





点个在看你最好看
数据同步是一个比较常见的开发场景。
其业务价值在于打通各个系统之间的壁垒,使数据能够互通,在一些商业合作或是借助第三方能力构建自身业务时比较有用。

同步可以是单向的,也可以是双向的。
例如,之前在做互联网电视业务时,由于商务上的合作,对接过各大主流视频媒体平台,将它们的数据单向同步到我们自己的系统使用。
也遇到过双向同步的场景,之间做过一段时间的零售业务,购买我们服务的商户习惯使用成熟的第三方ERP系统来管理订单库存,而我们平台的订单没有同步到第三方ERP系统,商户在第三方ERP系统的入库操作也没有同步到我们平台,对商户来说很不方便,为了提高商户体验,老板就决定打通自有系统和主流第三方ERP系统之间的数据流通,那这个就需要做双向的数据同步。
技术实施上,如果是公司内部的各个系统之间做数据同步,可以借助一些中间件,如Databus,直接在数据源层面进行数据同步。
但在与外部系统之间做数据同步时,出于权限安全等方面的考虑,一般不会直接在数据源层面进行,而是通过API接口来交互数据。
背景
最近遇到的场景是这样的,在某个业务需求上,为了缩短开发周期,聚焦业务价值,综合考虑后,团队选型了第三方技术服务。
这时就需要将业务数据同步给第三方,由于业务数据来源于多个内部系统,于是就开发了一套独立的系统来负责数据同步和服务代理。
方案设计
系统由两个子服务组成,API服务和数据同步服务。
API服务主要负责代理第三方服务以及接收业务数据变更通知。其中,代理第三方服务是为了更好的隐藏掉第三方服务的内部细节,向业务系统暴露相对友好的接入API。
数据同步服务负责聚合多个业务系统的数据并将数据同步给第三方系统,包括主动的全量同步和被动的增量同步。
各个服务之间的关系如下图
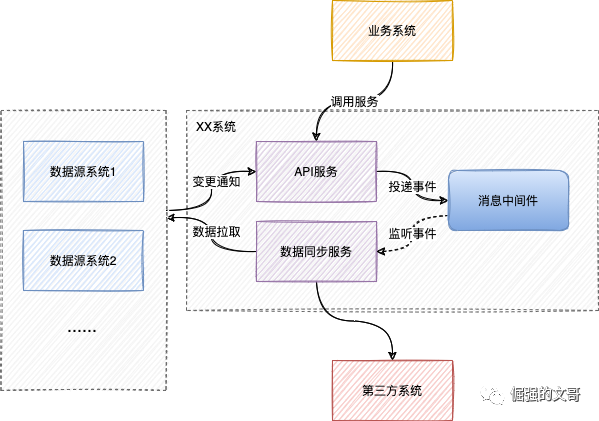
数据来源于内部的多个业务系统,API服务会接收这些业务系统的数据变更通知,将通知事件投递给消息中间件,数据同步服务监听事件并同步给第三方系统。
这里用到了消息中间件,考虑有3个好处:
(1)解耦接口服务和数据同步服务,避免相互影响。
(2)复用同步处理逻辑:对失败事件进行补充重试时,只需要封装数据变更事件丢给MQ,后面的消费逻辑都是一样的。
(3)异步处理:全量数据同步时,生产端取到数据后直接扔给MQ,消费端再使用线程池异步并发处理。
数据同步的重点在于如何保证数据的完整性,需要设计一套完善的机制来保证数据不会丢失。
为了保证数据的完整性,需要从3个方面来考虑。
(1)事件记录:接收事件并落库,事件一旦记录成功,就意味着事件永远不会丢失。
(2)失败补偿:由于各种原因,事件可能会处理失败,对于处理失败的事件需要补偿重试,必要时需人工介入排查。
(3)数据校验:数据的完整性对数据同步来说是个很重要的考量指标,有必要定时校验数据的完整性,核对差异数据。
1. 事件记录

API服务接收业务方的数据变更通知,先对通知事件进行记录,一旦记录成功,无论事件是否成功投递给消息中间件,均响应调用方通知成功。
数据同步服务监听消息中间件,接收事件进行处理,包括更新数据存档和将数据同步给第三方系统,任何一步出现异常都算失败,如果顺利,则修改事件状态为完成。
流程走完后,会存在两种情况,正常情况下,大部分事件可以处理成功,极少部分事件会处理失败,失败事件等待补偿重试。
事件乱序带来的问题和解决办法
变更事件有多种类型,新增事件、修改事件、删除事件(一般实现上删除是逻辑删除,所以删除也是一种修改)。
很多原因会导致接收事件的顺序是不确定的,处理事件的顺序就更难说了,这就会带来一些问题。
(1)多个修改乱序
假如修改1和修改2发生的顺序是修改1在前修改2在后,而实际处理的顺序恰好与之相反。
对于这种情况,如果逻辑上不做好处理,最新的数据就是最后更新的数据,显然与期望不符。
这个可以用乐观锁的思想去应对。
一个事件最终影响的是某条数据,数据自身是存在修改时间的,可以用这个时间作为数据的版本,更新的时候加上条件,预期待更新的数据版本号(这次更新时间) > 当前数据版本号(上次更新时间),这样无论事件的处理顺序如何,都不会污染到最新的数据了。
(2)新增和修改乱序
这种情况比上面情况稍微复杂一点,首先,业务里肯定是新增在前修改在后,如果乱序了,实际的处理顺序是先修改再新增,由于修改时还没数据,这次就是无效修改,而接下来的那次新增又成功了,最后的数据就不是最新数据了。
对于这种情况,我主要靠补充机制来处理。
在修改前会先去检查数据是否存在,如果不存在,当前处理算作失败,等待补偿重试,正常情况下,只要稍等一小会,迟到的新增很快就会被执行,数据也就存在了,那在下次重试时就可以处理成功了。
2. 失败补偿
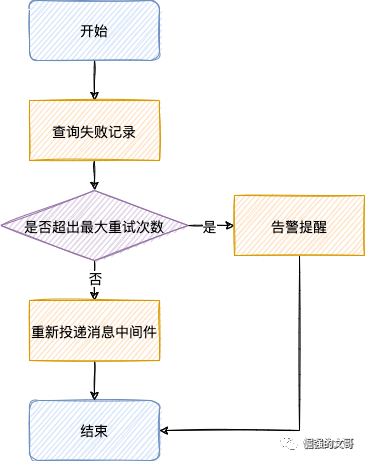
定时查询失败的事件,对失败的事件进行重试。
重试机制设计
重试主要考虑两点:
(1)重试次数:默认允许重试3次(可配置),超过3次则告警提示,人工介入排查。
(2)重试时间:每次重试等待时间翻倍,比如初始时间间隔为10s(可配置),第一次重试失败了,第二次重试就需要等待20s,以此类推。
重试逻辑直接复用通知数据变更的处理逻辑,即封装变更事件message,然后重新投递给消息中间件,复用数据变更事件的消费逻辑就行了。
3. 数据校验
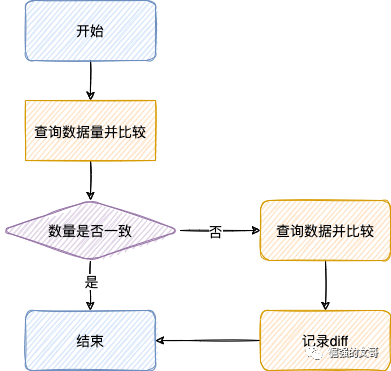
数据校验主要校验数据的完整性,比对数据存档与第三方数据的差异。
先校验数量,如果数量不一致,则查询全部数据进行diff。
如果业务数据量较大,可以根据某个业务字段先进行分组,保证各组的数据量在合理范围内,再进行diff。
上线流程
1. 数据同步服务上线
上线顺序是这样的,先接流增量数据同步,再执行全量数据同步,以保证数据不会丢失。
有个需要注意的地方,先接流的增量同步里有修改和删除,这时可能还没数据,所以这些事件会处理失败并进入重试队列,因为全量同步是需要时间的,可能重试期间数据都没就位,部分重试就会失败,所以就需要在全量同步完成后对之前所有失败的重试继续补偿。
2. 业务上线
(1)接入增量数据同步
在执行全量同步之前,要先接流增量数据同步,保证全量同步和增量同步之间没有时间间隙,避免丢失数据。
(2)接入API服务和灰度切流
新服务第一次上线,需要注意流量灰度接入,控制客诉风险。
以上是此篇全部内容,希望对你有所帮助,欢迎关注~
