




双中心双活方案
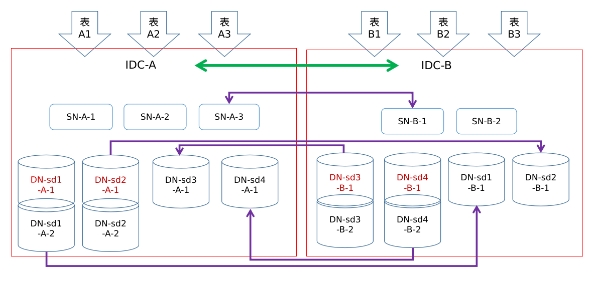
在双中心双活中,业务层面存在两个互不干扰的系统业务,两个机房中分别承担其中一个业务逻。总体部署架构如下图所示,图中使用的是2+1的部署方式,即每个shard中,主机房部署两个datanode节点,备机房部署一个datanode节点,也可以采用3+2的部署方式。
节点系统配置
首先,A机房中所有的节点在节点启动之前,需要在配置文件中额外添加如下配置项。
my.cnf [mysqld] gdb_zone_name=A loose-group_replication_zone_id=0 loose-group_replication_zone_id_sync_mode=ON同理,B机房中所有的节点需要进行如下配置
my.cnf [mysqld] gdb_zone_name=B loose-group_replication_zone_id=1 loose-group_replication_zone_id_sync_mode=ON配置所有数据节点的group_replication_member_weight参数。以前述架构图为例,业务A的操作在shard-1和shard-2中,而业务B的操作在shard-3和shard-4中。因此需要确保,A机房中,shard-1和shard-2中datanode节点的参数值,大于B机房中的值;同理,A机房中,shard-3和shard-4中datanode节点的参数值,小于B机房中的值。通过这种配置,可以保证主节点故障时,优先选主同机房的节点作为新的主节点。
A机房中datanode可以进行如下配置:
my.cnf ## DN-sd1-A-1, DN-sd1-A-2, DN-sd2-A-1, DN-sd2-A-2 [mysqld] loose-group_replication_member_weight=90 ## DN-sd3-A-1, DN-sd4-A-1 [mysqld] loose-group_replication_member_weight=10B机房中datanode可以进行如下配置:
my.cnf ## DN-sd3-B-1, DN-sd3-B-2, DN-sd4-B-1, DN-sd4-B-2 [mysqld] loose-group_replication_member_weight=90 ## DN-sd1-B-1, DN-sd2-B-1 [mysqld] loose-group_replication_member_weight=10初始化并启动所有的sqlnode和datanode节点
依次通过greatdb_init_cluster,greatdb_add_sqlnode,greatdb_add_datanoe,greatdb_init_shard 等接口,初始化集群并将A机房的节点加入集群。至此,集群中A机房的节点部署完毕,且A机房的机房权重并设置为最高值 9 。
添加B机房,并指定机房权重值也为9,保持两个机房权重一致。其中,机房名称和机房id需要和节点配置的参数值保持一致。
/* 机房名:B */ /* 机房id:1 */ /* 机房城市:beijing */ /* 机房权重: 9 */ CALL mysql.greatdb_add_zone('B', 1, 'beijing', 9);greatdb_add_sqlnode接口,添加B机房中的sqlnode节点;之后调用greatdb_add_datanode接口,添加B机房中的datanode节点。至此,B机房中所有的节点加入了集群中。
查询information_schema.greatdb_sqlnodes结果,确保所有的sqlnode状态正常
查询information_schema.greatdb_datanodes结果,确保所有的datanode状态正常
由于是先在A机房中初始化集群并初始化shard-3和shard-4,调用greatdb_change_shard_primary_node接口,将shard3的主节点切换到DN-sd3-B-1节点,将shard4的主节点切换到DN-sd4-B-1节点,并确保调整后shard3和shard4的状态正常。
完成集群部署
建表操作
由于A机房承担业务A的操作,B机房承担业务B的操作,因此建表时,需要将业务A的表建在shard-1和shard-2中,也业务B的表建在shard-3和shard-4中。以A机房的表为例,可以使用如下方式建表:
# 通过comment指定normal表的shard
create table A_t1 (c1 int primary key) comment='shard=shard1';
# 通过comment指定normal表只能在shard1和shard2的其中一个节点
create table A_t2 (c1 int primary key) comment='shard_group=shard1,shard2';
# 通过comment建立global表,并指定global表在shard1和shard2中建表
create table A_t3 (c1 int primary key) comment='shard_group=shard1,shard2;disttype=global'
# 通过comment指定分区表只在shard1和shard2上建表
create table A_t4 (c1 int primary key) comment='shard_group=shard1,shard2' partition by hash(c1) partitions 4;
# 使用变量批量建表,所有的表只会在shard1和shard2上建表
set session greatdb_table_shard_group='shard1,shard2';
create table A_t5(c1 int primary key);
create table A_t6(c1 int primary key) comment='disttype=global';
create table A_t7 (c1 int primary key) partition by hash(c1) partitions 4;
同理,可以使用相同的方式将业务B的所有表,建立在B机房关联的shard3和shard4中。
需要注意的是,自动表迁移的相关接口,greatdb_auto_migrate_after_upscale和greatdb_auto_migrate_before_downscale尚不支持shard_group的建表方式,使用自动迁移接口进行扩缩容操作,会导致所有的表按原始的方式重新部署。因此,双中心双活方案中暂不推荐使用自动表迁移的命令。如果有扩缩容的需求,可以使用单表迁移的接口greatdb_migrate_table进行相关操作。
故障和业务切换
在无故障场景中,如果需要将业务B的操作切换到A机房中,可以使用在线切主的接口greatdb_change_shard_primary_node,将shard-3和shard-4的主节点切换到A机房中,之后,就可以将业务语句发送到A机房的sqlnode节点中。同理,将业务A切换到机房B,也是调用在线切主的接口,将shard-1和shard-2的主节点切换到B机房中。
如果出现故障,有如下场景:
- sqlnode单点故障,无论是A机房还是B机房,由于都部署了多个sqlnode节点,因此并不会有太大影响
- datanode单点故障,假设是shard-1出现了节点故障,有如下几种可能
- 处于B机房的DN-sd1-B-1节点故障,对业务影响不大
- 处于A机房的DN-sd1-A-2节点故障,该节点也是从节点,对业务影响不大
- 处于A机房的DN-sd1-A-1节点故障,该节点是主节点,需要进行重新选主;由于集群中zone_A和zone_B的权重都是9,且DN-sd1-A-2节点的group_replication_member_weight=90大于DN-sd1-B-1=10,因此会选择DN-sd1-A-2为新主,新主依旧在A机房中。选主成功且新主提供服务后,对业务影响不大
- 机房故障。假设A机房整体故障,有如下几种可能:
- B机房中sqlnode节点数小于或者等于A机房中sqlnode数量,此时sqlnode故障,确保数据安全情况下,需要调用greatdb_force_restart_cluster接口恢复sqlnode
- B机房中sqlnode节点数多余等于A机房中sqlnode数量,此时B机房中sqlnode不会故障,无需调用greatdb_restart_cluster接口
- shard-1中,只剩一个DN-sd1-B-1节点,为少数派,确保数据安全情况下,调用greatdb_force_restart_shard恢复shard-1;并使用同样的方式恢复shard-2,然后将业务A的语句发送到B机房中
- 如果存在网络分区的场景,且无法通过任何方式连接到A机房,此时调用greatdb_force_restart_cluster和greatdb_force_restart_shard可能存在数据丢失的风险。
