




近期陆续做了一些针对达梦数据库的相关测试,同时也看了微信群一些网友的反馈,总的来讲发现一些内容颠覆了我的认知。首先要说评价的话,对于达梦本来讲,作为国货之光还是很不错的,毕竟做了几十年,尤其是在针对Oracle兼容性方面,目前来看还是真是遥遥领先。
说到兼容性,我想很多人的认识都有一个误区。我想要表达是,目前各家应该都差距很小了,都可以覆盖大部分应用场景了。为什么这样说?其实很简单,因为oracle功能众多,假设有1000项,达梦兼容了其中800项,其他数据库兼容了500项目。但是可能客户系统使用到的oracle 功能可能就200项而已,从这个角度来讲,其实大家差距并不大了,因为大家的兼容性可能都在95%左右。当然,这不是我们今天要讲的主题。
对于达梦数据库,经过近期的测试研究发现,我认为除了之前提到的不支持多块写这个令人诟病的缺点之外,我还发现了不少。今天就讲讲其中2个最为关键且致命的缺点。
高可用架构的不足
达梦数据库的高可用主要分为2种,1种是主备,一种是类似Oracle RAC的共享集群dmdcs。我们先来看达梦的主备。
+++ 备库模拟网卡故障
[root@dmserver2 ~]# date;ifconfig ens192 down;sleep 5;ifconfig ens192 up;date
2024年 05月 31日 星期五 13:53:27 CST
2024年 05月 31日 星期五 13:53:32 CST
[root@dmserver2 ~]#
假设当备库网卡故障或者主备之间网络不通情况之下,这里就模拟5s断开,然后恢复。我们来看看达梦主库的表现:
[dmdba@dmserver1 bin]$ dmmonitor dmmonitor.ini
[monitor] 2024-05-31 13:33:19: DMMONITOR[4.0] V8
[monitor] 2024-05-31 13:33:19: DMMONITOR[4.0] IS READY.
[monitor] 2024-05-31 13:33:19: Received message from(ZCLOUDDM1)
WTIME WSTATUS INST_OK INAME ISTATUS IMODE RSTAT N_OPEN FLSN CLSN
2024-05-31 13:33:19 OPEN OK ZCLOUDDM1 OPEN PRIMARY VALID 13 74149900 74149900
[monitor] 2024-05-31 13:33:19: Received message from(ZCLOUDDM2)
WTIME WSTATUS INST_OK INAME ISTATUS IMODE RSTAT N_OPEN FLSN CLSN
2024-05-31 13:33:19 OPEN OK ZCLOUDDM2 OPEN STANDBY VALID 13 74149898 74149898
[monitor] 2024-05-31 13:53:34: Dmwatcher process ZCLOUDDM1 status switching [OPEN-->STARTUP]
WTIME WSTATUS INST_OK INAME ISTATUS IMODE RSTAT N_OPEN FLSN CLSN
2024-05-31 13:53:34 STARTUP OK ZCLOUDDM1 SUSPEND PRIMARY VALID 13 74150749 74150754
[monitor] 2024-05-31 13:53:34: Dmwatcher process ZCLOUDDM1 status switching [STARTUP-->MON CONFIRM]
WTIME WSTATUS INST_OK INAME ISTATUS IMODE RSTAT N_OPEN FLSN CLSN
2024-05-31 13:53:34 MON CONFIRM OK ZCLOUDDM1 SUSPEND PRIMARY VALID 13 74150749 74150754
什么?主库的状态居然变成了suspend!这是什么鬼?此时如果我们登录到数据库分别查看主、备的情况会发现确实如此:
++主库
[dmdba@dmserver1 ~]$ disql sysdba/Root_1234
Server[LOCALHOST:5236]:mode is primary, state is suspend
login used time : 2.352(ms)
disql V8
SQL> select mode$,status$ from v$instance;
LINEID MODE$ STATUS$
---------- ------- -------
1 PRIMARY SUSPEND
used time: 0.993(ms). Execute id is 30230500.
SQL>
++备库
[dmdba@dmserver2 ~]$ disql sysdba/Root_1234
Server[LOCALHOST:5236]:mode is standby, state is open
login used time : 2.636(ms)
disql V8
SQL> select status$,mode$ from v$instance;
LINEID STATUS$ MODE$
---------- ------- -------
1 OPEN STANDBY
used time: 1.704(ms). Execute id is 25248500.
SQL>
我们可以看到主备关系仍然是正常的,但是实际上主库此时状态需要人为干预,否则会一直处于suspend状态。在该状态之下,主库是无法进行事务commit提交的。也就是说,所有的业务提交将被阻塞(当然,查询没有任何问题)。那么问题来了,为什么达梦会有如此奇葩的设计呢?我们来看看文档。
后面又发现实际上官方不建议把监视器跟数据库server部署在同一台机器,最好是再找一台第三方机器,相当于来个第三方仲裁。那么这就能彻底解决这个问题吗?事实是:不能!
更为关键的是这个备注:

实际上达梦这个suspend和open状态是可以相互转换的,但是需要人工干预。如果monitor部署在第三方机器上,那么是可以自动转换状态的,这里我暂时人工干预一下:
[monitor] 2024-05-31 14:21:53: Instance ZCLOUDDM1[PRIMARY, AFTER REDO, ISTAT_SAME:TRUE] recover to OK
WTIME WSTATUS INST_OK INAME ISTATUS IMODE RSTAT N_OPEN FLSN CLSN
2024-05-31 14:21:53 STARTUP OK ZCLOUDDM1 AFTER REDO PRIMARY VALID 13 74150749 74150749
[monitor] 2024-05-31 14:21:53: Dmwatcher process ZCLOUDDM1 status switching [STARTUP-->UNIFY EP]
WTIME WSTATUS INST_OK INAME ISTATUS IMODE RSTAT N_OPEN FLSN CLSN
2024-05-31 14:21:53 UNIFY EP OK ZCLOUDDM1 MOUNT PRIMARY VALID 13 74150749 74150749
[monitor] 2024-05-31 14:21:53: Dmwatcher process ZCLOUDDM1 status switching [UNIFY EP-->STARTUP]
WTIME WSTATUS INST_OK INAME ISTATUS IMODE RSTAT N_OPEN FLSN CLSN
2024-05-31 14:21:53 STARTUP OK ZCLOUDDM1 OPEN PRIMARY VALID 14 74150749 74152434
[monitor] 2024-05-31 14:21:54: Dmwatcher process ZCLOUDDM1 status switching [STARTUP-->OPEN]
WTIME WSTATUS INST_OK INAME ISTATUS IMODE RSTAT N_OPEN FLSN CLSN
2024-05-31 14:21:54 OPEN OK ZCLOUDDM1 OPEN PRIMARY VALID 14 74152435 74152435
我们会发现该节点重启会经历after redo、mount、open 几个阶段。同时我发现这里mal线路check有相关参数来控制,主要是如下2个参数:
[root@dmserver1 zclouddm]# cat dmmal.ini |grep INTER
MAL_CHECK_INTERVAL = 1
MAL_CONN_FAIL_INTERVAL = 2
[root@dmserver1 zclouddm]#
其中mal_check_internal 取值范围是0~1800s(官方文档建议设置为60s),而mal_conn_fail_interval取值范围是2~1800s,默认值是10s,不建议设置过小。这里我为了验证上述参数特征,所以改成了1s和2s。
发现确实mal链路失败2s,主库就会被设置为suspend状态。
--备库
[root@dmserver2 zclouddm]# date;ifconfig ens192 down;sleep 2;ifconfig ens192 up;date
2024年 06月 01日 星期六 18:23:35 CST
2024年 06月 01日 星期六 18:23:37 CST
[root@dmserver2 zclouddm]#
--主库
[monitor] 2024-06-01 18:24:51: Received message from(ZCLOUDDM1)
WTIME WSTATUS INST_OK INAME ISTATUS IMODE RSTAT N_OPEN FLSN CLSN
2024-06-01 18:24:51 MON CONFIRM OK ZCLOUDDM1 SUSPEND PRIMARY VALID 16 74222650 74222651
通过pstack 观察了一下,发现实际上就是判断超时,然后redolog thread进行sleep状态。
14:34:24:135Thread 21 (LWP 2102407):
14:34:24:135#0 0x00007f3e3a937d49 in pthread_cond_timedwait () from target:/lib64/libpthread.so.0
14:34:24:135#1 0x000000000040ffc1 in os_event2_wait_timeout ()
14:34:24:135#2 0x000000000139e272 in rarch_mal_recv ()
14:34:24:135#3 0x000000000139f001 in rarch_realtime ()
14:34:24:135#4 0x00000000004a6c1a in rlog4_write_to_file ()
14:34:24:135#5 0x00000000004a733f in rlog4_flush_thread ()
14:34:24:135#6 0x00007f3e3a931f2b in ?? () from target:/lib64/libpthread.so.0
14:34:24:135#7 0x00007f3e3a52e6bf in clone () from target:/lib64/libc.so.6
14:34:27:850Thread 21 (LWP 2102407):
14:34:27:850#0 0x00007f3e3a937d49 in pthread_cond_timedwait () from target:/lib64/libpthread.so.0
14:34:27:850#1 0x000000000040ffc1 in os_event2_wait_timeout ()
14:34:27:851#2 0x00000000004a6ee0 in rlog4_flush_thread ()
14:34:27:851#3 0x00007f3e3a931f2b in ?? () from target:/lib64/libpthread.so.0
14:34:27:851#4 0x00007f3e3a52e6bf in clone () from target:/lib64/libc.so.6
14:34:29:538Thread 21 (LWP 2102407):
14:34:29:538#0 0x00007f3e3a93b700 in nanosleep () from target:/lib64/libpthread.so.0
14:34:29:538#1 0x0000000000421107 in os_thread_sleep_low ()
14:34:29:538#2 0x00000000004a7385 in rlog4_flush_thread ()
14:34:29:538#3 0x00007f3e3a931f2b in ?? () from target:/lib64/libpthread.so.0
14:34:29:538#4 0x00007f3e3a52e6bf in clone () from target:/lib64/libc.so.6
14:34:30:923Thread 21 (LWP 2102407):
14:34:30:923#0 0x00007f3e3a93b700 in nanosleep () from target:/lib64/libpthread.so.0
14:34:30:923#1 0x0000000000421107 in os_thread_sleep_low ()
14:34:30:923#2 0x00000000004a7385 in rlog4_flush_thread ()
14:34:30:923#3 0x00007f3e3a931f2b in ?? () from target:/lib64/libpthread.so.0
14:34:30:923#4 0x00007f3e3a52e6bf in clone () from target:/lib64/libc.so.6
希望以后能改进这一点,否则我认为对生产系统来讲,是个致命影响。就算是监视器部署到第三方机器,那么也会有open -> suspend -> open的过程,也有那么几秒钟。难道要让客户的核心系统停掉几秒钟???
当然上述2个参数,设置稍微偏大一点,应该是可以避免一般的网络故障,比如闪断。但是如果遇到网卡故障,那么默认10s之后,主库就会变成suspend状态;即使监视器部署到第三方机器,也一样,无法避免该问题。因此这个问题,我认为是内核redo线程的问题,期望后续能够改进该问题。
稳定性不足
如果说客户核心系统选择一个数据库产品,那么我认为数据库的稳定性无疑是一个非常重要的因素。因此各个厂家其实都在加强这方面的能力。我也经常对比一些数据库产品,看看大家的稳定性究竟如何,以帮助客户更好地进行产品选择。在测试达梦的过程中,我发现其波动性是比较大的,如下:
我特意测了10分钟的sysbench,选择了5分钟之后的部分数据,发现波峰波谷差异很大,超过60%。这个性能波动,我在想,跑关键业务系统应该很酸爽吧,一卡一卡的酸爽。
那么为什么会这样呢?我结合日志看了下,每次性能下降的时候都是刷脏比较多的时间点。我想这或许跟达梦刷脏进程不支持多块写有关,同时跟检查点也有一定关系。看上去目前达梦还不支持增量检查点,检查发现检查点相关的参数如下:
SQL> select PARA_NAME,PARA_VALUE,DEFAULT_VALUE,DESCRIPTION from v$dm_ini where PARA_NAME like '%CKPT%';
PARA_NAME PARA_VALUE DEFAULT_VALUE DESCRIPTION
---------------- ---------- ------------- ------------------------------------------------------------------
CKPT_RLOG_SIZE 128 128 Checkpoint Rlog Size, 0: Ignore; else: Generate With Redo Log Size
CKPT_DIRTY_PAGES 2048 0 Checkpoint Dirty Pages, 0: Ignore; else: Generate With Dirty Pages
CKPT_INTERVAL 3 180 Checkpoint Interval In Seconds
CKPT_FLUSH_RATE 5.000000 5.000000 Checkpoint Flush Rate(0.0-100.0)
CKPT_FLUSH_PAGES 1000 1000 Minimum number of flushed pages for checkpoints
CKPT_WAIT_PAGES 8192 1024 Maximum number of pages flushed for checkpoints
6 rows got
used time: 8.394(ms). Execute id is 907.
从检查点参数来看,我感觉还是非常的简单;更重要的是无法去自动调节刷脏的频率,以至于出现较大的性能波动。
当然上面都是个人测试观点,如有错误,请指出!
写到这里,肯定会有网友会说,喷人家的数据库,那么你们自己的MogDB性能如何?是不是一样也很挫?那我也来一张压测数据(实际上是DM的硬件环境更好一些,因为是SSD,而MogDB环境是我3年前买的2手x86服务器+机械盘,相关内存大小参数配置也差不多)。
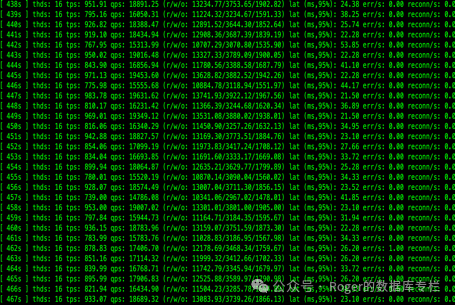
看看图片就知道稳不稳了吧,波峰波谷性能抖动在20%左右,大部分情况是低于10%的。好了,就写这么多了!简单的技术分享,并不是为了喷和蹭热点!
最后还是希望国产数据库都能越来越好!
MogDB是云和恩墨基于openGauss的完善增强企业发行版,
围绕高性能、高可用、全密态、多数据库兼容等特点,
已广泛应用于银行、保险、证券、交易所、制造等关键行业。
1、MogDB技术群请加vx(Roger_database)
2、MogDB更多技术细节与行业应用 www.mogdb.io
3、数据库兼容适配 marketing@enmotech.com

