




整体部署方案
同城两机房部署,推荐采用3+2(主机房部署3个实例,从机房部署2个实例,下同),或者2+1的部署方式。不同机房之间,采用专线网络的方式部署。如下图是3+2部署的简单示例。
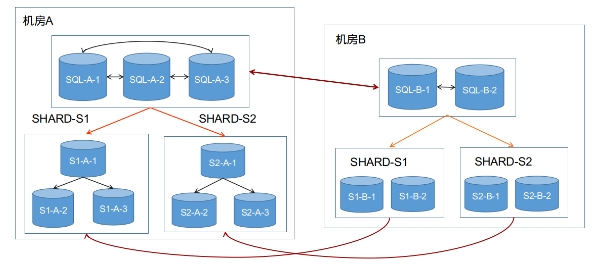
部署A机房
首先,A机房中所有的节点在节点启动之前,需要在配置文件中额外添加如下配置项。
my.cnf [mysqld] gdb_zone_name=A loose-group_replication_zone_id=0 loose-group_replication_zone_id_sync_mode=ON- 正常初始化并启动A机房的所有sqlnode和datanode节点
- 依次通过greatdb_init_cluster,greatdb_add_sqlnode,greatdb_add_datanoe,greatdb_init_shard 等接口,初始化集群并将A机房的节点加入集群
- 至此,集群中A机房的节点部署完毕,且A机房的机房权重并设置为最高值 9 。
添加B机房
首先,B机房中所有的节点在启动之前,需要在配置文件中额外添加如下配置项。并保证机房名和机房id和已经存在的A机房不一致。
my.cnf [mysqld] gdb_zone_name=B loose-group_replication_zone_id=1 loose-group_replication_zone_id_sync_mode=ON添加机房,并指定机房权重值。其中,机房名称和机房id需要和节点配置的参数值保持一致。
/* 机房名:B */ /* 机房id:1 */ /* 机房城市:beijing */ /* 机房权重: 6 */ CALL mysql.greatdb_add_zone('B', 1, 'beijing', 6);- 调用greatdb_add_sqlnode接口,添加B机房中的sqlnode节点
- 调用greatdb_add_datanode接口,添加B机房中的datanode节点
- 至此,B机房中所有的节点加入了集群中。
需要注意的是,添加B机房时,最好保证B机房的权重小于A机房,由于A机房权重被初始为最大值9,即B机房的权重需要保持在0-8之间。如此配置,即可视为将A机房设置为主机房,并且当A机房中的节点发生故障时,重新选主时,会优先选择A机房的节点。
单机房部署升级为双机房
- 如果原集群不支持创建机房(5.0.7及之前版本),首先需要将数据库版本升级到最新版本
- 在集群支持创建机房功能基础上,可以进行在线不停机添加机房
首先,原始集群未进行任何机房配置情况下,会创建一个默认的机房,并可以根据实际情况,调用greatdb_set_zone_var修改出机房id外所有的属性。
- 默认机房名:DEFAULT
- 默认机房id:0
- 默认机房城市:DEFAULT
- 默认机房选举权重:9
由于group_replication_zone_id_sync_mode默认开启,满足双机房部署要求,因此,无需重启sqlnode和每个shard的组复制,即可添加新的B机房。
需要注意的是,如果原始集群中,关闭了group_replication_zone_id_sync_mode。则无法进行在线升级。此时,需要择机停止线上服务,停止sqlnode和每个shard的组复制,并在每个节点中,开启zone_id_sync_mode,然后,重启sqlnode和shard的组复制,提供服务。之后,再添加新的B机房。
节点故障及处理方案
单个节点故障
无论采用3+2还是2+1的方式,任何单个节点故障,由于paxos多数派协议,都不会造成数据丢失,即RPO等于0。如果是一个shard的从节点发生故障,不影响集群使用;如果是一个shard的主节点发生故障,paxos会通过多数派选举协议,自动选择新的主节点,做到RTO在一个较低的水平。
备机房故障
无论是3+2还是2+1的方式,主机房中都包含多数节点,因此,备机房整体故障的情况下,依旧可以保证数据不丢失,并且不影响集群正常使用。
主机房故障
首先需要注意的是,无论是3+2还是2+1方式,主机房故障,无法保证不丢失任何数据。同城两机房部署中,会要求两个机房配置不同的group_replication_zone_id,并开启group_replication_zone_id_sync_mode,进行如此配置时,组复制在满足基本多数派协议的基础上,还需要保证所有节点均同步了数据。但是,当机房整体故障的情况下,为了满足高可用性,故障的机房不再要求同步数据。当发生连续故障时,备机房可能被踢出集群,然后主机房故障,此时,备机房将丢失数据。也因此,并不推荐进行双机房部署。
因此,如果主机房故障时,是需要DBA对数据是否丢失进行验证。此时,可以通过查看原主机房节点的错误日志进行验证,如果主机房各节点在故障前,未出现其它故障,没有备机房节点变成UNREACHABLE,或者将备机房节点踢出组复制的相关日志,此时,备机房将不会丢失数据;否则,不保证数据不丢失。如果,主机房节点机器完全故障,无法查看错误日志,则无法验证数据是否丢失。
一些特殊故障场景,可能引起连续的故障,比如:
- 地震灾害,首先破坏了两个机房的网络专线,然后引起主机房故障
- 火灾,首先破坏了网络,然后导致主机房故障
- 其它
还需要注意的是,无论是否可能丢失数据,主机房故障,集群均不可使用,此时需要进行人工恢复。如果确定不存在数据丢失,或者业务容忍部分数据的丢失,此时,可以通过 greatdb_force_restart_cluster 和 greatdb_force_restart_shard等相关用户接口强制启动集群,提供服务。
故障机房恢复处理
存在如下几种情形:
- 备机房故障,节点可以恢复。此时,将各个节点恢复即可。
- 备机房故障,且无法恢复。此时,需要通过
greatdb_drop_datanode和greatdb_drop_sqlnode移除相关数据节点和计算节点,然后通过greatdb_drop_zone删除机房。之后,按照添加备机房的步骤,添加新的备机房和相应节点。 - 主机房故障,节点恢复,恢复后仍作为主机房。首先,恢复主机房各个节点,节点加入到组复制。此时,由于每个shard内部,主节点都在备机房中,可以通过
greatdb_change_shard_primary_node接口手动调整主节点。 - 主机房故障,节点恢复,恢复后作为备机房。由于需要保持主机房包含多数节点,此时,需要在备机房中进行扩容操作,添加一个新的sqlnode,以及每个shard中添加一个新的datanode。原主机房节点中移除一个sqlnode,和datanode节点,然后,启动主机房剩余节点。此时,由于主机房切换,需要通过
greatdb_set_zone_var接口,调整两个机房的选主权重值。 - 主机房故障,无法恢复。此时,需要删除故障机房的节点的机房信息,然后添加新的机房。如果将原备机房作为新的主机房,则需要在原备机房中扩容,添加sqlnode和datanode节点,并调用
greatdb_set_zone_var接口调大选主权重值。如果将新的机房设置为主机房,则添加新机房后,调用greatdb_change_shard_primary_node将shard的节点手动切换到新机房。
其它双机房部署方案
采用2+2的部署。此时任何一个机房故障,均不会丢失数据数据,可以做到RPO等于0。但是,任何机房故障,都将导致集群不可用,需要手动恢复集群。如果网络环境较差,频繁闪断,会极大的影响集群的使用。
