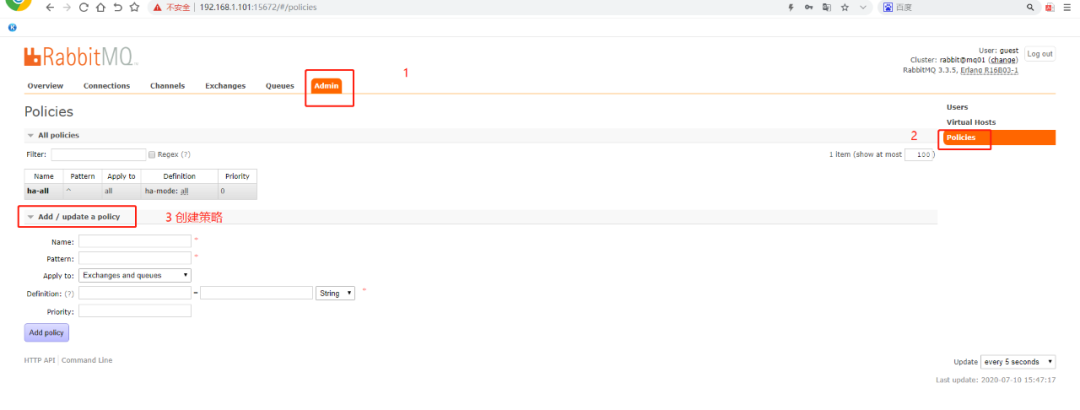
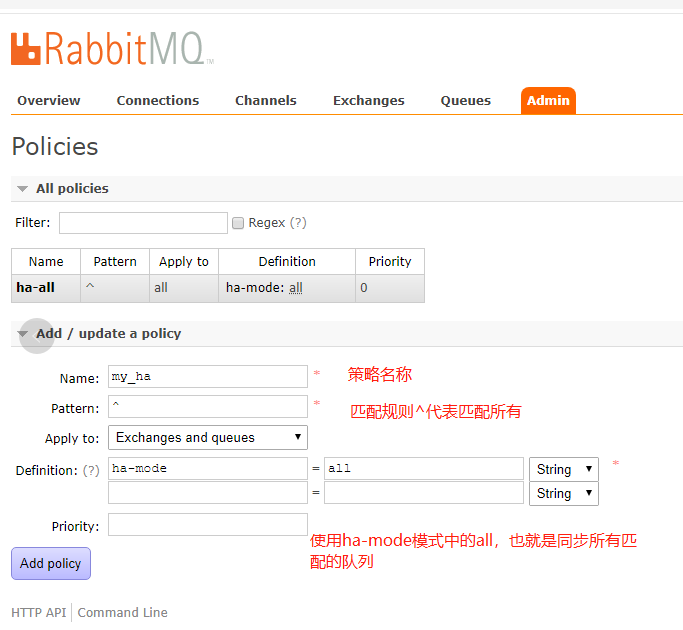
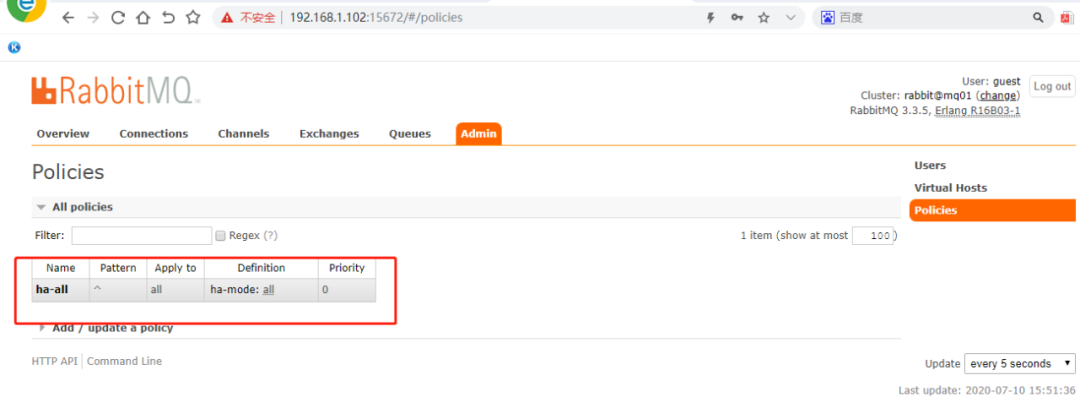
如果有节点宕机后启动后出现如下现象,需要在宕机节点上执行同步命令
# 其中 ab 是需要同步的队列名称[root@rabbitmq2 rabbitmq]# rabbitmqctl sync_queue ab
补充项目地址
https://gitee.com/hzy100java/my-rabbitmq.git
新增加了批量执行方法
@Bean("batchQueueRabbitTemplate")public BatchingRabbitTemplate batchQueueRabbitTemplate(ConnectionFactory connectionFactory,@Qualifier("batchQueueTaskScheduler") TaskScheduler taskScheduler){//!!!重点:所谓批量, 就是spring 将多条message重新组成一条message, 发送到mq, 从mq接受到这条message后,在重新解析成多条message//一次批量的数量int batchSize=10;// 缓存大小限制,单位字节,// simpleBatchingStrategy的策略,是判断message数量是否超过batchSize限制或者message的大小是否超过缓存限制,// 缓存限制,主要用于限制"组装后的一条消息的大小"// 如果主要通过数量来做批量("打包"成一条消息), 缓存设置大点// 详细逻辑请看simpleBatchingStrategy#addToBatch()int bufferLimit=1024000; //1000 K// 指定时间内收集消息,对消息进行组装long timeout=5000;//注意,该策略只支持一个exchange/routingKey//A simple batching strategy that supports only one exchange/routingKeyBatchingStrategy batchingStrategy=new SimpleBatchingStrategy(batchSize,bufferLimit,timeout);return new BatchingRabbitTemplate(connectionFactory,batchingStrategy,taskScheduler);}
批量处理监听需要注意,借鉴
@RabbitListener(queues = {"batch_queue"})@RabbitHandlerpublic void onMessageBatch(List<Message> messages, Channel channel) throws IOException {log.info("batch.queue.consumer 收到{}条message", messages.size());for (int i = 0; i < messages.size(); i++) {log.info("第" + i + "条数据是: {}", new String(messages.get(i).getBody()));}// 报错时多注意Long deliveryTag = messages.get(messages.size() - 1).getMessageProperties().getDeliveryTag();// RabbitMQ保证在每个信道中,每条消息的deliveryTag从1开始递增// multiple=true: 消息id<=deliveryTag的消息,都会被确认// multiple=false: 消息id=deliveryTag的消息,都会被确认channel.basicAck(deliveryTag, true);}
文章转载自Java技术学习笔记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
