





适用版本:8.1.1(及以上)
查询分析是大数据要解决的核心问题之一,虽然大数据相关的处理引擎组件种类繁多,并提供了丰富的接口供用户使用,但相对传统数据库用户来说,SQL语言依然是使用最简单、最广泛和方便的一种接口。如果能在一个客户端中使用SQL语句操作不同的大数据组件,将极大提升使用各种大数据组件的效率。

GaussDB(DWS)的SQL On Anywhere,主要指对大数据的文件系统和与其他异构数据库的访问和交互,构筑起统一的大数据计算平台。大数据文件系统主要包括HDFS和OBS,其他异构数据库主要包括Oracle、Spark和其他DWS集群。

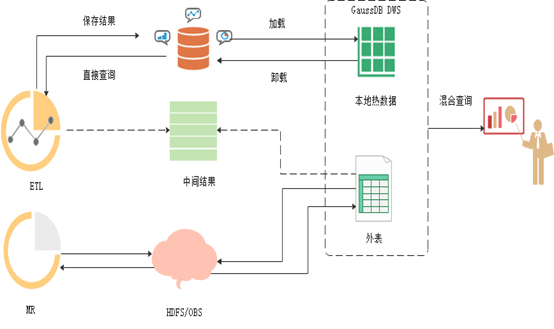
通过SQL On Anywhere特性可以实现与其他大数据组件和数据库互联互通访问,可以直接同时处理本地和HDFS/OBS上的数据集,甚至其他异构数据库的数据,而无需导入导出数据,将其分析能力从本地存储扩展到数据湖中,扩大GaussDB(DWS)的大数据分析的应用场景;
通过该特性可以帮助客户实现冷热数据分离,将使用频度更高的热数据存储在本地,而使用频度更低的冷数据存储在成本更低廉的共享存储HDFS或者DWS上,降低用户成本。
从应用场景来看,可以满足如下业务需求:
针对多数据源需要构建虚拟的统一数据仓库,实现多数据源联邦查询,跨数据仓库热数据和HDFS/OBS冷数据的复杂混合查询,需要提供一致的、熟悉的数据仓库操作体验。
满足低频的业务全数据的低成本低延迟即席查询。

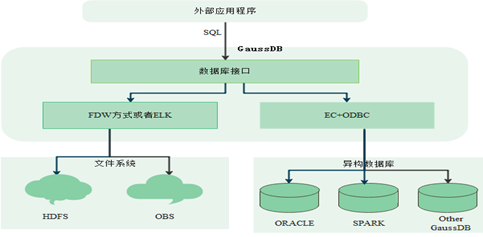
GaussDB(DWS)SQL On Anywhere针对大数据的文件系统的访问主要通过FDW或ELK机制(已停止演进)实现的,而跨数据库的访问主要通过EC+ODBC的方式实现的。
4.1 利用FDW访问HDFS/OBS数据
GaussDB(DWS)对存储在HDFS上的Hadoop或者OBS原生数据的访问,采用FDW(Foreign Data Wrapper)机制,也称外表机制。首先通过创建Foreign Data Server来定义对HDFS数据源或同构其他集群的连接信息;之后创建Foreign Table,用于在GaussDB A数据库内部系统表中,定义对应的HDFS数据源上Hadoop原生结构化数据表的结构或对应同构其他集群结构化数据表的结构。
例如读取hdfs上的数据,其流程如下:
1)建立一个hdfs_server,其中hdfs_fdw为数据库中存在的foreign data wrapper。
--创建hdfs_server。
postgres=# CREATE SERVER hdfs_server FOREIGN DATA WRAPPER HDFS_FDW OPTIONS
(address '10.146.187.231:8000,10.180.157.130:8000' ,
hdfscfgpath '/opt/hadoop_client/HDFS/hadoop/etc/hadoop',
type 'HDFS'
) ;
2)创建一个hdfs外表读取hdfs上的数据
CREATE FOREIGN TABLE region (
R_REGIONKEY INT4,
R_NAME TEXT,
R_COMMENT TEXT )
SERVER hdfs_server
OPTIONS(
FORMAT 'orc',
FOLDERNAME '/user/hive/warehouse/mppdb.db/region_orc11_64stripe/'
)
DISTRIBUTE BY roundrobin;
3)查询HDFS外表,例如:
select * from region limit 10;
目前外表支持与普通表进行关联查询,并支持多种文件存储格式,其支持的文件格式如下(不同版本能力可能存在差异,以官方文档为准):
| 文件系统 | 读支持的文件格式 | 写支持的文件格式 |
|---|---|---|
| HDFS | ORC、Parquet、TEXT、CSV | ORC、TEXT、CSV |
| OBS | ORC、Carbondata、Parquet、TEXT、CSV | ORC、TEXT、 |
4.2 通过ELK访问HDFS(已停止演进,不推荐)
ELK的方式类似于HAWQ,它是通过建立表空间为HDFS表空间,直接将数据存储和访问HDFS文件系统,目前只支持访问HDFS文件系统,而不支持访问OBS上的数据。首先通过创建HDFS表空间,然后会创建一个HDFS表,在创建时指定表空间为HDFS表空间,最后对HDFS表的操作如同普通表的操作,可进行插入修改删除数据。
以GaussDB数据库数据推到HDFS中
1)在数据库中创建HDFS表空间
CREATE TABLESPACE hdfs_table RELATIVE LOCATION ‘tmp/hdtest’
With (filesystem=’hdfs’,
address=’28.4.136.221:9000’,
cfgpath=’/opt/Huawei/bigdata/mppdb/hdfs_conf/zhndnrop/omm@HADOOP.COM/’,
storepath=’/tmp/test’);
2)数据库中创建HDFS表
CREATE TABLE abc(
zjxxlh char(20),
nbbsh char(20),
khwybh char(20),
zjlx char(20)
)WITH (orientation=orc) TABLESPACE tables_hdfs;
3)向表中插入数据
insert into abc select * from region10;
4.3 基于EC+ODBC的跨集群访问数据
GaussDB(DWS)支持通过 EC(全称Extension Connector)+ODBC统一访问其它大数据组件——将SQL发给其它大数据组件并接收执行结果,实现跨集群访问数据。目前EC+ODBC为用户提供了三种功能:SQL on Oracle、SQL on Spark和SQL on other GaussDB,分别用于连接Oracle数据库、Spark集群和其他GaussDB集群。
EC+ODBC的基本工作原理是:用户首先构建Data Source对象(其中包含目标库的一些连接信息和字符编码方式),然后用户获取该Data Source的使用权限,最后通过标准ODBC API连接目标库,发送SQL语句并获取执行结果。
为了方便使用,EC+ODBC为用户提供了统一的连接函数exec_on_extension(text, text)。其中,第一个参数为Data Source名称,第二个参数为发送的SQL语句,例如:
postgres=# SELECT * FROM exec_on_extension('ds_spark', 'select * from a;') AS (c1 int);

| 方式 | 数据源 | 优势 | 劣势 |
|---|---|---|---|
| EC+ODBC | ORACLE Spark MPPDB | 1.使用灵活 2.可以下推很复杂的查询到其他数据库 3.支持和本地多表join | 1.查询得到的数据和本地join须通过stream,存在较大网络开销,查询操作执行的节点存在单点瓶颈 2.配置繁琐,依赖odbc驱动,兼容性问题较多 |
| FDW | HDFS OBS | 1.支持多DN并发查询 2.支持和本地多表join等复杂查询 3.支持analyze收集统计信息 4.格式支持丰富,易扩展 | 1. 无法在一张外表,同时支持读和写 2. 不支持增量写,只支持覆盖写,不支持update和delete 3. 不支持和本地表join的复杂查询结果直接写入外表 |
| ELK | HDFS | 1. 支持多DN并发查询 2. 支持和本地多表join查询和写入 3. 支持analyze收集统计信息 4. 节点本地化效率相对比较高 5. 支持增量写,支持update和delete | 1. HDFS表空间方式要求HDFS集群与MPPDB集群有强依赖关系,不易于扩展 2. 格式支持有限,目前只支持ORC格式,并且只支持访问HDFS文件系统 3. 有可能会产生大量小文件 |


往期精彩回顾

 戳阅读原文,直达GaussDB(DWS)开发者平台
戳阅读原文,直达GaussDB(DWS)开发者平台
