





在将数据库迁移到Amazon Aurora MySQL实例或启动新的实例后,您是否问过自己以下的一个或多个问题?
▪ “下一个步骤是什么?如何让数据库以更佳状态运行?”
▪ “是否应该修改任何现有参数?”
▪ “我应该修改哪些参数?”
如果是这样,希望这篇博文可以提供一些指导,说明该做什么(以及不该做什么)。
本文将讨论、澄清并提供有关兼容MySQL的Amazon Aurora配置参数的建议。在AWS云中运行,调整或重新配置新创建或迁移的实例时,这些数据库配置参数及其值都非常重要。本文还将讨论从Amazon Relational Database Service (Amazon RDS) for MySQL实例转移到Aurora实例的参数。同时,本文将介绍哪些是默认值,哪些对于实例的稳定性和提高性能至关重要。
在进行变更之前最重要的考虑因素之一是了解变革背后的需求和动机。尽管大多数参数设置的默认值都很好,但应用程序工作负载更改可能会导致需要调整这些参数。在进行任何更改之前,请问自己以下问题:
▪ 我是否遇到稳定性问题,例如重启或故障转移?
▪ 我可以让我的应用程序更快地运行查询吗?
Amazon Aurora MySQL参数组有两种类型:数据库参数组和数据库集群参数组。某些参数会影响整个数据库集群的配置,如二进制日志格式,时区和字符集默认值。另外一些参数则将其范围限制为单个数据库实例。
这篇博文将它们分类到不同的情景中:哪些参数会影响Aurora集群的行为,稳定性和功能,以及哪些参数会在修改时影响性能。
请记住,两种参数类型都是已经预设好了默认值,可以开箱即用。同时有些参数允许修改。
如果想更深入的了解修改和使用参数组的最新基础知识,请参阅Aurora用户指南中的以下主题:
▪ 使用数据库参数组和数据库群集参数组
https://docs.amazonaws.cn/AmazonRDS/latest/AuroraUserGuide/USER_WorkingWithParamGroups.html
▪ Amazon Aurora MySQL 参考
https://docs.amazonaws.cn/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Reference.html
参数更改可能会产生意外结果,包括性能下降和系统不稳定。在更改任何数据库配置参数之前,请遵循以下最佳实践:
▪ 通过克隆或还原生产实例的快照创建测试环境,并在测试环境中进行更改。这样,您的设置就像您的生产环境一样尽可能接近。
▪ 为您的测试实例生成模拟生产环境工作负载的工作负载。
▪ 检查关键性能指标的系统性能,如CPU利用率,数据库连接数,内存利用率,缓存命中率和查询吞吐量以及延迟。在更改之前执行此操作以获取基线数字,并在观察结果之后执行此操作。
▪ 一次只更改一个参数以避免歧义。
▪ 如果更改对测试系统没有产生可测量的影响,请考虑将参数恢复为默认值。
▪ 记录哪个参数具有您期望的积极影响以及哪些关键绩效指标显示出改进。
某些数据库实例参数包含变量或公式,其中变量值由常量确定。示例包括实例的大小和内存占用,实例的网络端口及其分配的存储。建议保持这些不变,因为只要执行实例向上或向下操作,它们就会自动调整。
例如,Aurora数据库参数innodb_buffer_pool_size默认最大为:{DBInstanceClassMemory * 3/4},并且会根据系统参数调整。其中DBInstanceClassMemory是一个变量,设置为实例的内存大小减去系统以及Aurora占用的内存,并以GiB为单位。
示例:对于具有30.5 GiB内存的db.r4.xlarge实例,此值为20,090,716,160字节或18.71 GiB。
假设您决定将此参数设置为固定值,比如设置为18,000,000,000字节,稍后您对db.r4.large执行缩小操作,后者具有一半的内存(15.2 GiB)。在这种情况下,您可能会在修改数据库引擎后遇到内存不足的情况,并且实例无法正常启动。
要快速浏览系统变量自动计算的参数,可以在参数组定义中搜索这些参数。为此,请搜索大括号字符“{”。
如果要查询实例使用的实际值,有两种方法可以在命令行上执行此操作。通过使用SHOW GLOBAL VARIABLES或SELECT语句:
当某些参数配置错误时,它可能表现为记录在MySQL错误日志中的内存不足情况。在这种情况下,实例进入滚动重新启动状态并生成类似于以下内容的事件日志,并提供相关需要调整的参数值建议:
2018-12-29 19:05:16 UTC [-]MySQL has been crashing due to incompatible parameters. Please check your memory parameters, in particular the max_connections, innodb_buffer_pool_size, key_buffer_size, query_cache_size, tmp_table_size, innodb_additional_mem_pool_size and innodb_log_buffer_size. Modify the memory parameter and reboot the instance.
本博文将Aurora MySQL参数分为两大类:
▪ 控制数据库行为和功能但不影响资源利用率和实例稳定性的参数
▪ 通过管理实例中如何分配资源(如缓存和基于内部内存的缓冲区)可能影响性能的参数
本文还将分析其中的一些参数和它们的默认值,以及它们在修改时如何影响实例的行为或性能。下表描述了在参数组中找到的参数名称,Aurora和MySQL默认值,以及通过修改此参数而影响的功能的摘要。
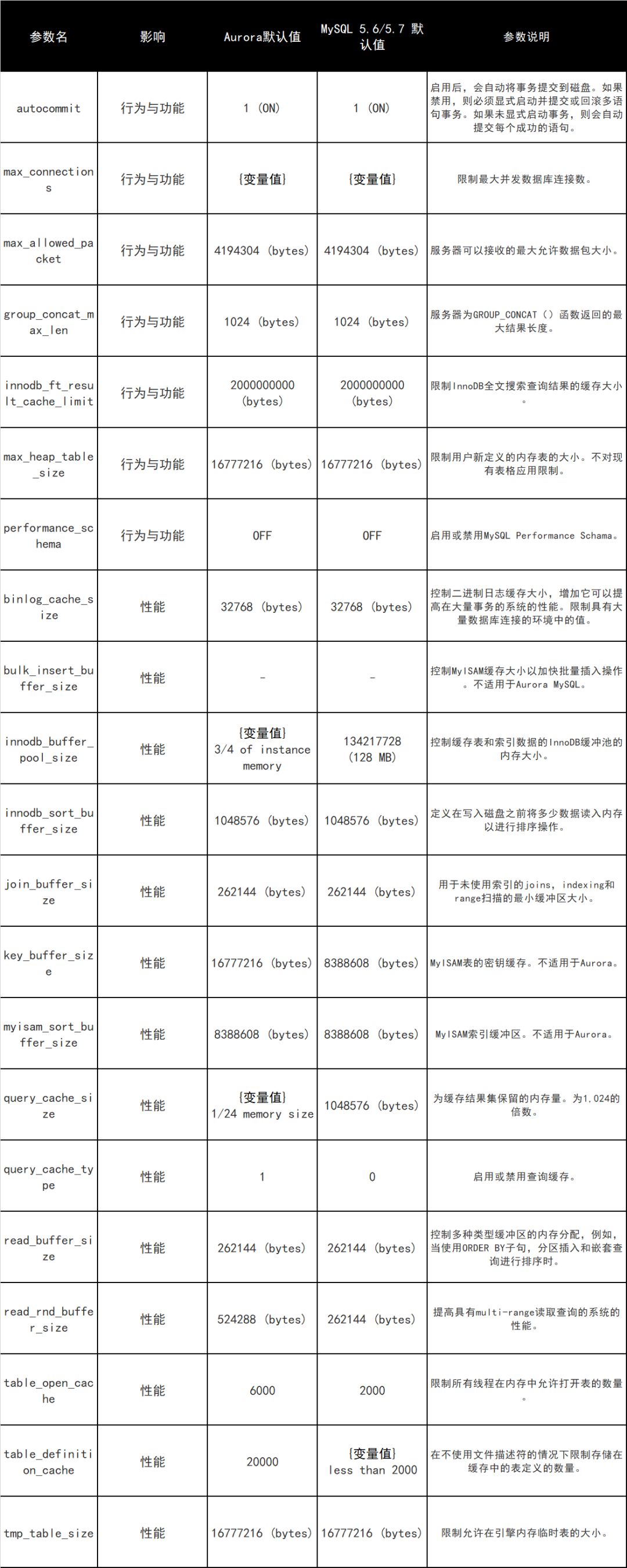
以下是关于每个关键参数如何影响数据库的简要说明,以及有关如何调整它们的一些用例:
▪ autocommit
推荐设置:使用默认值(1或ON)确保每个SQL语句在运行时自动提交,除非它是用户打开的事务的一部分。
影响:设置为OFF值可能会鼓励不正确的数据库使用模式,例如保持超过要求的打开时间,未关闭或完全提交的事务。这可能会影响数据库的性能和稳定性。
▪ max_connections
推荐设置:使用默认值(变量值)。使用自定义值时,仅配置应用程序主动用于执行工作的连接数。
影响:即使连接并未生效,过高的连接数限制也会导致更高的内存使用量。它还可能导致高数据库连接阻塞,从而影响数据库的性能和稳定性。
使用以下公式,根据实例的内存分配和大小自动填充此变量参数,因此请首先使用默认值:
GREATEST({log(DBInstanceClassMemory/805306368,2)*45{log(DBInstanceClassMemory/8187281408,2)*1000})
例如,对于具有15.25 GiB内存的Aurora MySQL db.r4.large实例,它设置为1,000,由于15.25GiB的DBInstanceClassMemory最大值不会超过15.25GiB,此处使用15.25GiB进行计算:
DBInstanceClassMemory = 16374562816 bytes
max_connections= GREATEST({log(16374562816/805306368,2)*45},{log(16374562816/8187281408,2)*1000})
max_connections = GREATEST(195.56,1000) = 1000
如果在错误日志中遇到连接错误并且发现非常多的“Too many connections”,则可以将此参数设置为固定值而不是变量设置。
在您出于应用程序需要更多连接数时考虑将max_connections设置为固定值的时候,请考虑在应用程序和数据库之间使用连接池或代理。如果无法可靠地预测或控制连接,也可以执行此操作。
手动配置此参数的值超过建议的连接数时,数据库连接的Amazon CloudWatch指标会显示一条红线,其中超出了阈值。这是CloudWatch使用的公式:
Threshold value for max_connections = {DBInstanceClassMemory/12582880}
例如,对于内存大小为15.25 GiB(15.25 x 1024 x 1024 x 1024 = 16374562816字节)的db.r4.large实例,警告阈值大约为1,300个连接(由于DBInstanceClassMemory是系统内存减去系统以及aurora占用的空间,所以实际不会超过1300个)。如果实例上有足够的资源,您仍然可以使用尽可能大数量的已配置连接。
▪ max_allowed_packet
推荐设置:默认值(4,194,304字节)。仅在数据库工作负载需要时才使用自定义值。在处理返回大型元素(如长字符串或BLOB)的查询时,请调整此参数。
影响:此处设置较大的值不会影响消息缓冲区的初始大小。相反,它允许它们在您的查询需要时增长到定义的大小。在该参数设置比较大的时候,大量符合条件的并发查询可能会增加内存不足情况的风险。
将此参数设置得太小时,会显示以下示例错误:
ERROR 1153 (08S01) at line 3a: Got packet bigger than 'max_allowed_packet' bytes
▪ group_concat_max_len
推荐设置:默认值(1,024字节)。仅在工作负载需要时才使用自定义值。仅当您想要更改GROUP_CONCAT()语句的返回并允许数据库引擎返回更长的列值时,才需要调整此参数。此值应与max_allowed_packet并行使用,因为这将确定响应的最大大小。
影响:将此参数设置得过高的一些症状是高内存使用和内存不足情况。将其设置得太低会导致查询失败。
▪ innodb_ft_result_cache_limit
推荐设置:默认值(2,000,000,000字节)。根据您的工作量使用自定义值。
影响:由于该值已接近1.9 GiB,将其增加到超出其默认值可能会导致内存不足。
▪ max_heap_table_size
推荐设置:默认值(16,777,216字节)。限制用户定义的在内存中创建的表的最大大小。更改此值仅对新创建的表有效,并且不会影响现有表。
影响:将此参数设置得太高,如果内存表增长,则会导致内存利用率高或内存不足。
▪ performance_schema
推荐设置:由于内存占用高,当使用t2实例时,禁用该选项。
影响:在Aurora MySQL 5.6中,性能模式内存是启发式预分配的。此预分配基于其他配置参数,例如max_connections,table_open_cache和table_definition_cache。在Aurora MySQL 5.7中,性能模式内存按需分配。性能模式通常消耗大约1到3 GB的内存,具体取决于实例类,工作负载和数据库配置。如果数据库实例内存不足,则启用性能架构可能会导致内存不足。
▪ binlog_cache_size
推荐设置:默认值(32,768字节)。此参数控制二进制日志高速缓存可以使用的内存量。通过增加它,您可以通过使用缓冲区来提高使用大事务的系统的性能,以避免过多的磁盘写入。此缓存基于每个连接分配。
影响:在具有大量数据库连接的环境中限制此值,以避免导致内存不足的情况。
▪ bulk_insert_buffer_size
推荐设置:保持原样,因为它不适用于Aurora MySQL。
▪ innodb_buffer_pool_size
推荐设置:默认(变量值),因为它在Aurora中预先配置为实例内存大小的75%。您可以在SHOW ENGINE INNODB STATUS的输出中看到缓冲池的使用。
影响:较大的缓冲池通过在重复访问相同的表数据时减少磁盘I / O来提高整体性能。由于InnoDB引擎的开销,实际分配的内存量可能略高于实际配置的值。
▪ innodb_sort_buffer_size
推荐设置:默认值(1,048,576字节)
影响:高于默认值的设置会增加在大量并发查询的系统中的总体内存压力。
▪ join_buffer_size
推荐设置:默认值(262,144字节)。此值预先分配用于各种类型的操作(例如joins),单个查询可以分配此缓冲区的多个实例。如果要提高join的性能,建议您为这些表添加索引。
影响:更改此参数可能会在具有大量并发查询的环境中导致严重的内存压力。即使添加索引,增加此值也不会提供更快的JOIN查询性能。
▪ key_buffer_size
建议设置:保留默认值(16,777,216字节),因为它与Aurora无关并且仅影响MyISAM表性能。
影响:对Aurora的表现没有影响。
▪ myisam_sort_buffer_size
推荐设置:保留默认值(8,388,608字节)。它不适用于Aurora,因为它对InnoDB没有影响。
影响:对Aurora的表现没有影响。
▪ query_cache_size
推荐设置:默认值(变量值)。该参数在Aurora中进行了预处理,其值远大于MySQL的默认值。Aurora的查询缓存不会受到可伸缩性问题的影响(正如MySQL中的查询缓存一样)。对于高吞吐量,高要求的工作负载,修改它是一种可接受的做法。
影响:通过此缓存访问查询时,查询性能会受到影响。您可以使用例如show status like 'qcache%'的命令输出中看到查询缓存的使用。
▪ query_cache_type
推荐设置:On。Aurora默认启用查询缓存,并且建议将其启用以提高性能并降低开销。但是,如果您知道您的工作负载不会从中受益,则可以禁用查询缓存。一个例子是写入繁重的工作负载,仅限于没有读取查询。
影响:如果你的工作负载会重用查询(如重复的SQL语句),则禁用Aurora中的查询缓存可能会影响数据库性能。您可以使用例如show status like 'qcache%'的命令输出中看到查询缓存的使用。
▪ read_buffer_size
推荐设置:默认值(262,144字节)。
影响:较大的值会导致较高的总体内存压力并引发内存不足问题。除非您能够证明较高的值在不影响稳定性的情况下提高性能,否则请勿增加设置。
▪ read_rnd_buffer_size
推荐设置:默认值(524,288字节)。由于底层存储群集的性能特征,无需增加Aurora的设置。
影响:较大的值可能会导致内存不足问题。
▪ table_open_cache
建议设置:保持原样,除非您的工作负载需要同时访问大量表。表缓存是主要的内存使用者,Aurora中的默认值明显高于MySQL默认值。此参数根据实例大小自动调整。
影响:具有大量表(数十万)的数据库需要更大的设置,因为并非所有表都适合内存。将此值设置得太高可能会导致内存不足。如果启用了Performance Schema,此设置还间接有助于Performance Schema内存使用。
▪ table_definition_cache
推荐设置:默认值。此设置在Aurora中的预设比在MySQL中大得多,并且它会根据实例大小和类自动调整。如果您的工作负载需要它并且您的数据库需要同时打开大量表,则增加此值可能会加快打开表操作。此参数与table_open_cache一起使用。
影响:如果启用了Performance Schema,则此设置还间接有助于Performance Schema内存使用。注意高于默认值的设置,因为它们可能会引发内存不足问题。
▪ tmp_table_size
推荐设置:默认值(16,777,216字节)。与max_heap_table_size一起,此参数限制用于查询处理的内存表的大小。超过临时表大小限制时,表将交换到磁盘。
影响:非常大的值(数百兆或更多)因引起内存问题和内存不足错误而臭名昭着。此参数不影响使用MEMORY引擎创建的表。
在部署新的Aurora MySQL实例时,许多参数已经过优化,在执行任何参数更改之前,它们都是一个很好的基线。每个参数的值的确切组合在很大程度上取决于各个系统,应用程序工作负载和所需的吞吐量特性。此外,在具有高变化率,增长率,数据提取率和动态工作负载的数据库系统上,这些参数还需要持续监控和评估。建议您每隔几个月(可能每隔几周)进行一次监控和评估,以使数据库适应您的应用程序和业务需求。
要执行成功的参数调整以转化为可测量的性能提升,在实施更改后进行实验为更佳,建立基线并比较结果。建议您在将更改提交到实时生产系统之前执行此操作。
原文地址:https://amazonaws-china.com/cn/blogs/database/best-practices-for-amazon-aurora-mysql-database-configuration/
Amazon Aurora MySQL 兼容版在由西云数据运营的 AWS 中国(宁夏)区域增加了对 R5 实例(新一代 Amazon Elastic Compute Cloud (Amazon EC2) 内存优化型实例)的支持。
R5 实例基于 Amazon EC2 Nitro 系统,该系统是专用硬件和轻量级管理程序的组合,它们几乎将主机硬件的所有计算和内存资源都提供给您的数据库实例。借助 1:8 的 vCPU 内存比,R5 实例非常适合运行内存密集型数据库工作负载,包括事务处理、数据仓库和分析。根据您的工作负载,与 R4 实例相比,使用 R5 实例可以实现高达 70% 的性能提升。
在 Amazon RDS 管理控制台中,您可以轻松地创建新的 R5 实例,或者修改现有的 Aurora 数据库实例以扩展到 R5。请参阅 Amazon Aurora 用户指南了解更多详情,以及查看支持的 Aurora 版本。有关定价和区域可用性,请参阅 Amazon Aurora 定价。
Amazon Aurora 既具有高端商用数据库的性能和可用性,又具有开源数据库的简单性和成本效益。与典型的 MySQL 数据库相比, 它可实现高达五倍的性能提升,并且具有更高的可扩展性、持久性和安全性。如需了解更多信息,请访问 Amazon Aurora 产品页面。如果需要考虑将现有数据库迁移到Amazon Aurora,可以参考各种场景下从MySQL数据库迁移到Amazon Aurora。
▪ Amazon RDS 管理控制台:
https://console.amazonaws.cn/rds
▪ Amazon Aurora 用户指南:
https://docs.amazonaws.cn/AmazonRDS/latest/AuroraUserGuide/index.html
▪ Amazon Aurora 定价:
https://www.amazonaws.cn/rds/aurora/pricing/
▪ Amazon Aurora 产品页面:
https://www.amazonaws.cn/rds/aurora/
▪ 各种场景下从MySQL数据库迁移到Amazon Aurora:
https://amazonaws-china.com/cn/blogs/china/every-scene-mysql-database-move-to-amazon-aurora/

肖福生
西云数据售前工程师
西云数据售前工程师,负责西云数据华南区域的云计算方案咨询和设计,同时致力于AWS在国内的应用和推广。在加入西云数据之前,在云计算行业担任解决方案架构师,负责互联网行业的云计算方案咨询以及架构设计,在企业软件架构,数据库,中间件软件等方面有丰富的经验。
- END -

↑
长按识别二维码,关注我们
关于西云数据(NWCD)
宁夏西云数据科技有限公司(简称”西云数据”)是 AWS 中国(宁夏)区域云服务的运营方和服务提供方。AWS 为西云数据的战略技术合作伙伴并向西云数据提供技术服务和技术支持。西云数据成立于 2015 年,是一家持有互联网数据中心服务和互联网资源协作服务牌照的云服务提供商。2017 年 12 月 12 日, 西云数据正式推出 AWS 中国(宁夏)区域云服务,现已开通 3 个可用区。西云数据市场销售总部设立于北京,在全国多地设有分支机构以服务全国各地的企业客户。
西云数据致力于将世界先进的 AWS 云计算技术带给中国客户,为客户提供优质、安全、稳定、可靠的云服务,全力支持中国企业和机构的创新发展。
关于 AWS
13 年以来,Amazon Web Services(AWS)一直是世界上服务丰富、应用广泛的云服务平台。通过位于美国、澳大利亚、巴林、巴西、加拿大、中国、法国、德国、印度、爱尔兰、日本、韩国、新加坡、瑞典和英国的 22 个地理区域、69 个可用区(AZ),AWS 向客户提供超过 165 项功能全面的服务,涵盖计算、存储、数据库、联网、分析、机器人、机器学习与人工智能、物联网、移动、安全、混合云、虚拟现实与增强现实、媒体,以及应用服务、部署与管理等方面。全球数百万客户,包括发展迅速的初创公司、大型企业和领先的政府机构信赖 AWS,通过 AWS 的服务强化其基础设施,提高敏捷性,降低成本。欲了解 AWS 的更多信息,请访问:http://aws.amazon.com。

