




前言:
前段时间,在学习kingbase数据库的备份后,于是想着整理PostgreSQL备份,在整理过程中,发现kingbase是基于PostgreSQL发展而来,但又有所区别,接下来将PostgreSQL备份分享如下:
测试环境:
| 主机名称 | 操作系统 | PostgreSQL版本 |
|---|---|---|
| Node1 | CentOS 7.9 | PostgreSQL 16.2 |
第一部分:pg_dump 备份工具的使用方法
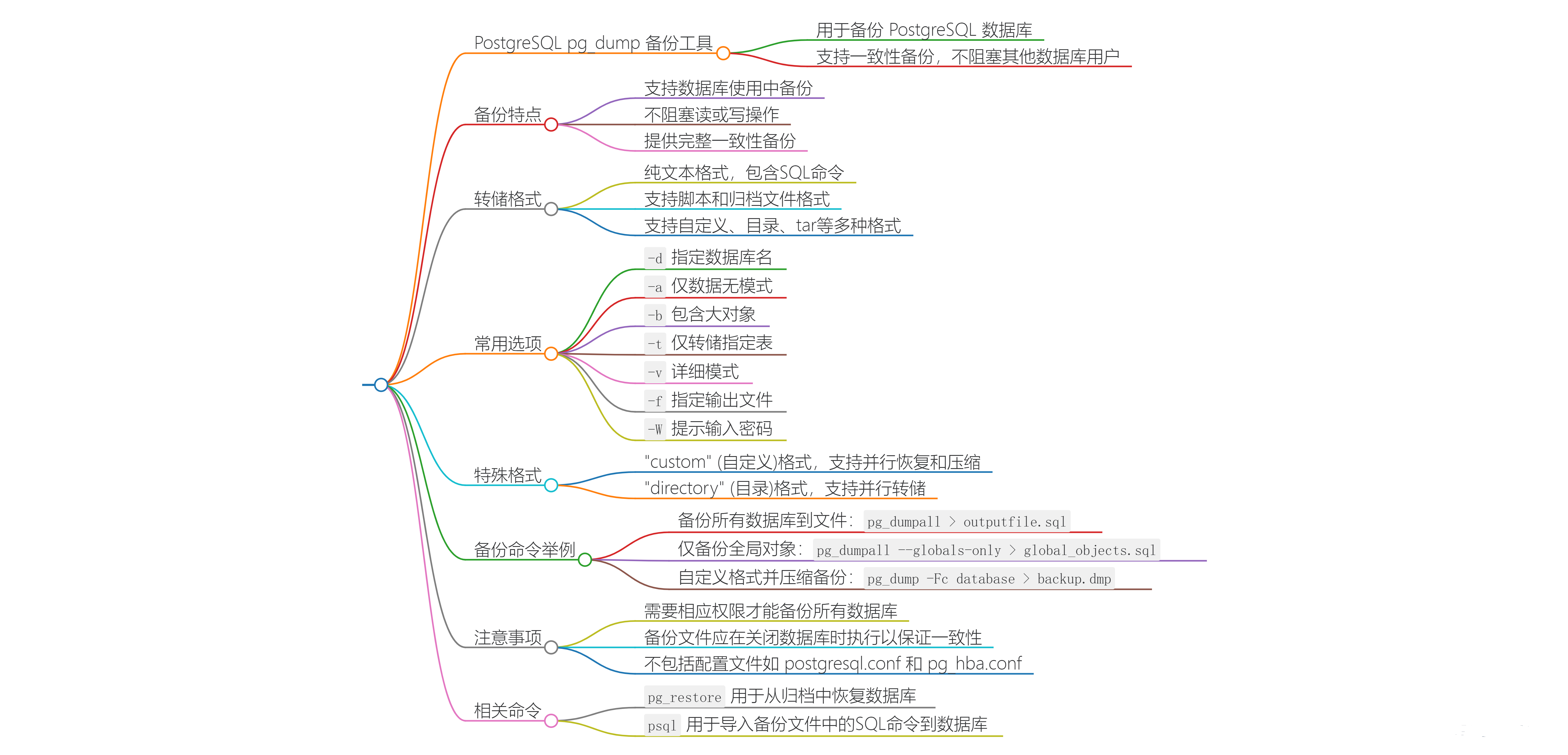
一.Pg_dump 工具功能概述
1.1、备份工具功能概述
pg_dump 是 PostgreSQL 数据库的一个强大的备份工具,它可以在数据库运行时进行备份,而不会影响其他用户对数据库的访问。pg_dump 可以将数据库备份为多种格式,包括纯文本脚本、自定义格式、目录格式和 tar 格式。这些备份文件可以用于恢复数据库,或者在不同的环境中迁移数据。
pg_dump 是 PostgreSQL 数据库的一个强大的备份工具,它可以在数据库运行时进行备份,而不会影响其他用户对数据库的访问。pg_dump 可以将数据库备份为多种格式,包括纯文本脚本、自定义格式、目录格式和 tar 格式。这些备份文件可以用于恢复数据库,或者在不同的环境中迁移数据。
1.2、使用场景
pg_dump 通常用于以下几种场景:
- 定期备份:为了防止数据丢失,定期使用 pg_dump 备份数据库是非常必要的。
- 迁移数据库:当需要将数据库从一个服务器迁移到另一个服务器时,pg_dump 可以生成备份文件,然后在目标服务器上使用 pg_restore 恢复。
- 灾难恢复:在发生数据损坏或丢失的情况下,可以使用 pg_dump 备份的文件来恢复数据。
pg_dump 通常用于以下几种场景:
- 定期备份:为了防止数据丢失,定期使用 pg_dump 备份数据库是非常必要的。
- 迁移数据库:当需要将数据库从一个服务器迁移到另一个服务器时,pg_dump 可以生成备份文件,然后在目标服务器上使用 pg_restore 恢复。
- 灾难恢复:在发生数据损坏或丢失的情况下,可以使用 pg_dump 备份的文件来恢复数据。
1.3、常见的 pg_dump 选项
- -h:指定数据库服务器的主机名或 IP 地址。
- -p:指定数据库服务器的端口号。
- -U:指定连接数据库时使用的用户名。
- -d:指定要备份的数据库名称。
- -F:指定导出文件格式,例如 c(自定义格式)、t(纯文本格式)等。
- -f:指定导出文件的路径和名称。
- -n:指定要导出的架构名称。
- -t:指定要导出的表名称。
- -h:指定数据库服务器的主机名或 IP 地址。
- -p:指定数据库服务器的端口号。
- -U:指定连接数据库时使用的用户名。
- -d:指定要备份的数据库名称。
- -F:指定导出文件格式,例如 c(自定义格式)、t(纯文本格式)等。
- -f:指定导出文件的路径和名称。
- -n:指定要导出的架构名称。
- -t:指定要导出的表名称。
1.4、pg_dump功能列表图
二、学习 pg_dump --help 使用方法
2.1、pg_dump --help使用方法
说明: 如果您需要了解如何使用 pg_dump 或查看所有可用的选项,可以在命令行中运行 pg_dump --help 命令。这将显示一个详细的帮助菜单,列出了所有可用的选项和它们的说明。
代码如下:
[postgres@node1 /]$ sys_dump --help
sys_dump 把一个数据库转储为纯文本文件或者是其它格式.
用法:
sys_dump [选项]... [数据库名字]
一般选项:
-f, --file=FILENAME 输出文件或目录名
-F, --format=c|d|t|p 输出文件格式(c为定制,d为目录,t为tar,p为明文(默认值))
-j, --jobs=NUM 执行多个并行任务进行备份转储工作
-v, --verbose 详细模式
-V, --version 输出版本信息,然后退出
-Z, --compress=默认不压缩 被压缩格式的压缩级别,压缩级别:0-9
--lock-wait-timeout=TIMEOUT 在等待表锁超时后操作失败
--no-sync 不用等待变化安全写入磁盘
-?, --help 显示此帮助, 然后退出
控制输出内容选项:
-a, --data-only 只转储数据,不包括模式
-b, --large-objects --blobs 在转储中包括大对象
-B, --no-large-objects --no-blobs 排除转储中的大型对象
-c, --clean 在重新创建之前,先清除(删除)数据库对象
-C, --create 在转储中包括命令,以便创建数据库
-e、 --extension=PATTERN 仅转储指定的扩展
-E, --encoding=ENCODING 转储以ENCODING形式编码的数据
-n, --schema=PATTERN 只导出指定的模式
-N, --exclude-schema=PATTERN 不导出指定的模式
-O, --no-owner 在明文格式中, 忽略恢复对象所属者
-s, --schema-only 只转储模式, 不包括数据
-S, --superuser=NAME 在明文格式中使用指定的超级用户名
-t, --table=PATTERN 只导出指定表
-T, --exclude-table=PATTERN 不导出指定表
-x, --no-privileges 不要转储权限 (grant/revoke)
--binary-upgrade 只能由升级工具使用
--column-inserts 以带有列名的INSERT命令形式转储数据
--disable-dollar-quoting 取消美元 (符号) 引号, 使用 SQL 标准引号
--disable-triggers 在只恢复数据的过程中禁用触发器
--enable-row-security 启用行安全性(只转储用户能够访问的内容)
--exclude table and children=PATTERN 不要转储指定的表,包括子表和分区表
--exclude-table-data=PATTERN 不导出特定表数据
--exclude-table-data-and-children=PATTERN 不要转储指定表的数据,包括子表和分区表
--extra-float-digits=NUM 覆盖extra_float_digits的默认设置
--if-exists 当删除对象时使用IF EXISTS
--include-foreign-data=PATTERN 在foreign上包含foreign表的数据,匹配PATTERN的服务器
--inserts 以INSERT命令,而不是COPY命令的形式转储数据
--load-via-partition-root 通过根表加载分区
--no-comments 不转储注释
--no-publications 不转储发布
--no-security-labels 不转储安全标签的分配
--no-subscriptions 不转储订阅
--no-table-access-method 不转储表访问方法
--no-tablespaces 不转储表空间分配信息
--no-toast-compression 不转储toast压缩方法
--no-unlogged-table-data 不转储没有日志的表数据
--on-conflict-do-nothing 将ON CONFLICT DO NOTHING添加到INSERT命令
--quote-all-identifiers 所有标识符加引号,即使不是关键字
--rows-per-insert=NROWS 每个插入的行数;意味着--inserts
--section=SECTION 备份命名的节 (数据前, 数据, 及 数据后)
--serializable-deferrable 等到备份可以无异常运行
--snapshot=SNAPSHOT 为转储使用给定的快照
--strict-names 要求每个表和(或)schema包括模式以匹配至少一个实体
--table-and-children=PATTERN 仅转储指定的表,包括子表和分区表
--use-set-session-authorization
使用 SESSION AUTHORIZATION 命令代替
ALTER OWNER 命令来设置所有权
联接选项:
-d, --dbname=DBNAME 对数据库 DBNAME备份
-h, --host=主机名 数据库服务器的主机名或套接字目录
-p, --port=端口号 数据库服务器的端口号
-U, --username=名字 以指定的数据库用户联接
-w, --no-password 永远不提示输入口令
-W, --password 强制口令提示 (自动)
--role=ROLENAME 在转储前运行SET ROLE
If no database name is supplied, then the PGDATABASE environment
variable value is used.
Report bugs to <pgsql-bugs@lists.postgresql.org>.
PostgreSQL home page: <https://www.postgresql.org/>
[postgres@node1 /]$
说明: 如果您需要了解如何使用 pg_dump 或查看所有可用的选项,可以在命令行中运行 pg_dump --help 命令。这将显示一个详细的帮助菜单,列出了所有可用的选项和它们的说明。
代码如下:
[postgres@node1 /]$ sys_dump --help
sys_dump 把一个数据库转储为纯文本文件或者是其它格式.
用法:
sys_dump [选项]... [数据库名字]
一般选项:
-f, --file=FILENAME 输出文件或目录名
-F, --format=c|d|t|p 输出文件格式(c为定制,d为目录,t为tar,p为明文(默认值))
-j, --jobs=NUM 执行多个并行任务进行备份转储工作
-v, --verbose 详细模式
-V, --version 输出版本信息,然后退出
-Z, --compress=默认不压缩 被压缩格式的压缩级别,压缩级别:0-9
--lock-wait-timeout=TIMEOUT 在等待表锁超时后操作失败
--no-sync 不用等待变化安全写入磁盘
-?, --help 显示此帮助, 然后退出
控制输出内容选项:
-a, --data-only 只转储数据,不包括模式
-b, --large-objects --blobs 在转储中包括大对象
-B, --no-large-objects --no-blobs 排除转储中的大型对象
-c, --clean 在重新创建之前,先清除(删除)数据库对象
-C, --create 在转储中包括命令,以便创建数据库
-e、 --extension=PATTERN 仅转储指定的扩展
-E, --encoding=ENCODING 转储以ENCODING形式编码的数据
-n, --schema=PATTERN 只导出指定的模式
-N, --exclude-schema=PATTERN 不导出指定的模式
-O, --no-owner 在明文格式中, 忽略恢复对象所属者
-s, --schema-only 只转储模式, 不包括数据
-S, --superuser=NAME 在明文格式中使用指定的超级用户名
-t, --table=PATTERN 只导出指定表
-T, --exclude-table=PATTERN 不导出指定表
-x, --no-privileges 不要转储权限 (grant/revoke)
--binary-upgrade 只能由升级工具使用
--column-inserts 以带有列名的INSERT命令形式转储数据
--disable-dollar-quoting 取消美元 (符号) 引号, 使用 SQL 标准引号
--disable-triggers 在只恢复数据的过程中禁用触发器
--enable-row-security 启用行安全性(只转储用户能够访问的内容)
--exclude table and children=PATTERN 不要转储指定的表,包括子表和分区表
--exclude-table-data=PATTERN 不导出特定表数据
--exclude-table-data-and-children=PATTERN 不要转储指定表的数据,包括子表和分区表
--extra-float-digits=NUM 覆盖extra_float_digits的默认设置
--if-exists 当删除对象时使用IF EXISTS
--include-foreign-data=PATTERN 在foreign上包含foreign表的数据,匹配PATTERN的服务器
--inserts 以INSERT命令,而不是COPY命令的形式转储数据
--load-via-partition-root 通过根表加载分区
--no-comments 不转储注释
--no-publications 不转储发布
--no-security-labels 不转储安全标签的分配
--no-subscriptions 不转储订阅
--no-table-access-method 不转储表访问方法
--no-tablespaces 不转储表空间分配信息
--no-toast-compression 不转储toast压缩方法
--no-unlogged-table-data 不转储没有日志的表数据
--on-conflict-do-nothing 将ON CONFLICT DO NOTHING添加到INSERT命令
--quote-all-identifiers 所有标识符加引号,即使不是关键字
--rows-per-insert=NROWS 每个插入的行数;意味着--inserts
--section=SECTION 备份命名的节 (数据前, 数据, 及 数据后)
--serializable-deferrable 等到备份可以无异常运行
--snapshot=SNAPSHOT 为转储使用给定的快照
--strict-names 要求每个表和(或)schema包括模式以匹配至少一个实体
--table-and-children=PATTERN 仅转储指定的表,包括子表和分区表
--use-set-session-authorization
使用 SESSION AUTHORIZATION 命令代替
ALTER OWNER 命令来设置所有权
联接选项:
-d, --dbname=DBNAME 对数据库 DBNAME备份
-h, --host=主机名 数据库服务器的主机名或套接字目录
-p, --port=端口号 数据库服务器的端口号
-U, --username=名字 以指定的数据库用户联接
-w, --no-password 永远不提示输入口令
-W, --password 强制口令提示 (自动)
--role=ROLENAME 在转储前运行SET ROLE
If no database name is supplied, then the PGDATABASE environment
variable value is used.
Report bugs to <pgsql-bugs@lists.postgresql.org>.
PostgreSQL home page: <https://www.postgresql.org/>
[postgres@node1 /]$
三、pg_dump 备份
3.1、将数据库 postgres 导出到 postgres.sql 文件中
代码如下:
[postgres@node1 /]$
[postgres@node1 /]$ pg_dump postgres >/postgres/backup/postgres.sql
[postgres@node1 /]$
查看导出文件:
代码如下:
[postgres@node1 /]$ ls /postgres/backup/postgres.sql
/postgres/backup/postgres.sql
[postgres@node1 /]$
代码如下:
[postgres@node1 /]$
[postgres@node1 /]$ pg_dump postgres >/postgres/backup/postgres.sql
[postgres@node1 /]$
查看导出文件:
代码如下:
[postgres@node1 /]$ ls /postgres/backup/postgres.sql
/postgres/backup/postgres.sql
[postgres@node1 /]$
3.2、将备份的 postgres.sql 文件导入到test数据库中
说明:
- 1、在导入 postgres.sql 前,需创建 test 数据库
- 2、在 test 数据库中导入 postgres.sql
代码如下:
[postgres@node1 /]$ createdb test
[postgres@node1 /]$
[postgres@node1 /]$ psql -dtest -f /postgres/backup/postgres.sql
SET
SET
SET
SET
SET
set_config
------------
(1 row)
...........................................
ALTER TABLE
ALTER TABLE
REVOKE
GRANT
GRANT
说明:
- 1、在导入 postgres.sql 前,需创建 test 数据库
- 2、在 test 数据库中导入 postgres.sql
代码如下:
[postgres@node1 /]$ createdb test
[postgres@node1 /]$
[postgres@node1 /]$ psql -dtest -f /postgres/backup/postgres.sql
SET
SET
SET
SET
SET
set_config
------------
(1 row)
...........................................
ALTER TABLE
ALTER TABLE
REVOKE
GRANT
GRANT
3.3、将 test 数据库备份成 dump 文件
代码如下:
[postgres@node1 /]$ pg_dump -Fc test > /postgres/backup/test.dmp
[postgres@node1 /]$ ls /postgres/backup/test.dmp
/postgres/backup/test.dmp
[postgres@node1 /]$
代码如下:
[postgres@node1 /]$ pg_dump -Fc test > /postgres/backup/test.dmp
[postgres@node1 /]$ ls /postgres/backup/test.dmp
/postgres/backup/test.dmp
[postgres@node1 /]$
3.4、将 test 数据库备份成目录格式的归档文件
代码如下:
[postgres@node1 /]$
[postgres@node1 /]$ pg_dump -Fd test -f /postgres/backup/dumpdir
[postgres@node1 /]$
[postgres@node1 /]$ ls /postgres/backup/dumpdir
4373.dat.gz 4380.dat.gz 4387.dat.gz 4394.dat.gz 4398.dat.gz 4405.dat.gz
4375.dat.gz 4381.dat.gz 4389.dat.gz 4395.dat.gz 4399.dat.gz toc.dat
4377.dat.gz 4383.dat.gz 4391.dat.gz 4396.dat.gz 4401.dat.gz
4379.dat.gz 4385.dat.gz 4393.dat.gz 4397.dat.gz 4403.dat.gz
[postgres@node1 /]$
代码如下:
[postgres@node1 /]$
[postgres@node1 /]$ pg_dump -Fd test -f /postgres/backup/dumpdir
[postgres@node1 /]$
[postgres@node1 /]$ ls /postgres/backup/dumpdir
4373.dat.gz 4380.dat.gz 4387.dat.gz 4394.dat.gz 4398.dat.gz 4405.dat.gz
4375.dat.gz 4381.dat.gz 4389.dat.gz 4395.dat.gz 4399.dat.gz toc.dat
4377.dat.gz 4383.dat.gz 4391.dat.gz 4396.dat.gz 4401.dat.gz
4379.dat.gz 4385.dat.gz 4393.dat.gz 4397.dat.gz 4403.dat.gz
[postgres@node1 /]$
3.5、将 5 个并行的工作任务转储一个数据库到一个目录格式的归档
代码如下:
[postgres@node1 /]$
[postgres@node1 /]$ pg_dump -Fd test -j 5 -f /postgres/backup/dumpdir_5个任务合并成1个目录
[postgres@node1 /]$ ls /postgres/backup/dumpdir_5个任务合并成1个目录 4373.dat.gz 4380.dat.gz 4387.dat.gz 4394.dat.gz 4398.dat.gz 4405.dat.gz
4375.dat.gz 4381.dat.gz 4389.dat.gz 4395.dat.gz 4399.dat.gz toc.dat
4377.dat.gz 4383.dat.gz 4391.dat.gz 4396.dat.gz 4401.dat.gz
4379.dat.gz 4385.dat.gz 4393.dat.gz 4397.dat.gz 4403.dat.gz
[postgres@node1 /]$
代码如下:
[postgres@node1 /]$
[postgres@node1 /]$ pg_dump -Fd test -j 5 -f /postgres/backup/dumpdir_5个任务合并成1个目录
[postgres@node1 /]$ ls /postgres/backup/dumpdir_5个任务合并成1个目录 4373.dat.gz 4380.dat.gz 4387.dat.gz 4394.dat.gz 4398.dat.gz 4405.dat.gz
4375.dat.gz 4381.dat.gz 4389.dat.gz 4395.dat.gz 4399.dat.gz toc.dat
4377.dat.gz 4383.dat.gz 4391.dat.gz 4396.dat.gz 4401.dat.gz
4379.dat.gz 4385.dat.gz 4393.dat.gz 4397.dat.gz 4403.dat.gz
[postgres@node1 /]$
3.6、备份名为 pu 开头,以 lic 结束的所有模式,并排除名为 server 的任何模式
代码如下:
[postgres@node1 /]$
[postgres@node1 /]$ pg_dump -n 'pu*lic' -n 'ser*lic' -N '*server*' test >/postgres/backup/schemaall.sql
[postgres@node1 /]$ ls /postgres/backup/schemaall.sql /postgres/backup/schemaall.sql
[postgres@node1 /]$
代码如下:
[postgres@node1 /]$
[postgres@node1 /]$ pg_dump -n 'pu*lic' -n 'ser*lic' -N '*server*' test >/postgres/backup/schemaall.sql
[postgres@node1 /]$ ls /postgres/backup/schemaall.sql /postgres/backup/schemaall.sql
[postgres@node1 /]$
3.7、备份除以 c 开头以外的所有数据库对象
代码如下:
[postgres@node1 /]$
[postgres@node1 /]$ pg_dump -T 'c*' test > /postgres/backup/test_c.sql [postgres@node1 /]$
[postgres@node1 /]$
[postgres@node1 /]$ ls /postgres/backup/test_c.sql
/postgres/backup/test_c.sql
[postgres@node1 /]$
代码如下:
[postgres@node1 /]$
[postgres@node1 /]$ pg_dump -T 'c*' test > /postgres/backup/test_c.sql [postgres@node1 /]$
[postgres@node1 /]$
[postgres@node1 /]$ ls /postgres/backup/test_c.sql
/postgres/backup/test_c.sql
[postgres@node1 /]$
3.8、要转储一个有混合大小写名称的 city 表
说明:要在-t 和相关开关中指定一个大写形式或混合大小写形式的名称,你需要双引用该名称,否则它会被折叠到小写形式 (请参见下面的Patterns)。但是双引号对于 shell 是特殊的,所以反过来它们必须被引用。
代码如下:
[postgres@node1 /]$
[postgres@node1 /]$ pg_dump -t "\"city"\" test > /postgres/backup/test_MixedCase.sql
[postgres@node1 /]$
说明:要在-t 和相关开关中指定一个大写形式或混合大小写形式的名称,你需要双引用该名称,否则它会被折叠到小写形式 (请参见下面的Patterns)。但是双引号对于 shell 是特殊的,所以反过来它们必须被引用。
代码如下:
[postgres@node1 /]$
[postgres@node1 /]$ pg_dump -t "\"city"\" test > /postgres/backup/test_MixedCase.sql
[postgres@node1 /]$
第二部分:pg_dumpall 备份工具的使用方法
一、pg_dumpall --help 工具的使用方法
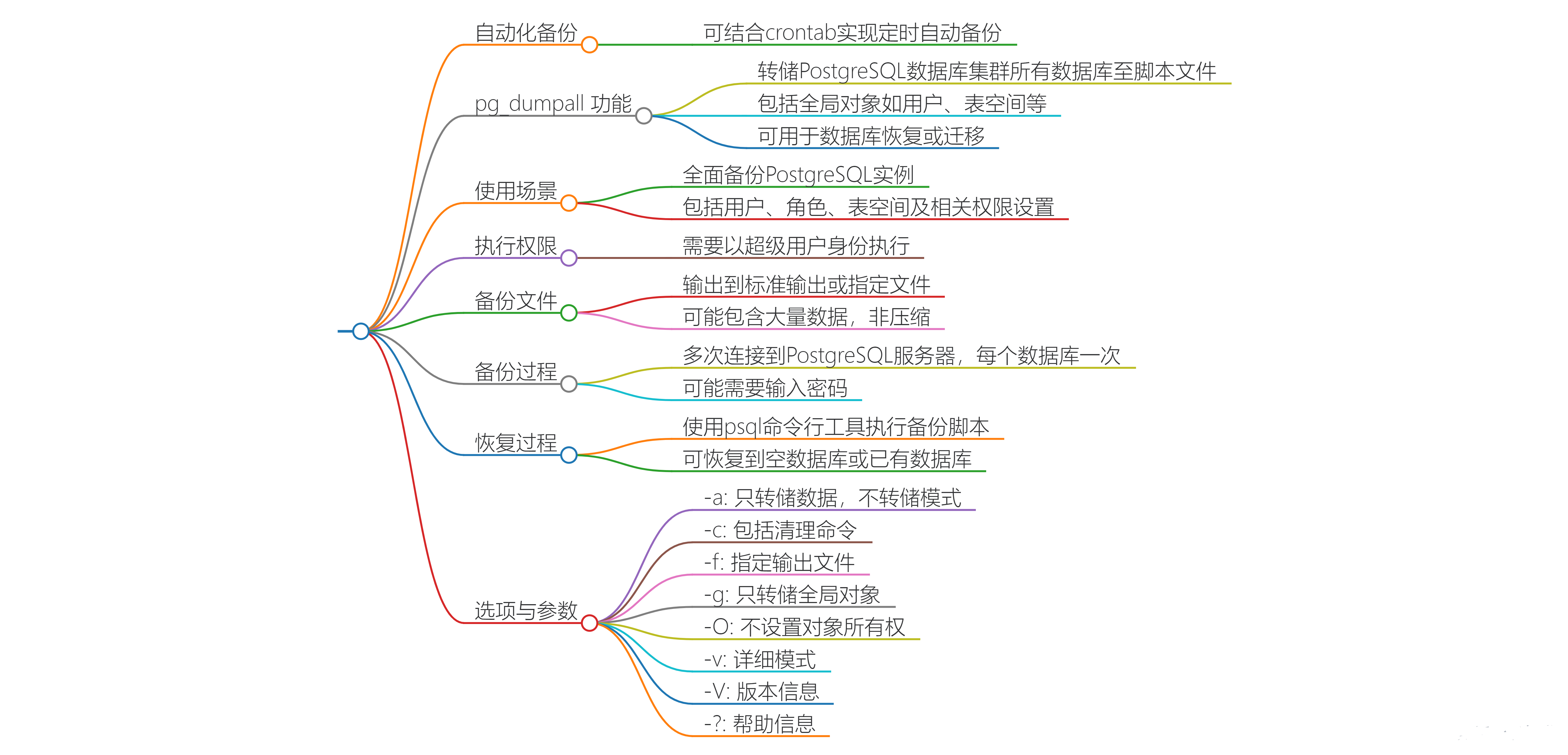
1.1、pg_dumpall 功能概述
pg_dumpall 是 PostgreSQL 数据库管理系统中的一个实用工具,它可以用来备份整个 PostgreSQL 数据库集群中的所有数据库。这个工具会将每个数据库以及集群中的全局对象(如角色和表空间)转换成一系列 SQL 命令,并存储在一个文件中。这个文件可以用来在另一个 PostgreSQL 实例中重建整个数据库集群。
pg_dumpall 是 PostgreSQL 数据库管理系统中的一个实用工具,它可以用来备份整个 PostgreSQL 数据库集群中的所有数据库。这个工具会将每个数据库以及集群中的全局对象(如角色和表空间)转换成一系列 SQL 命令,并存储在一个文件中。这个文件可以用来在另一个 PostgreSQL 实例中重建整个数据库集群。
1.2、pg_dumpall 功能列表图
二、pg_dumpall 查看帮助,学习使用方法
说明: 如果您需要了解如何使用 pg_dumpall 或查看所有可用的选项,可以在命令行中运行 pg_dump --help 命令。这将显示一个详细的帮助菜单,列出了所有可用的选项和它们的说明。
代码如下:
[postgres@node1 /]$ sys_dump --help
sys_dump 把一个数据库转储为纯文本文件或者是其它格式.
用法:
sys_dump [选项]... [数据库名字]
一般选项:
-f, --file=FILENAME 输出文件或目录名
-v, --verbose 详细模式
-V, --version 输出版本信息,然后退出
--lock-wait-timeout=TIMEOUT 在等待表锁超时后操作失败
-?, --help 显示此帮助, 然后退出
控制输出内容选项:
-a, --data-only 只转储数据,不包括模式
-B, --no-large-objects --no-blobs 排除转储中的大型对象
-c, --clean 在重新创建之前,先清除(删除)数据库对象
-E, --encoding=ENCODING 转储以ENCODING形式编码的数据
-g, --globals-only 只转储全局对象,不转储数据库
-O, --no-owner 在明文格式中, 忽略恢复对象所属者
-r, --roles-only 只转储角色,不转储数据库或表空间
-s, --schema-only 只转储模式, 不包括数据
-S, --superuser=NAME 在明文格式中使用指定的超级用户名
-t, --tablespaces-only 只转储表空间,不转储数据库或角色
-x, --no-privileges 不要转储权限 (grant/revoke)
--binary-upgrade 只能由升级工具使用
--column-inserts 以带有列名的INSERT命令形式转储数据
--disable-dollar-quoting 取消美元 (符号) 引号, 使用 SQL 标准引号
--disable-triggers 在只恢复数据的过程中禁用触发器
--exclude-database=PATTERN 排除名称与PATTERN匹配的数据库
--extra-float-digits=NUM 覆盖extra_float_digits的默认设置
--if-exists 当删除对象时使用IF EXISTS
--inserts 以INSERT命令,而不是COPY命令的形式转储数据
--load-via-partition-root 通过根表加载分区
--no-comments 不转储注释
--no-publications 不转储发布
--no-role-passwords 不要转储角色的密码
--no-security-labels 不转储安全标签的分配
--no-subscriptions 不转储订阅
--no-sync 不要等待更改安全写入磁盘
--no-table-access-method 不转储表访问方法
--no-tablespaces 不转储表空间分配信息
--no-toast-compression 不转储toast压缩方法
--no-unlogged-table-data 不转储没有日志的表数据
--on-conflict-do-nothing 将ON CONFLICT DO NOTHING添加到INSERT命令
--quote-all-identifiers 所有标识符加引号,即使不是关键字
--rows-per-insert=NROWS 每个插入的行数;意味着--inserts
--use-set-session-authorization 使用 SESSION AUTHORIZATION 命令代替
ALTER OWNER 命令来设置所有权
联接选项:
-d, --dbname=DBNAME 对数据库 DBNAME备份
-h, --host=主机名 数据库服务器的主机名或套接字目录
-p, --port=端口号 数据库服务器的端口号
-U, --username=名字 以指定的数据库用户联接
-w, --no-password 永远不提示输入口令
-W, --password 强制口令提示 (自动)
--role=ROLENAME 在转储前运行SET ROLE
If no database name is supplied, then the PGDATABASE environment
variable value is used.
Report bugs to <pgsql-bugs@lists.postgresql.org>.
PostgreSQL home page: <https://www.postgresql.org/>
[postgres@node1 /]$
说明: 如果您需要了解如何使用 pg_dumpall 或查看所有可用的选项,可以在命令行中运行 pg_dump --help 命令。这将显示一个详细的帮助菜单,列出了所有可用的选项和它们的说明。
代码如下:
[postgres@node1 /]$ sys_dump --help
sys_dump 把一个数据库转储为纯文本文件或者是其它格式.
用法:
sys_dump [选项]... [数据库名字]
一般选项:
-f, --file=FILENAME 输出文件或目录名
-v, --verbose 详细模式
-V, --version 输出版本信息,然后退出
--lock-wait-timeout=TIMEOUT 在等待表锁超时后操作失败
-?, --help 显示此帮助, 然后退出
控制输出内容选项:
-a, --data-only 只转储数据,不包括模式
-B, --no-large-objects --no-blobs 排除转储中的大型对象
-c, --clean 在重新创建之前,先清除(删除)数据库对象
-E, --encoding=ENCODING 转储以ENCODING形式编码的数据
-g, --globals-only 只转储全局对象,不转储数据库
-O, --no-owner 在明文格式中, 忽略恢复对象所属者
-r, --roles-only 只转储角色,不转储数据库或表空间
-s, --schema-only 只转储模式, 不包括数据
-S, --superuser=NAME 在明文格式中使用指定的超级用户名
-t, --tablespaces-only 只转储表空间,不转储数据库或角色
-x, --no-privileges 不要转储权限 (grant/revoke)
--binary-upgrade 只能由升级工具使用
--column-inserts 以带有列名的INSERT命令形式转储数据
--disable-dollar-quoting 取消美元 (符号) 引号, 使用 SQL 标准引号
--disable-triggers 在只恢复数据的过程中禁用触发器
--exclude-database=PATTERN 排除名称与PATTERN匹配的数据库
--extra-float-digits=NUM 覆盖extra_float_digits的默认设置
--if-exists 当删除对象时使用IF EXISTS
--inserts 以INSERT命令,而不是COPY命令的形式转储数据
--load-via-partition-root 通过根表加载分区
--no-comments 不转储注释
--no-publications 不转储发布
--no-role-passwords 不要转储角色的密码
--no-security-labels 不转储安全标签的分配
--no-subscriptions 不转储订阅
--no-sync 不要等待更改安全写入磁盘
--no-table-access-method 不转储表访问方法
--no-tablespaces 不转储表空间分配信息
--no-toast-compression 不转储toast压缩方法
--no-unlogged-table-data 不转储没有日志的表数据
--on-conflict-do-nothing 将ON CONFLICT DO NOTHING添加到INSERT命令
--quote-all-identifiers 所有标识符加引号,即使不是关键字
--rows-per-insert=NROWS 每个插入的行数;意味着--inserts
--use-set-session-authorization 使用 SESSION AUTHORIZATION 命令代替
ALTER OWNER 命令来设置所有权
联接选项:
-d, --dbname=DBNAME 对数据库 DBNAME备份
-h, --host=主机名 数据库服务器的主机名或套接字目录
-p, --port=端口号 数据库服务器的端口号
-U, --username=名字 以指定的数据库用户联接
-w, --no-password 永远不提示输入口令
-W, --password 强制口令提示 (自动)
--role=ROLENAME 在转储前运行SET ROLE
If no database name is supplied, then the PGDATABASE environment
variable value is used.
Report bugs to <pgsql-bugs@lists.postgresql.org>.
PostgreSQL home page: <https://www.postgresql.org/>
[postgres@node1 /]$
三、pg_dumpall 工具使用方法
3.1、备份所有数据库
代码如下:
[postgres@node1 /]$
[postgres@node1 /]$ pg_dumpall >/postgres/backup/pgall.sql
[postgres@node1 /]$
[postgres@node1 /]$ ll /postgres/backup
总用量 266
drwxrwxrwx 2 postgres postgres 6 5月 25 22:40 PackServer
-rw-rw-r-- 1 postgres postgres 2717995 6月 11 13:59 pgall.sql
代码如下:
[postgres@node1 /]$
[postgres@node1 /]$ pg_dumpall >/postgres/backup/pgall.sql
[postgres@node1 /]$
[postgres@node1 /]$ ll /postgres/backup
总用量 266
drwxrwxrwx 2 postgres postgres 6 5月 25 22:40 PackServer
-rw-rw-r-- 1 postgres postgres 2717995 6月 11 13:59 pgall.sql
3.2、备份 role 和 tablespace
代码如下:
[postgres@node1 /]$ pg_dumpall -g >/postgres/backup/pgtablespaceandroleall.sql
[postgres@node1 /]$
[postgres@node1 /]$ ll /postgres/backup
总用量 1298
drwxrwxrwx 2 postgres postgres 6 5月 25 22:40 PackServer
-rw-rw-r-- 1 postgres postgres 2717995 6月 11 13:59 pgall.sql
-rw-rw-r-- 1 postgres postgres 869 6月 11 13:56 pgtablespaceandroleall.sql
[postgres@node1 /]$
代码如下:
[postgres@node1 /]$ pg_dumpall -g >/postgres/backup/pgtablespaceandroleall.sql
[postgres@node1 /]$
[postgres@node1 /]$ ll /postgres/backup
总用量 1298
drwxrwxrwx 2 postgres postgres 6 5月 25 22:40 PackServer
-rw-rw-r-- 1 postgres postgres 2717995 6月 11 13:59 pgall.sql
-rw-rw-r-- 1 postgres postgres 869 6月 11 13:56 pgtablespaceandroleall.sql
[postgres@node1 /]$
3.3、只备份 role
代码如下:
[postgres@node1 /]$ pg_dumpall -r >/postgres/backup/pgroleall.sql
[postgres@node1 /]$
[postgres@node1 /]$ ll /postgres/backup
总用量 2300
drwxrwxrwx 2 postgres postgres 6 5月 25 22:40 PackServer
-rw-rw-r-- 1 postgres postgres 2717995 6月 11 13:59 pgall.sql
-rw-rw-r-- 1 postgres postgres 869 6月 11 13:56 pgtablespaceandroleall.sql
-rw-rw-r-- 1 postgres postgres 774 6月 11 13:57 pgroleall.sql
[postgres@node1 /]$
代码如下:
[postgres@node1 /]$ pg_dumpall -r >/postgres/backup/pgroleall.sql
[postgres@node1 /]$
[postgres@node1 /]$ ll /postgres/backup
总用量 2300
drwxrwxrwx 2 postgres postgres 6 5月 25 22:40 PackServer
-rw-rw-r-- 1 postgres postgres 2717995 6月 11 13:59 pgall.sql
-rw-rw-r-- 1 postgres postgres 869 6月 11 13:56 pgtablespaceandroleall.sql
-rw-rw-r-- 1 postgres postgres 774 6月 11 13:57 pgroleall.sql
[postgres@node1 /]$
3.4、只备份 tablespace
代码如下:
[postgres@node1 /]$ pg_dumpall -t >/postgres/backup/pgtablespaceall.sql
[postgres@node1 /]$
[postgres@node1 /]$ ll /postgres/backup
总用量 4500
drwxrwxrwx 2 postgres postgres 6 5月 25 22:40 PackServer
-rw-rw-r-- 1 postgres postgres 2717995 6月 11 13:59 pgall.sql
-rw-rw-r-- 1 postgres postgres 869 6月 11 13:56 pgtablespaceandroleall.sql
-rw-rw-r-- 1 postgres postgres 774 6月 11 13:57 pgroleall.sql
-rw-rw-r-- 1 postgres postgres 301 6月 11 13:57 pgtablespaceall.sql
[postgres@node1 /]$
代码如下:
[postgres@node1 /]$ pg_dumpall -t >/postgres/backup/pgtablespaceall.sql
[postgres@node1 /]$
[postgres@node1 /]$ ll /postgres/backup
总用量 4500
drwxrwxrwx 2 postgres postgres 6 5月 25 22:40 PackServer
-rw-rw-r-- 1 postgres postgres 2717995 6月 11 13:59 pgall.sql
-rw-rw-r-- 1 postgres postgres 869 6月 11 13:56 pgtablespaceandroleall.sql
-rw-rw-r-- 1 postgres postgres 774 6月 11 13:57 pgroleall.sql
-rw-rw-r-- 1 postgres postgres 301 6月 11 13:57 pgtablespaceall.sql
[postgres@node1 /]$
3.5、其他备份需求,可根据帮助参数搭配
第三部分:pg_dump与pg_dumpall的区别
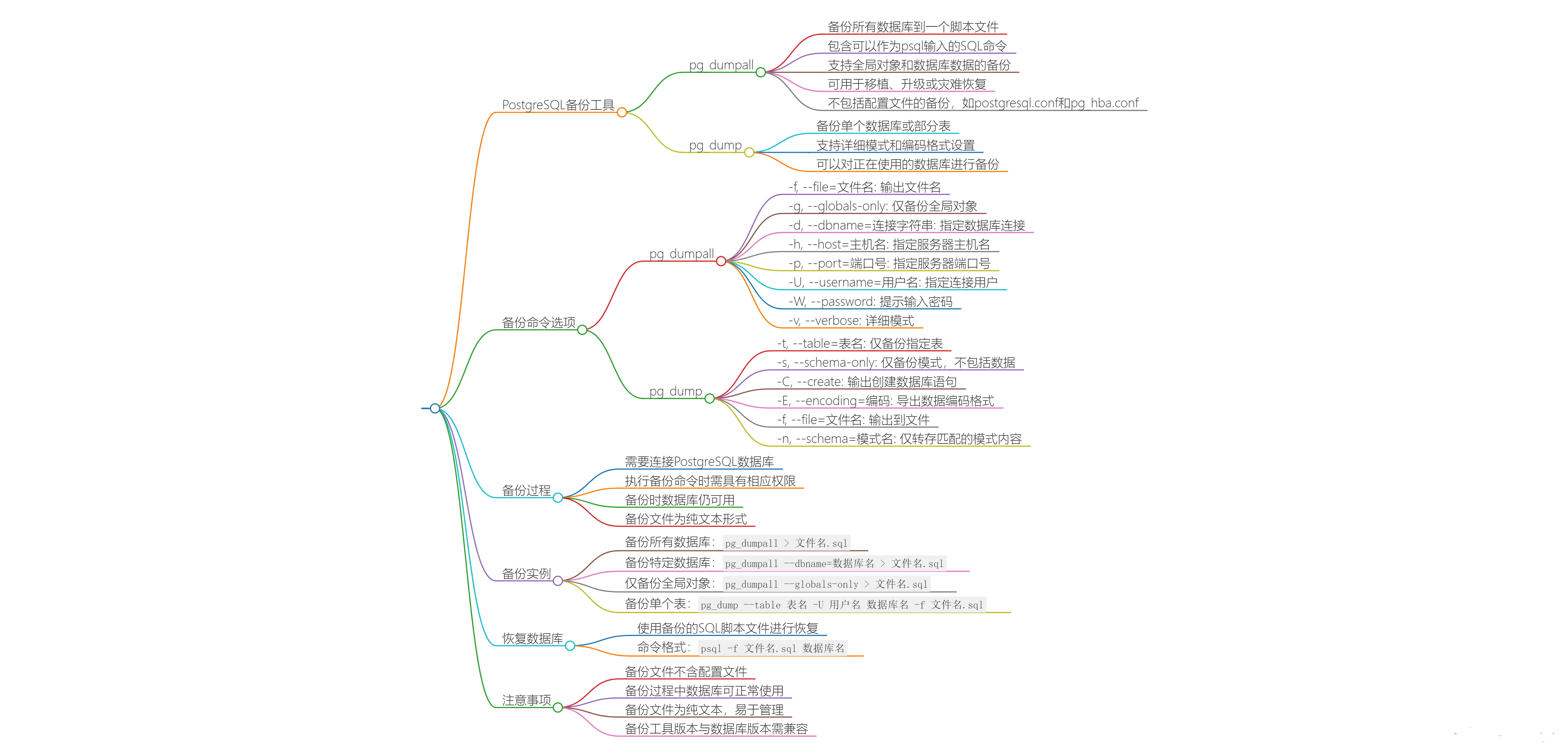
一、pg_dump 与 pg_dumpall 的 区别
1.1、pg_dump 和 pg_dumpall 的参数选项差异
pg_dump 和 pg_dumpall 是 PostgreSQL 数据库管理系统中用于备份的两个命令,它们在参数选项上有所不同,主要体现在备份范围和功能上。
pg_dump 和 pg_dumpall 是 PostgreSQL 数据库管理系统中用于备份的两个命令,它们在参数选项上有所不同,主要体现在备份范围和功能上。
1.2、pg_dump 的参数选项
- -a, --data-only:只转储数据,不转储数据定义。
- -n, --schema=PATTERN:只转储匹配 pattern 的模式,包括模式本身及其包含的所有对象。
- -s, --schema-only:只转储对象定义(模式),不转储数据。
- -t, --table=PATTERN:只转储名字匹配 pattern 的表。
- -T, --exclude-table=PATTERN:不转储匹配 pattern 模式的任何表。
- -F, --format=FORMAT:选择输出的格式,如自定义格式、目录格式、tar 格式或纯文本格式(默认)。
- -j, --jobs=NUM:使用指定数量的并行作业来进行备份,仅适用于目录输出格式。
- -Z, --compress=METHOD[:DETAIL]:指定压缩级别,仅适用于自定义和目录归档格式。
- --lock-wait-timeout=TIMEOUT:设置导出时等待获取表锁的最大时间。
- -a, --data-only:只转储数据,不转储数据定义。
- -n, --schema=PATTERN:只转储匹配 pattern 的模式,包括模式本身及其包含的所有对象。
- -s, --schema-only:只转储对象定义(模式),不转储数据。
- -t, --table=PATTERN:只转储名字匹配 pattern 的表。
- -T, --exclude-table=PATTERN:不转储匹配 pattern 模式的任何表。
- -F, --format=FORMAT:选择输出的格式,如自定义格式、目录格式、tar 格式或纯文本格式(默认)。
- -j, --jobs=NUM:使用指定数量的并行作业来进行备份,仅适用于目录输出格式。
- -Z, --compress=METHOD[:DETAIL]:指定压缩级别,仅适用于自定义和目录归档格式。
- --lock-wait-timeout=TIMEOUT:设置导出时等待获取表锁的最大时间。
1.3、pg_dumpall 的参数选项
- -a, --data-only:只转储数据,不转储数据定义。
- -g, --globals-only:只转储全局对象(用户和组),不转储数据库。
- -s, --schema-only:只转储模式(数据定义),不转储数据。
- -v, --verbose:打印进度信息。
- -W, --password:强制提示输入密码。
- pg_dumpall 在备份时无法指定备份数据的格式,即无法使用-Fc 这样的参数。此外,pg_dumpall 可以备份整个 PostgreSQL 集群,包括所有数据库和全局对象,而 pg_dump 则用于备份单个数据库或数据库中的特定对象。
- -a, --data-only:只转储数据,不转储数据定义。
- -g, --globals-only:只转储全局对象(用户和组),不转储数据库。
- -s, --schema-only:只转储模式(数据定义),不转储数据。
- -v, --verbose:打印进度信息。
- -W, --password:强制提示输入密码。
- pg_dumpall 在备份时无法指定备份数据的格式,即无法使用-Fc 这样的参数。此外,pg_dumpall 可以备份整个 PostgreSQL 集群,包括所有数据库和全局对象,而 pg_dump 则用于备份单个数据库或数据库中的特定对象。
1.4、pg_dump与pg_dumpall 对比图
第四部分:总结
PostgreSQL 的 pg_dump 和 pg_dumpall 是两个用于备份数据库的命令行工具,它们在功能和使用场景上有所不同。
- 备份范围:pg_dump 用于备份单个数据库,而 pg_dumpall 用于备份整个 PostgreSQL 集群,包括所有数据库和全局对象。
- 输出格式:pg_dump 支持多种输出格式,包括自定义格式,这些格式可能更适合大型数据库的快速备份和恢复;pg_dumpall 只支持纯文本 SQL 脚本格式。
- 灵活性:pg_dump 提供了更多的选项,如只备份数据或只备份结构、选择要备份的具体对象等;pg_dumpall 主要针对全面备份,提供较少的过滤选项。
- 使用场景:如果只需要备份单一数据库或特定对象,pg_dump 是更好的选择。它可以灵活地为每个数据库创建单独的备份文件,并且您可以选择备份的内容。
- 集群备份:如果希望备份整个 PostgreSQL 集群,并且想要包含全局对象和角色等,pg_dumpall 是更好的选择。这对于全量备份和集群恢复非常有用。
- 综上所述,选择 pg_dump 还是 pg_dumpall 取决于备份的需要。若只需备份单一数据库或特定对象,pg_dump 是更好的选择。若需要备份整个数据库服务器,包括所有数据库和全局级对象,pg_dumpall 更加合适。
PostgreSQL 的 pg_dump 和 pg_dumpall 是两个用于备份数据库的命令行工具,它们在功能和使用场景上有所不同。
- 备份范围:pg_dump 用于备份单个数据库,而 pg_dumpall 用于备份整个 PostgreSQL 集群,包括所有数据库和全局对象。
- 输出格式:pg_dump 支持多种输出格式,包括自定义格式,这些格式可能更适合大型数据库的快速备份和恢复;pg_dumpall 只支持纯文本 SQL 脚本格式。
- 灵活性:pg_dump 提供了更多的选项,如只备份数据或只备份结构、选择要备份的具体对象等;pg_dumpall 主要针对全面备份,提供较少的过滤选项。
- 使用场景:如果只需要备份单一数据库或特定对象,pg_dump 是更好的选择。它可以灵活地为每个数据库创建单独的备份文件,并且您可以选择备份的内容。
- 集群备份:如果希望备份整个 PostgreSQL 集群,并且想要包含全局对象和角色等,pg_dumpall 是更好的选择。这对于全量备份和集群恢复非常有用。
- 综上所述,选择 pg_dump 还是 pg_dumpall 取决于备份的需要。若只需备份单一数据库或特定对象,pg_dump 是更好的选择。若需要备份整个数据库服务器,包括所有数据库和全局级对象,pg_dumpall 更加合适。
